领域网站建设seo相关岗位
今天看的论文是这篇
主要提出了传统优先级经验回放(PER)在复杂交通场景中效率低下,使用二叉树存储样本,导致大规模样本时计算复杂度高。而且不丢弃样本,造成存储空间浪费。
双重经验池:
为了解决以上问题,文章提出了双重经验池。分为普通经验池(随机存储交互数据 (s_t, a_t, r, s_{t+1}),用于基础训练。)
和优先经验池(仅存储高价值样本(需满足:奖励≥历史平均奖励且>奖励中位数))。
并执行异优训练:优先池以一定概率启动训练(如10%),避免过拟合并加速收敛。
动态训练周期
为了解决固定训练周期在交通流变化时效率低(如车辆少时过度训练)。提出了动态训练周期
动态生成每轮训练周期(epoch),公式如下:(这里的训练周期动态我是第一次见)
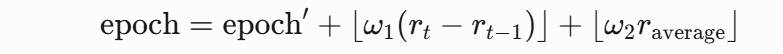
动态系数
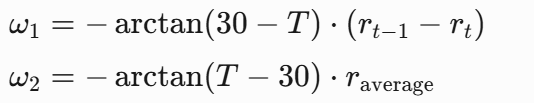
这样设计能够使早期车少时侧重即时奖励变化(ω1权重高),后期车多时侧重历史表现(ω2权重高)。确实妙啊。
还有加入了之前别的论文也研究过的压力奖励:
奖励函数设计:
定义车道压力:Pi=Nin−Nout(入站车辆数 - 出站车辆数)。
奖励:ri=−Pi,总奖励 R(st,at)=∑ri。
这样能够协调车量通过最小化压力路口实现缩短车辆平均通行时间,提升路口吞吐量。
论文总结:DERLight通过双经验回放提升采样效率,结合动态周期训练适应环境变化,以压力驱动的奖励函数优化交通流。实验证明其在降低通行时间、提升吞吐量和加速收敛方面显著优于主流算法(如CoLight、PressLight),且具备跨领域应用潜力。
个人看法:
我觉得这个压力奖励还有很大的研究空间。这个动态周期确实我之前居然没想到过(太菜了),作者给我提供了一个新的思路,核心双重经验池也是很大的思路。(能不能多重)(动态经验池)。
主要代码大概
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
import mathclass DQN(nn.Module):"""DQN网络结构 (评估网络和目标网络)"""def __init__(self, state_size, action_size):super(DQN, self).__init__()self.fc1 = nn.Linear(state_size, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, action_size)self.relu = nn.ReLU()def forward(self, state):x = self.relu(self.fc1(state))x = self.relu(self.fc2(x))return self.fc3(x)class DERLight:"""DERLight交通灯控制算法实现"""def __init__(self, state_size, action_size):# 算法参数设置self.state_size = state_sizeself.action_size = action_sizeself.memory_capacity = 10000 # 经验池容量self.batch_size = 32self.gamma = 0.8 # 折扣因子self.epsilon = 0.8 # 初始探索率self.epsilon_min = 0.2self.epsilon_decay = 0.995self.target_update_freq = 5 # 目标网络更新频率self.priority_prob = 0.1 # 优先经验池启动概率# 创建双经验池self.memory_D = deque(maxlen=self.memory_capacity) # 普通经验池self.memory_D_prime = deque(maxlen=self.memory_capacity) # 优先经验池# 创建DQN网络self.eval_net = DQN(state_size, action_size)self.target_net = DQN(state_size, action_size)self.target_net.load_state_dict(self.eval_net.state_dict())self.optimizer = optim.Adam(self.eval_net.parameters(), lr=0.001)self.loss_func = nn.MSELoss()# 奖励相关参数self.rewards = [] # 奖励历史self.epoch = 1000 # 初始训练周期self.r_median = None # 奖励中位数self.r_average = 0 # 奖励平均值def compute_pressure(self, state):"""计算车道压力 (核心公式1)"""# 状态向量包含各车道的车辆数 [in_N, out_N, in_S, out_S, in_E, out_E, in_W, out_W]pressures = []for i in range(0, len(state), 2):n_in = state[i]n_out = state[i+1]pressures.append(n_in - n_out)return pressuresdef compute_reward(self, state):"""计算压力奖励 (核心公式2)"""pressures = self.compute_pressure(state)total_reward = -sum(pressures) # 总奖励为压力总和的负值return total_rewarddef dynamic_epoch(self, r_t, r_t_minus1):"""动态训练周期计算 (核心公式6-8)"""# 更新历史奖励记录self.rewards.append(r_t)self.r_average = np.mean(self.rewards)self.r_median = np.median(self.rewards) if self.rewards else 0# 模拟时间 (0-60分钟)T = len(self.rewards) % 60# 计算动态系数 (公式7-8)w1 = -math.atan(30 - T) * (r_t_minus1 - r_t)w2 = -math.atan(T - 30) * self.r_average# 更新训练周期 (公式6)epoch_update = w1 + w2self.epoch = max(100, min(2000, self.epoch + int(epoch_update)))return self.epochdef store_experience(self, state, action, reward, next_state, done):"""存储经验到双经验池"""# 存储到普通经验池Dself.memory_D.append((state, action, reward, next_state, done))# 判断是否为优先经验 (条件: 奖励≥平均奖励且>中位数)if (reward >= self.r_average) and (reward > self.r_median):self.memory_D_prime.append((state, action, reward, next_state, done))def sample_experience(self, memory):"""从经验池采样"""if len(memory) < self.batch_size:return Nonebatch = random.sample(memory, self.batch_size)states, actions, rewards, next_states, dones = zip(*batch)return (torch.FloatTensor(states),torch.LongTensor(actions),torch.FloatTensor(rewards),torch.FloatTensor(next_states),torch.FloatTensor(dones))def choose_action(self, state):"""ε-贪婪策略选择动作"""if np.random.rand() <= self.epsilon:return random.randrange(self.action_size)else:state = torch.FloatTensor(state).unsqueeze(0)q_values = self.eval_net(state)return torch.argmax(q_values).item()def update_network(self, sample, is_priority=False):"""更新网络参数"""if sample is None:returnstates, actions, rewards, next_states, dones = sample# 计算当前Q值q_eval = self.eval_net(states).gather(1, actions.unsqueeze(1))# 计算目标Q值q_next = self.target_net(next_states).detach()q_target = rewards + (1 - dones) * self.gamma * q_next.max(1)[0].view(-1, 1)# 计算损失并更新网络loss = self.loss_func(q_eval, q_target)self.optimizer.zero_grad()loss.backward()self.optimizer.step()# 动态调整探索率if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decaydef train(self, env, episodes=1000):"""DERLight训练过程"""for episode in range(episodes):state = env.reset()total_reward = 0r_t_minus1 = 0 # 上一时间步的奖励while True:# 选择并执行动作action = self.choose_action(state)next_state, done = env.step(action)# 计算压力奖励reward = self.compute_reward(state)total_reward += reward# 存储经验self.store_experience(state, action, reward, next_state, done)# 从普通经验池D采样并训练sample_D = self.sample_experience(self.memory_D)self.update_network(sample_D)# 以一定概率从优先经验池D'采样并训练if np.random.rand() < self.priority_prob and self.memory_D_prime:# 计算动态训练周期self.dynamic_epoch(reward, r_t_minus1)# 使用动态周期进行多次训练for _ in range(min(5, self.epoch // 100)):sample_D_prime = self.sample_experience(self.memory_D_prime)self.update_network(sample_D_prime, is_priority=True)# 更新目标网络if episode % self.target_update_freq == 0:self.target_net.load_state_dict(self.eval_net.state_dict())# 更新状态和奖励state = next_stater_t_minus1 = rewardif done:print(f"Episode: {episode}, Total Reward: {total_reward:.2f}, Epsilon: {self.epsilon:.3f}, Epoch: {self.epoch}")breakclass TrafficSimulationEnv:"""简化的交通模拟环境 (用于演示)"""def __init__(self, state_size=8):self.state_size = state_sizeself.max_steps = 100def reset(self):self.step_count = 0# 随机生成初始状态: [in_N, out_N, in_S, out_S, in_E, out_E, in_W, out_W]self.state = np.random.randint(0, 20, size=self.state_size)return self.statedef step(self, action):# 简化状态转移逻辑self.step_count += 1# 根据动作更新车流# 实际实现应使用更复杂的交通流模型next_state = self.state.copy()# 减少进入车辆 (模拟车辆离开)for i in [0, 2, 4, 6]: # 入口车道next_state[i] = max(0, next_state[i] - np.random.randint(1, 4))# 增加新车辆 (概率性)for i in range(len(next_state)):if np.random.rand() < 0.3:next_state[i] += np.random.randint(1, 3)# 检查结束条件done = self.step_count >= self.max_stepsself.state = next_statereturn next_state, doneif __name__ == "__main__":# 初始化环境和算法env = TrafficSimulationEnv(state_size=8)derlight = DERLight(state_size=8, action_size=4) # 4个相位动作# 开始训练derlight.train(env, episodes=1000)