注册公司流程及步骤百度快照优化排名怎么做
引言
本文我们采用比较聚合模型来实现文本匹配任务。
数据准备
数据准备包括
- 构建词表(Vocabulary)
- 构建数据集(Dataset)
本次用的是LCQMC通用领域问题匹配数据集,它已经分好了训练、验证和测试集。
我们通过pandas来加载一下。
import pandas as pdtrain_df = pd.read_csv(data_path.format("train"), sep="\t", header=None, names=["sentence1", "sentence2", "label"])train_df.head()

数据是长这样子的,有两个待匹配的句子,标签是它们是否相似。
下面用jieba来处理每个句子。
def tokenize(sentence):return list(jieba.cut(sentence))train_df.sentence1 = train_df.sentence1.apply(tokenize)
train_df.sentence2 = train_df.sentence2.apply(tokenize)
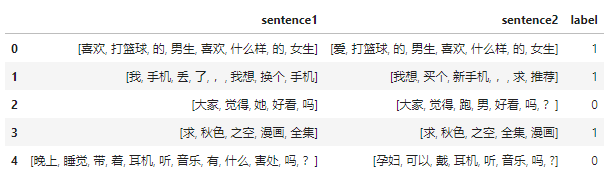
得到分好词的数据后,我们就可以得到整个训练语料库中的所有token:
train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list()
train_sentences[0]
['喜欢', '打篮球', '的', '男生', '喜欢', '什么样', '的', '女生']
现在就可以来构建词表了,我们定义一个类:
UNK_TOKEN = "<UNK>"
PAD_TOKEN = "<PAD>"class Vocabulary:"""Class to process text and extract vocabulary for mapping"""def __init__(self, token_to_idx: dict = None, tokens: list[str] = None) -> None:"""Args:token_to_idx (dict, optional): a pre-existing map of tokens to indices. Defaults to None.tokens (list[str], optional): a list of unique tokens with no duplicates. Defaults to None."""assert any([tokens, token_to_idx]), "At least one of these parameters should be set as not None."if token_to_idx:self._token_to_idx = token_to_idxelse:self._token_to_idx = {}if PAD_TOKEN not in tokens:tokens = [PAD_TOKEN] + tokensfor idx, token in enumerate(tokens):self._token_to_idx[token] = idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self.unk_index = self._token_to_idx[UNK_TOKEN]self.pad_index = self._token_to_idx[PAD_TOKEN]@classmethoddef build(cls,sentences: list[list[str]],min_freq: int = 2,reserved_tokens: list[str] = None,) -> "Vocabulary":"""Construct the Vocabulary from sentencesArgs:sentences (list[list[str]]): a list of tokenized sequencesmin_freq (int, optional): the minimum word frequency to be saved. Defaults to 2.reserved_tokens (list[str], optional): the reserved tokens to add into the Vocabulary. Defaults to None.Returns:Vocabulary: a Vocubulary instane"""token_freqs = defaultdict(int)for sentence in tqdm(sentences):for token in sentence:token_freqs[token] += 1unique_tokens = (reserved_tokens if reserved_tokens else []) + [UNK_TOKEN]unique_tokens += [tokenfor token, freq in token_freqs.items()if freq >= min_freq and token != UNK_TOKEN]return cls(tokens=unique_tokens)def __len__(self) -> int:return len(self._idx_to_token)def __getitem__(self, tokens: list[str] | str) -> list[int] | int:"""Retrieve the indices associated with the tokens or the index with the single tokenArgs:tokens (list[str] | str): a list of tokens or single tokenReturns:list[int] | int: the indices or the single index"""if not isinstance(tokens, (list, tuple)):return self._token_to_idx.get(tokens, self.unk_index)return [self.__getitem__(token) for token in tokens]def lookup_token(self, indices: list[int] | int) -> list[str] | str:"""Retrive the tokens associated with the indices or the token with the single indexArgs:indices (list[int] | int): a list of index or single indexReturns:list[str] | str: the corresponding tokens (or token)"""if not isinstance(indices, (list, tuple)):return self._idx_to_token[indices]return [self._idx_to_token[index] for index in indices]def to_serializable(self) -> dict:"""Returns a dictionary that can be serialized"""return {"token_to_idx": self._token_to_idx}@classmethoddef from_serializable(cls, contents: dict) -> "Vocabulary":"""Instantiates the Vocabulary from a serialized dictionaryArgs:contents (dict): a dictionary generated by `to_serializable`Returns:Vocabulary: the Vocabulary instance"""return cls(**contents)def __repr__(self):return f"<Vocabulary(size={len(self)})>"可以通过build方法传入所有分好词的语句,同时传入min_freq指定保存最少出现次数的单词。
