facebook怎么建设网站现在推广引流什么平台比较火
接上一篇高效训练,这一篇汇总下高效推理的方法。高效推理的两个主要优化目标是低延迟(快速得到推理结果)和高吞吐量(能同时处理很多请求),同时还要尽可能地少用资源(算力、存储、网络带宽)。
如果要说高效训练和高效推理哪个更重要,从产生的效益来说,应该说高效推理更重要,因为模型训练出来最终都是要用来推理使用的。整个生态产业中,训练基座大模型的就那么多家,训练出来更多时间也是对外提供推理服务;具体一个企业中,训练或者微调完模型后,多数时间也是在业务场景中使用推理。
高效推理如此重要,少不了学者们已经总结了综述文章,本文主要基于两篇综述文章,取其精华,从不同的分类角度全面概括高效推理的方法。目前Transformer结构基本一统大模型江山,多数高效推理方法均针对Transformer模型结构。
1
综述一
来自于2023年12月卡莱基梅隆大学的《Towards Efficient Generative Large Language Model Serving:A Survey from Algorithms to Systems》,是一个比较简洁版的综述,从机器学习系统研究的角度,分类如下:
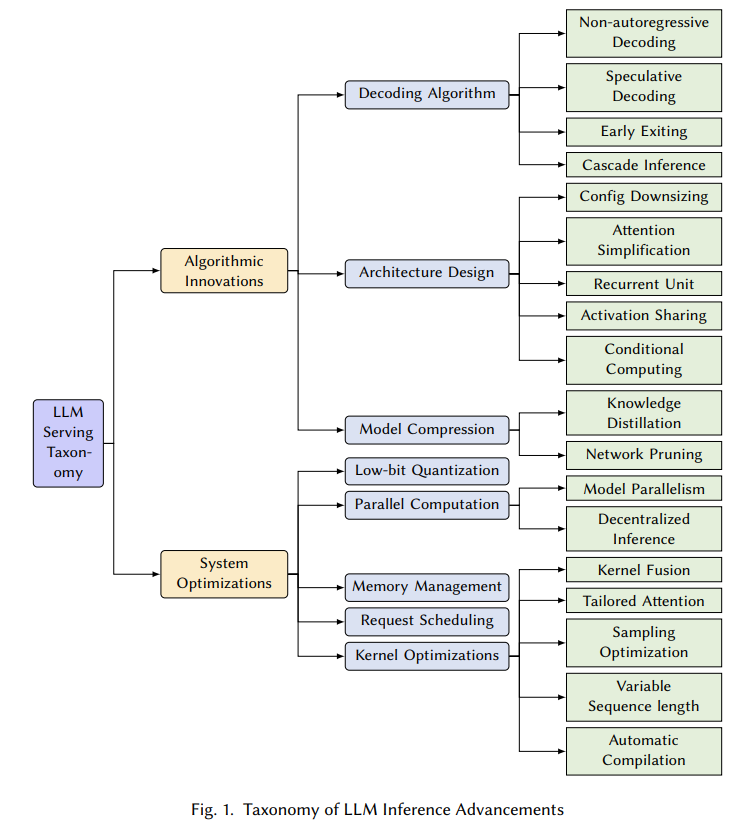
图1. LLM推理技术分类,来源[1]
总体分为模型算法、系统优化两个大类,由于第二篇综述在此基础上增加了数据维度,更全面,我们只从本综述挑选亮点分部分介绍。
1.1 Decoder算法优化
对Decoder算法优化的总结,如下图2。大模型中最常见的是只有解码器的Decoder-Only结构,解码器中最常见的是自回归模型,见图中(a),每一时刻由上一token预测下一token,每一次预测由于attention计算都要消耗大量的资源,优化Decoder就是要想办法减少资源消耗,提高计算效率,包括图中后面四种方法。
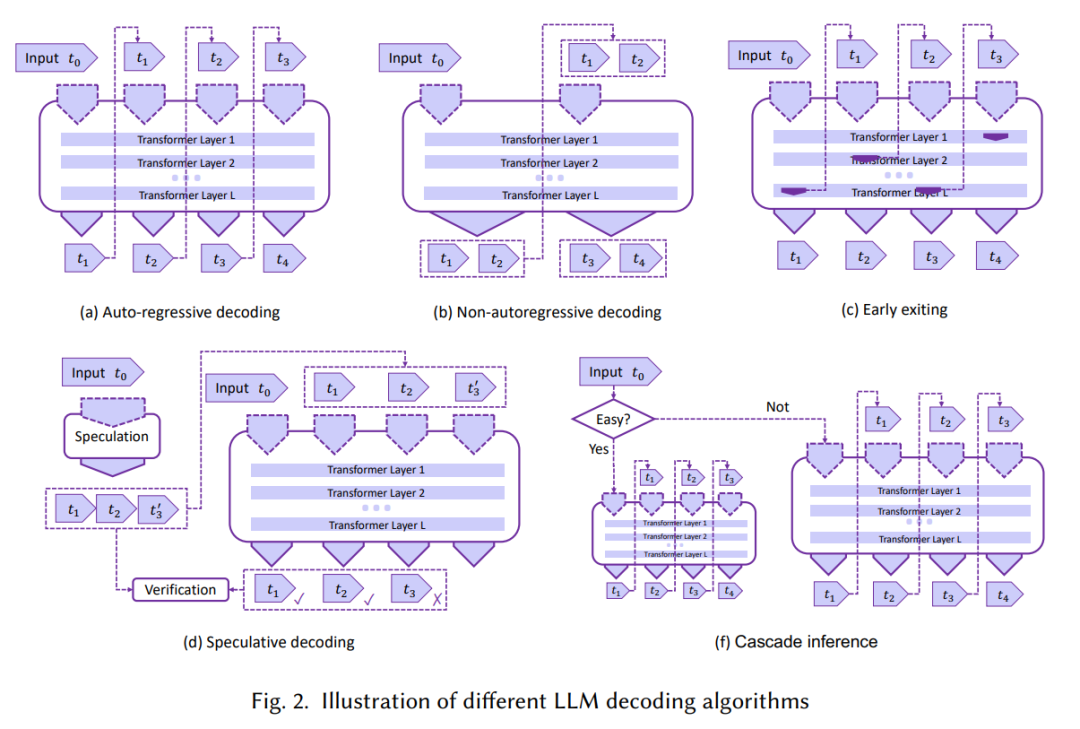
图2. 大模型Decoder算法分类,来源[1]
前排提示,文末有大模型AGI-CSDN独家资料包哦!
