天煜科技网站建设网络优化师
一、安装package
在使用爬虫前,需要先安装三个包,requests、BeautifulSoup、selenium。
输入如下代码,若无报错,则说明安装成功。
import requests
from bs4 import BeautifulSoup
import selenium
二、Requests应用


了解了原理,接下来实际应用一下requests库叭~
import requestsurl = "https://www.baidu.com"
r = requests.get(url)
print(r.status_code)
print(r.headers)
print(r.text)
如果运行上述代码时出现如下报错:👇
requests.exceptions.ProxyError: HTTPSConnectionPool(host='blog.csdn.net', port=443): Max retries exceeded with url: /m0_51339444/article/details/129049696 (Caused by ProxyError('Cannot connect to proxy.', OSError(0, 'Error')))
可能是因为:(1)网络资源过大,网络无法加载;(2)使用了科学上网,需要关闭。
运行后,其中,r.status_code的返回值是200,表示请求成功,但是如果返回值是400,则表示请求失败。另外,发现程序的r.text输出出现乱码,这是因为在headers内没有明确指出encoding方式,会将其默认成ISO-8859-1编码方式,导致乱码。但是,仔细观察r.text输出,meta中暗示了是“utf-8”编码:👇

因此,需要指定r.encoding = “utf-8”,然后再执行,输出无乱码。完整代码如下:
import requestsurl = "https://www.baidu.com"
r = requests.get(url)
print(r.status_code)
print("===============================")
print(r.headers)
print("===============================")
print(r.text)
print("===============================")
print(r.encoding)
r.encoding = "utf-8"
print("===============================")
print(r.text)
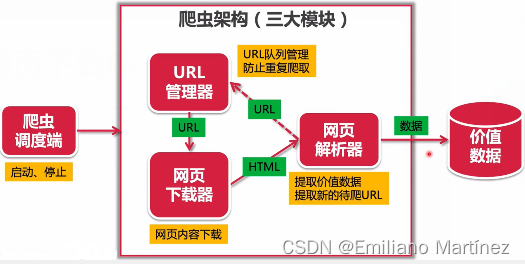
三、URL管理器

class UrlManager():"""url管理器"""def __init__(self): # 初始化self.new_urls = set() # 放待爬取过的urlself.old_urls = set() # 放已经爬取的url# 增添新的url(下面两个函数)(实现添加以及判重)def add_new_url(self, url):if url is None or len(url) == 0: # 判定url是否合法return# 判断url是否在容器中, 在就return,不添加if url in self.new_urls or url in self.old_urls:returnself.new_urls.add(url) # 否则,就添加新的url在集合中def add_new_urls(self, urls):if urls is None or len(urls) == 0:returnfor url in urls:self.add_new_url(url)# 获取待爬取的url (记得更改url状态)def get_url(self):if self.has_new_url():url = self.new_urls.pop()self.old_urls.add(url)return urlelse:return None# 判断容器中有没有新的待爬取的urldef has_new_url(self):return len(self.new_urls) > 0if __name__ == "__main__":url_manager = UrlManager()url_manager.add_new_url("url1")url_manager.add_new_urls(["url1", "url2"])print(url_manager.new_urls, url_manager.old_urls)print("================================")new_url = url_manager.get_url()print(url_manager.new_urls, url_manager.old_urls)print("================================")new_url = url_manager.get_url()print(url_manager.new_urls, url_manager.old_urls)print("================================")print(url_manager.has_new_url())

四、HTML简介
为了方便我们更好的理解网站的构成,需要先了解一下HTML的基本原理。
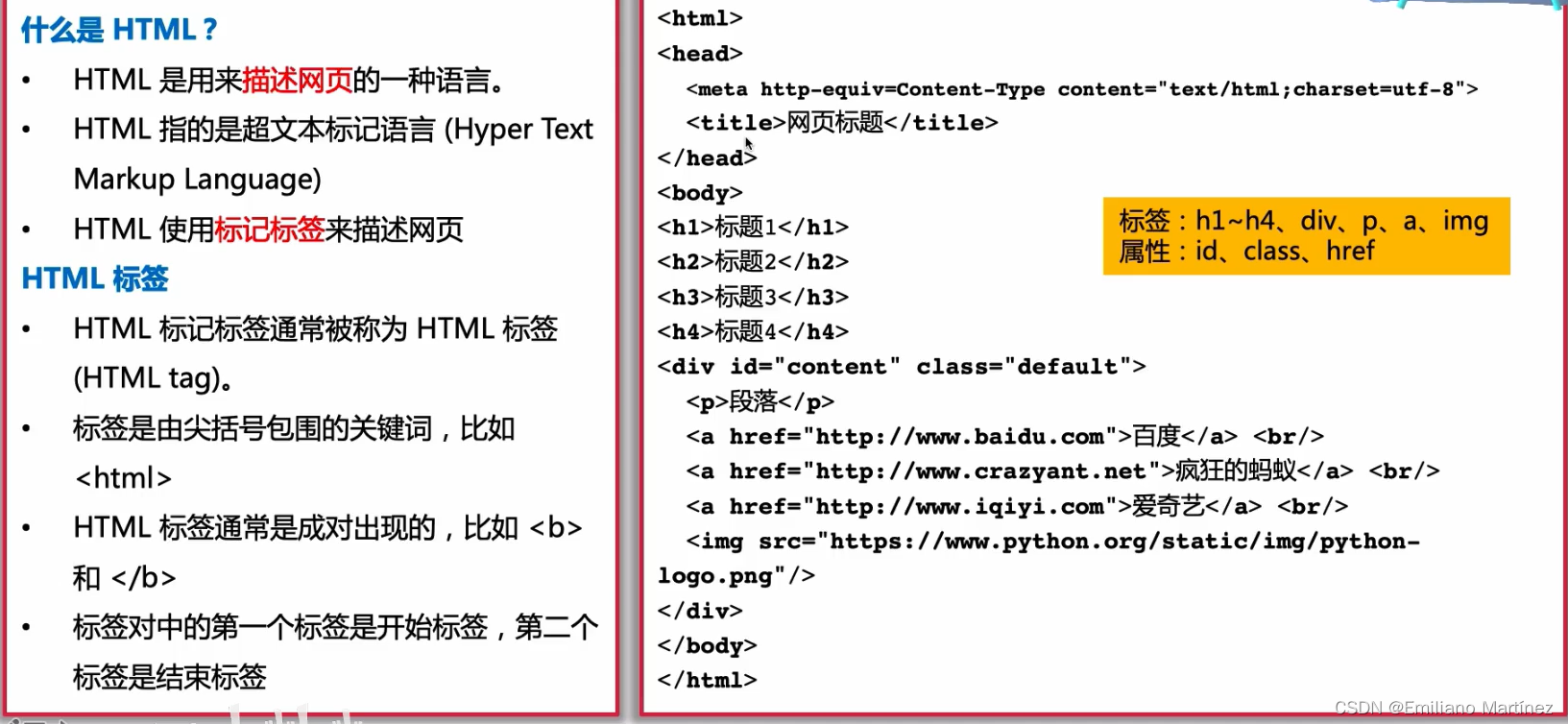
<head>里面是网站上不可见的信息
<body>里面是网站上可见的信息