这里实现了__getitem__来获取token对应的索引,如果传入的是单个token就返回单个索引,如果传入的是token列表,就返回索引列表。类似地,通过lookup_token来根据所以查找对应的token。
vocab = Vocabulary.build(train_sentences)
vocab
100%|██████████| 477532/477532 [00:00<00:00, 651784.13it/s]
<Vocabulary(size=35925)>
我们的词表有35925个token。
有了词表之后,我们就可以向量化句子了,这里也通过一个类来实现。
class TMVectorizer:"""The Vectorizer which vectorizes the Vocabulary"""def __init__(self, vocab: Vocabulary, max_len: int) -> None:"""Args:vocab (Vocabulary): maps characters to integersmax_len (int): the max length of the sequence in the dataset"""self.vocab = vocabself.max_len = max_lendef _vectorize(self, indices: list[int], vector_length: int = -1, padding_index: int = 0) -> np.ndarray:"""Vectorize the provided indicesArgs:indices (list[int]): a list of integers that represent a sequencevector_length (int, optional): an arugment for forcing the length of index vector. Defaults to -1.padding_index (int, optional): the padding index to use. Defaults to 0.Returns:np.ndarray: the vectorized index array"""if vector_length <= 0:vector_length = len(indices)vector = np.zeros(vector_length, dtype=np.int64)if len(indices) > vector_length:vector[:] = indices[:vector_length]else:vector[: len(indices)] = indicesvector[len(indices) :] = padding_indexreturn vectordef _get_indices(self, sentence: list[str]) -> list[int]:"""Return the vectorized sentenceArgs:sentence (list[str]): list of tokensReturns:indices (list[int]): list of integers representing the sentence"""return [self.vocab[token] for token in sentence]def vectorize(self, sentence: list[str], use_dataset_max_length: bool = True) -> np.ndarray:"""Return the vectorized sequenceArgs:sentence (list[str]): raw sentence from the datasetuse_dataset_max_length (bool): whether to use the global max vector lengthReturns:the vectorized sequence with padding"""vector_length = -1if use_dataset_max_length:vector_length = self.max_lenindices = self._get_indices(sentence)vector = self._vectorize(indices, vector_length=vector_length, padding_index=self.vocab.pad_index)return vector@classmethoddef from_serializable(cls, contents: dict) -> "TMVectorizer":"""Instantiates the TMVectorizer from a serialized dictionaryArgs:contents (dict): a dictionary generated by `to_serializable`Returns:TMVectorizer:"""vocab = Vocabulary.from_serializable(contents["vocab"])max_len = contents["max_len"]return cls(vocab=vocab, max_len=max_len)def to_serializable(self) -> dict:"""Returns a dictionary that can be serializedReturns:dict: a dict contains Vocabulary instance and max_len attribute"""return {"vocab": self.vocab.to_serializable(), "max_len": self.max_len}def save_vectorizer(self, filepath: str) -> None:"""Dump this TMVectorizer instance to fileArgs:filepath (str): the path to store the file"""with open(filepath, "w") as f:json.dump(self.to_serializable(), f)@classmethoddef load_vectorizer(cls, filepath: str) -> "TMVectorizer":"""Load TMVectorizer from a fileArgs:filepath (str): the path stored the fileReturns:TMVectorizer:"""with open(filepath) as f:return TMVectorizer.from_serializable(json.load(f))
命名为TMVectorizer表示是用于文本匹配(Text Matching)的专门类,调用vectorize方法一次传入一个分好词的句子就可以得到向量化的表示,支持填充Padding。