Non-autoregressive decoding
token不再是一个一个预测出来,一次预测多个或者并行预测多个tokens,该方法假设前后token之间有一定的条件独立性。当前该方法比自回归方法速度更快,但可靠性还是比自回归方法低。
Early exiting
每次预测下一个token不一定计算完整的Transformer层,根据不同的情况提前退出得到预测的token,以便减少计算量,但该方法可能导致预测准确率下降。
Speculative decoding
用一个小模型预测token(只是其中一种方式),这样出结果快,同时用原始大模型验证结果,不对就纠正,LLM计算量没有变,但验证的时候可以并行计算节约时间。
Cascade inference
将共享前缀的 KV Cache 存到共享内存中,读一次共享前缀的 KV Cache 即可,具有独特的后缀部分保持原来的计算逻辑,最终共享前缀和独特的后缀部分的各自的部分 attention 结果合并起来,得到最终的 attention 结果。
1.2 开源推理工具
市面上主要的开源推理工具,考察支持的指标包括:
**并行计算方式:**张量并行、流水线并行、计算资源是否offload到系统CPU或者内存上。
**Iteration Scheduling:**对要推理的数据如何有效的安排调度,从比较粗的Request粒度到更细的Iteration粒度,例如根据数据长度进行拼凑,先推理一批,剩下的再推理,尽量利用满GPU资源。
**Attention内核计算方式:**不同的计算方法,例如著名的Paged Attention。
**优先考虑的目标:**低延迟Low Latency还是高吞度High Throughput。
列表中目前最流行的应该是vLLM,不过大模型领域发展很快,各个工具支持的功能在迭代中会不断完善,这个统计很快会不准,而且新工具会不断出来。
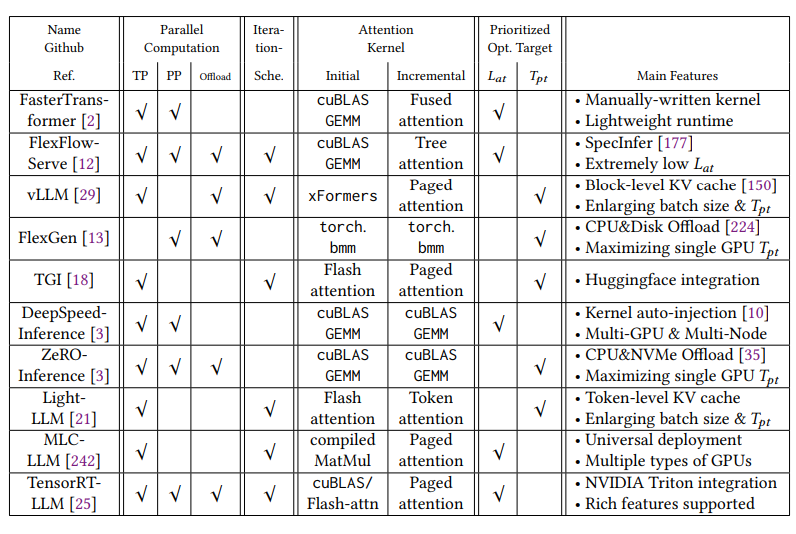
图3. 开源推理工具,来源[1]
2
综述二
接下来重点说综述二,时间上2024年7月也比综述一新,内容上更全面、更有时效性,来自清华大学等的《A Survey on Efficient Inference for Large Language Models》,本文仍然基于主流Transformer模型结构讨论。
2.1 方法分类
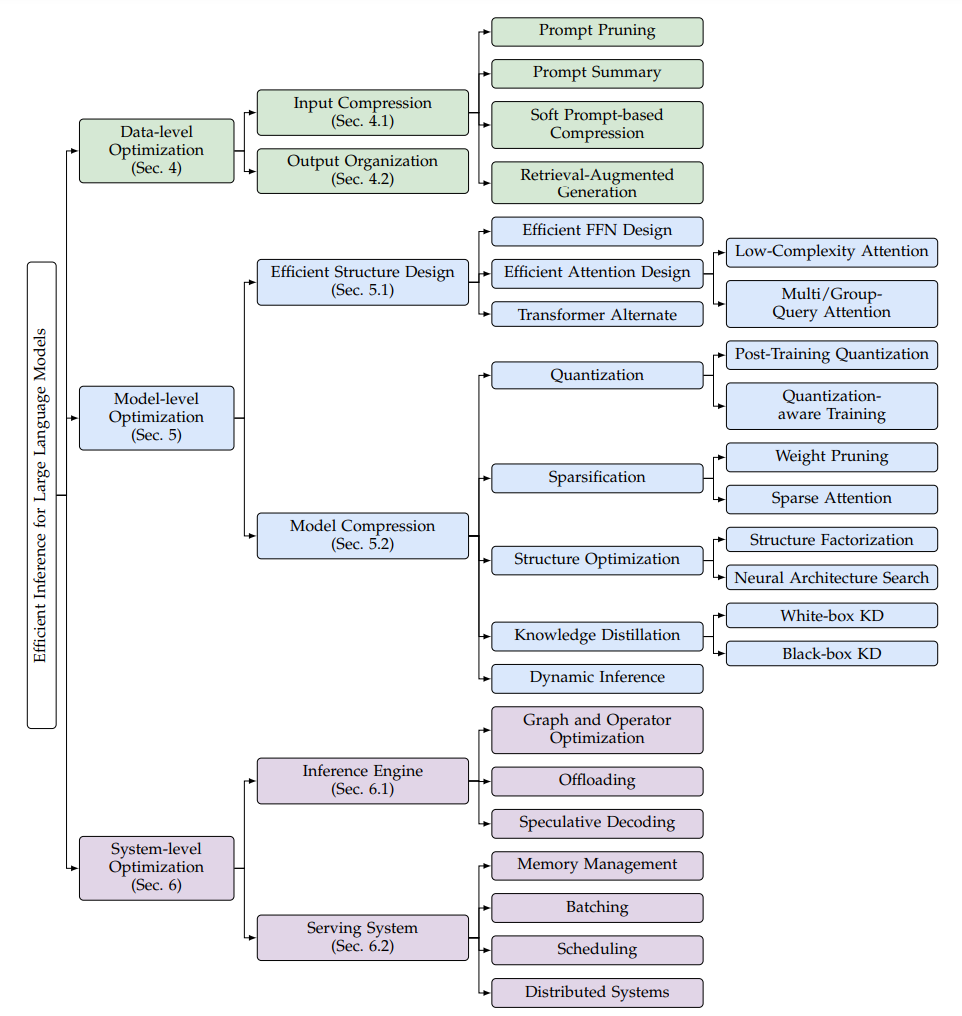
图4. LLM高效推理优化方法分类,来源[2]
这个分类方法很熟悉,和我们上一篇总结高效训练方法逻辑一样,或者说模型领域好多事情都是按照数据、模型、算力三个维度划分的,这里的Data-level包括输入数据的压缩和输出数据的优化组织,Model-level包括模型结构优化和模型压缩,System-level包括推理引擎和服务系统优化,和算力维度对应,如何有效利用算力。
2.2 整体视角
基于Transformer通过Decoder解码器一个一个token输出的方式,以及现在使用KV Cache的事实标准,推理可以分为两个阶段:
-
预填充阶段(Prefilling):使用初始token和KV Cache计算输出第一个token;
-
解码阶段(Decoding):不断更新KV Cache,由上一token预测下一token。
这样划分的原因是影响两个阶段效率的因素和效率表现不一样。按这个方式划分后,要提高推理效率,可以分解为如何提高获取第一个输出token效率、以及解码阶段的效率,评估指标也可以分解为如何降低第一个token输出的时间、后续token输出时间。
此外,整体上核心影响模型高效推理的三个因素是:
-
模型大小
-
Attention计算
-
Decoder解码方式
2.3 数据维度优化
2.3.1 输入压缩
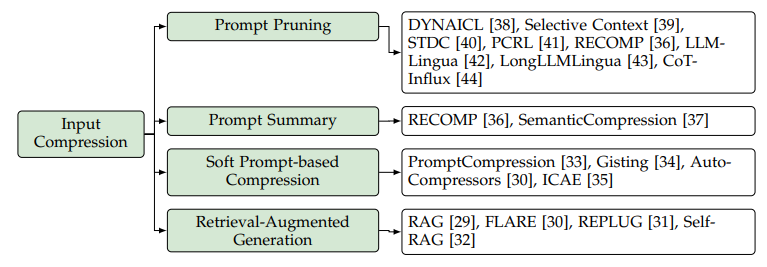
图5. 输入压缩,来源[2]
输入大模型进行推理的内容都叫Prompt提示词,输入数据压缩就是减少Prompt长度,从而降低模型的计算量。
-
**Prompt Pruning:**提示剪枝,剪掉无用或者重复的token、句子或者文档,例如使用小模型来计算内容的相似性、决定剪掉哪些内容。
-
**Prompt Summary:**提示摘要,对长的提示词内容提取核心的摘要,减少输入长度。
-
**Soft Prompt:**Soft Prompt指的是一个可学习的连续的token序列,通过不同的技术把原始的长的Fix Prompt变为短的Soft Prompt。
-
**RAG:**这个概念想必只要是关心大模型应用的同学都多少有了解,即把知识存入知识库,推理的时候从知识库检索相关的知识,再输入大模型推理使用,这样只输入需要的知识,也算是尽量减少无关输入。
2.3.2 输出结构优化
与其让大模型不加约束地输出,不如指定一些输出格式要求,更符合想要的内容,也能提高输出效率。
Skeleton-of-Thought (SoT)是最基础和重要的一个技术,分为两阶段,第一阶段让大模型输出问题的骨架,第二阶段让大模型扩展骨架中的每个点,然后把所有扩展后的内容组合起来得到最后的输出,这样输出的内容都是想要的,没有垃圾数据。
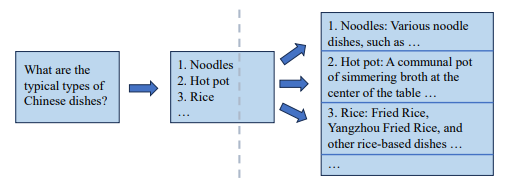
图6. SoT样例,来源[2]
SoT的一个例子如图6,问大模型典型的中国菜,第一步先列出名称,第二步再对第一步中每个名称进行扩展解释,这样输出结构化,清晰明了,没有无用的废话。
在SoT基础上还发展了其他技术SGD、APAR。目前一个很流行的推理框架SGLang,定义了领域相关的语言,可以分析不同生成内容之间的依赖,来控制最终的输出。SGLang的功能很多,不只是输出优化上,有兴趣的可以单独作为一个主题学习。
2.4 模型维度优化
2.4.1模型结构优化
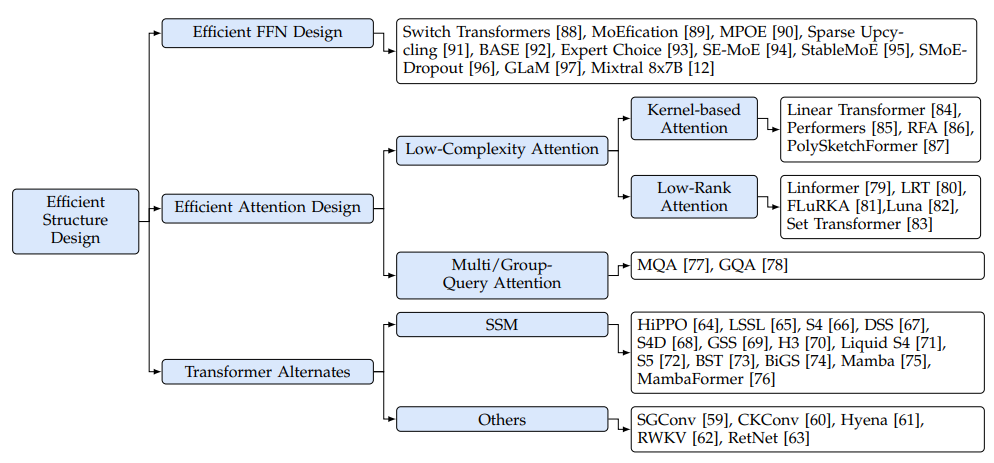
图7. 模型结构优化,来源[2]
大家一提到算法设计都会想到模型结构的设计,虽然大模型主体都使用Transformer,具体细节上还是有改进空间。Transformer内部主要包括Attention和FFN计算。
FFN优化主要使用Mixture-of-Experts (MoE) 方法,系统含多个专家模型,根据不同输入需求决定使用哪个专家模型。优化的领域包括如何构建专家模型、不同专家模型之间如何路由选择、如何训练MoE。
Attention优化有著名的Multi-Query Attention(MQA),然后发展到基于组的GQA,是工程中非常有效果的方法,后面我们会单独说一下。此外还有以降低Attention计算复杂度为目标的方法,包括基于核函数(把Q、K、V的计算映射到核函数)和低秩分解(K、V分解到更低的低秩空间)。
更换Transformer结构,按照历史发展规律来说,Transformer总有被替换的一天,所以探索新的网络结构也很有必要,当前主要有SSM和RWKV。
2.4.2 模型压缩

图8. 模型压缩,来源[2]
模型压缩在高效推理中有明显的效果,我们选量化和蒸馏重点说说,每一个都是大的知识点。
量化
把模型权重和激活从高精度比特位数转换到低精度,一般地,从训练后保存的FP16或者FP32精度量化为Int8、Int4或其他低精度,极大减少计算量和存储空间,关于不同精度可以参考我专门写的文章彻底理解系列之:FP32、FP16、TF32、BF16、混合精度
量化公式如下,其中S表示缩放因子,Z为量化后的零点,N为比特位数。
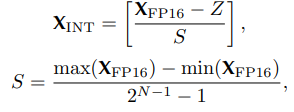
根据量化进行的时间,可分为模型训练后量化PTQ和训练中量化QAT,量化对象分为只量化模型权重、或者量化权重加激活。
蒸馏
把大的模型蒸馏为小模型,大模型当老师,小模型是学生,让小模型尽可能达到老师的水平,同时达到减少模型参数的目的,包括白盒知识蒸馏和黑盒知识蒸馏。
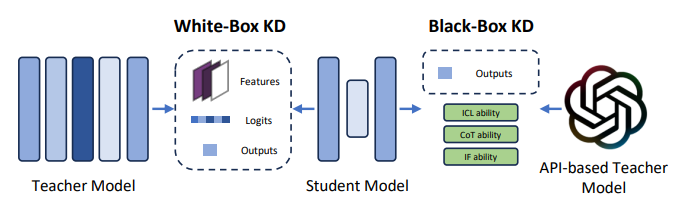
图9. 白盒和黑盒知识蒸馏,来源[2]
白盒蒸馏会进入老师模型结构和参数进行蒸馏,黑盒蒸馏不关心老师模型结构和参数,两种方法的学生模型都会通过训练学习老师模型的logits输出。以二分类问题为例简要说一下蒸馏原理,如果输入数据X,标签为0或者1,通过老师模型训练得到模型A,再次把输出X传入模型A,得到的其实是0到1之间的logits值,并不是0或者1,学生模型直接学习输入X和输出的logits,尽量去模仿老师模型。
**2.5 系统维度优化
**
2.5.1 推理引擎优化
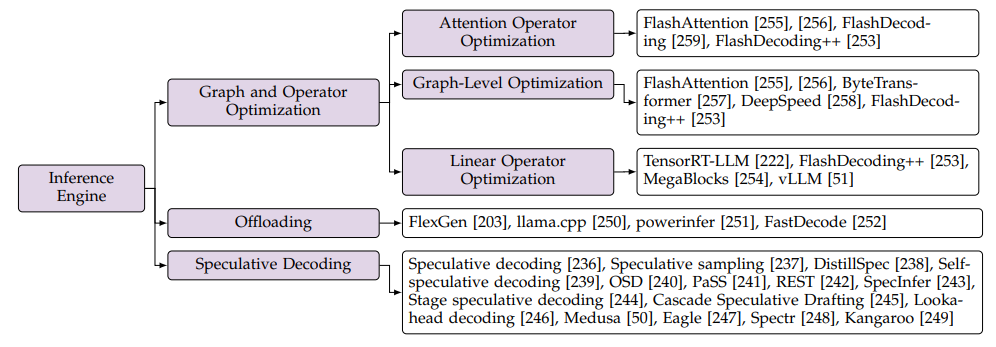
图10. 推理引擎优化,来源[2]
推理引擎优化是为了提高模型前向计算的速度,如图10,其包含了计算图和算子优化、Offloading和Speculative Decoding。综述一把Speculative Decoding放在了算法优化中,我觉得更合理,它主要体现了解码器算法的优化。Offloading比较好理解,是当GPU及其存储不够用时,部分任务转移使用系统的CPU和内存。我们重点看看图和算子优化。
图优化主要指算子融合,把多个算子融合为一个,优点:减少内存访问、减少算子加载时的开销、减少算子依赖从而提高计算并行度。例如FlashAttention把attention操作融合实现在一个单独内核中。
Attention算子优化,除了FlashAttention的算子融合,FlashDecoding致力于最大化Decoding计算的并行性。加之现在用上KV Cache技术后,加快了Attention计算,在Attention算子优化之外,线性算子运算花费的时间比Attention还多,所以优化线性算子很迫切。线性算子基本的实现方法是 General Matrix-Matrix Multiplication (GEMM),即矩阵相乘,其改进的一个方法是 General Matrix-Vector Multiplication (GEMV) ,矩阵和向量相乘,根据不同的形状具体优化,减少内存访问,提高数据复用率,让处理器尽可能满负荷地工作。
2.5.2 服务系统优化
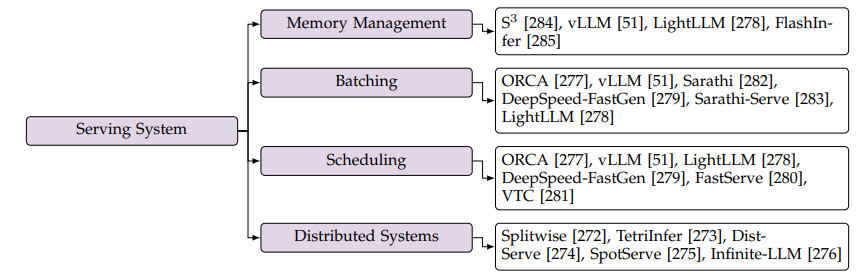
图11. 服务系统优化,来源[2]
服务系统优化的目标主要是提高异步处理的效率。
内存管理关键是对KV Cache的存储和使用优化,主要的方法是vLLM的PageAttention,借鉴分页管理内存的方法来管理KV Cache。
Continuous Batching是把多个请求根据其数据长短等特点组装到一个batch里,缩短计算时间。例如把长的Prefilling请求数据切分开,和多个短的Decoding请求数据放在一个batch里。
Scheduling指的是如何有效安排收到的推理请求,提高系统的吞吐量,比如最简单的先到先处理,或者文章中提到的DeepSpeed-FastGen优先处理Decoding请求等,以及其他各种方法。
分布式系统是传统IT比较成熟的思想和方案,大模型中主要特点在于如何对多GPU进行分布式计算,另外模型推理可分为Prefilling和Decoding阶段,二者可以解耦然后进行粒度更细的分布式计算,这个也是当前比较热门的课题。
除了以上所有优化方案之外,还有硬件加速方案,不是本文讨论重点。
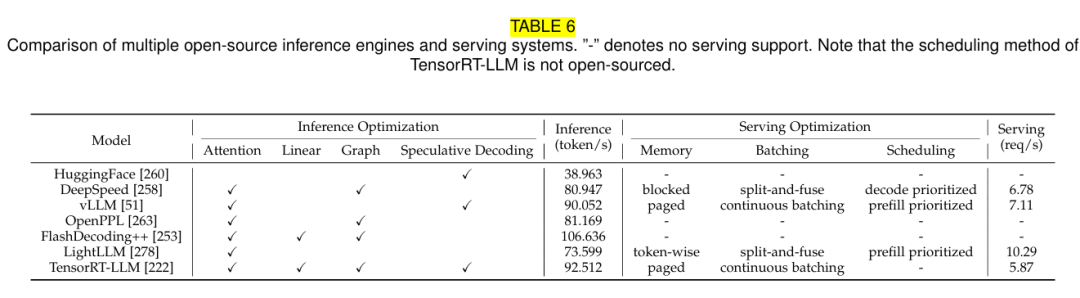
最后是常见推理工具优化功能的支持对比和性能对比。
3
一点体会
在高效训练一文中,我们解释了训练和推理阶段的不同,高效处理的方法也不一样,但训练的前向计算和推理绝大部分是相同的,所以二者都有可以共同使用的方法,比如:张量并行、Flash Attention、算子融合、低精度等。
综述一、二中有的方法偏理论,在工程中不一定好实践,比如基于核函数降低空间维度的attention。实际应用中还是有倾向性使用一些好实现并且效果明显的,或者推理工具已经现成支持的,本节对使用频率高的方法再抽出来说说。
KV Cache绝对是数一数二重要的方法,通过Cache存储KV值,大大减少重复计算量,节约计算时间。在讲多头注意力的文章彻底理解Transformer自注意力、多头注意力MHA、KV Cache、MQA、GQA时,有朋友建议增加解释为什么是KV Cache,不是Q Cache、QK Cache或者其他Cache,在此完善解释一下。t时刻计算attention时,公式如下:
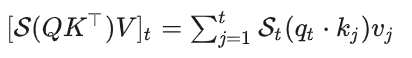
其中S是softmax,可看出只用到了t时刻的Q,但用到了t时刻以及之前的所有K和V,所以之前的K、V需要Cache,而Q每次使用当前时刻的,不需要Cache。
量化是比较独立且好实施的方法,各种精度的量化技术比较成熟,并且量化后使用的算力和存储减少都能看到立竿见影的效果。
其他方法,看各种工具的支持情况,选择适合自己场景的就是最好的。