同时还支持保存功能,主要是用于保存相关的词表以及TMVectorizer所需的max_len字段。
在本小节的最后,通过继承Dataset来构建专门的数据集。
class TMDataset(Dataset):"""Dataset for text matching"""def __init__(self, text_df: pd.DataFrame, vectorizer: TMVectorizer) -> None:"""Args:text_df (pd.DataFrame): a DataFrame which contains the processed data examplesvectorizer (TMVectorizer): a TMVectorizer instance"""self.text_df = text_dfself._vectorizer = vectorizerdef __getitem__(self, index: int) -> Tuple[np.ndarray, np.ndarray, int]:row = self.text_df.iloc[index]return (self._vectorizer.vectorize(row.sentence1),self._vectorizer.vectorize(row.sentence2),row.label,)def get_vectorizer(self) -> TMVectorizer:return self._vectorizerdef __len__(self) -> int:return len(self.text_df)构建函数所需的参数只有两个,分别是处理好的DataFrame和TMVectorizer实例。
实现__getitem__方法,因为这个方法会被DataLoader调用,在该方法中对语句进行向量化。
max_len = 50
vectorizer = TMVectorizer(vocab, max_len)train_dataset = TMDataset(train_df, vectorizer)batch_size = 128
train_data_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)for setence1, setence12, label in train_data_loader:print(setence1)print(setence12)print(label)break
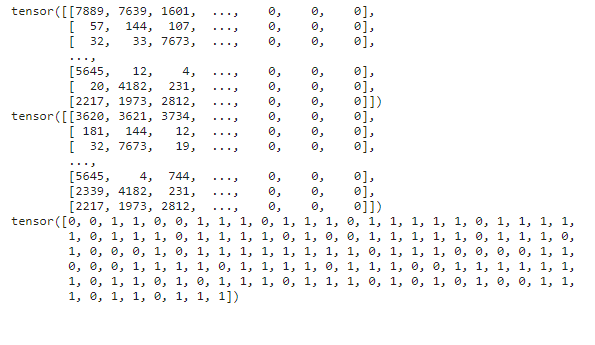
模型实现

该模型的整体架构如上图所示,由以下四层组成:
- 预处理层(Preprocessing) 使用一个预处理层(图中没有)来处理 Q \pmb Q Q和 A \pmb A A来获取两个新矩阵 Q ‾ ∈ R l × Q \overline{\pmb Q} \in \R^{l \times Q} Q∈Rl×Q和 A ‾ ∈ R l × A \overline{\pmb A} \in \R^{l \times A} A∈Rl×A。目的是为序列中每个单词获取一个新的嵌入向量,来捕获一些上下文信息。
- 注意力层(Attention) 在 Q ‾ \overline{\pmb Q} Q和 A ‾ \overline{\pmb A} A上应用标准的注意力机制,以获取对于 A ‾ \overline{\pmb A} A中每个列向量(对应一个单词)在 Q ‾ \overline{\pmb Q} Q中所有列向量相应的注意力权重。基于这些注意力权重,对于 A ‾ \overline{\pmb A} A中的每个列向量 a ‾ j \overline {\pmb a}_j aj,计算一个相应的 h j \pmb h_j hj向量,它是 Q ‾ \overline{\pmb Q} Q列向量的注意力加权和。
- 比较层(Comparision) 使用一个比较函数 f f f来组合每个 a ‾ j \overline {\pmb a}_j aj和 h ‾ j \overline {\pmb h}_j hj对到一个向量 t j \pmb t_j tj。
- 聚合层(Aggregation) 使用CNN层来聚合向量序列 t \pmb t t用于最后的分类。
预处理层
这里使用了一种简化的LSTM/GRU的门控结构对输入文本进行处理。
Q ‾ = σ ( W i Q + b i ⊗ e Q ) ⊙ tanh ( W u Q + b u ⊗ e Q ) A ‾ = σ ( W i A + b i ⊗ e A ) ⊙ tanh ( W u A + b u ⊗ e A ) \begin{aligned} \overline{\pmb Q} &= \sigma(W^i\pmb Q + \pmb b^i \otimes \pmb e_Q) \odot \tanh(W^u \pmb Q + \pmb b^u \otimes \pmb e_Q) \\ \overline{\pmb A} &= \sigma(W^i\pmb A + \pmb b^i \otimes \pmb e_A) \odot \tanh(W^u \pmb A + \pmb b^u \otimes \pmb e_A) \end{aligned} QA=σ(WiQ+bi⊗eQ)⊙tanh(WuQ+bu⊗eQ)=σ(WiA+bi⊗eA)⊙tanh(WuA+bu⊗eA)
相当于仅保留输入门来记住有意义的单词, σ ( ⋅ ) \sigma(\cdot) σ(⋅)部分代表是门控, tanh ( ⋅ ) \tanh(\cdot) tanh(⋅)代表具体的值。
其中, ⊙ \odot ⊙代表元素级乘法; W i , W u ∈ R l × d W^i,W^u \in \R^{l \times d} Wi,Wu∈Rl×d, b i , b u ∈ R l \pmb b^i,\pmb b^u \in \R^l bi,bu∈Rl是要学习的参数; ⊗ \otimes ⊗代表克罗内克积。具体为将列向量 b \pmb b b复制Q份拼接起来组成一个 l × Q l \times Q l×Q的矩阵与 W i Q W^i\pmb Q WiQ的结果矩阵维度保持一致,但这在Pytorch中似乎利用广播机制就够了; l l l表示隐藏单元个数。
class Preprocess(nn.Module):"""Implements the preprocess layer"""def __init__(self, embedding_dim: int, hidden_size: int) -> None:"""Args:embedding_dim (int): embedding sizehidden_size (int): hidden size"""super().__init__()self.Wi = nn.Parameter(torch.randn(embedding_dim, hidden_size))self.bi = nn.Parameter(torch.randn(hidden_size))self.Wu = nn.Parameter(torch.randn(embedding_dim, hidden_size))self.bu = nn.Parameter(torch.randn(hidden_size))def forward(self, x: torch.Tensor) -> torch.Tensor:"""Args:x (torch.Tensor): the input sentence with shape (batch_size, seq_len, embedding_size)Returns:torch.Tensor:"""# e_xi (batch_size, seq_len, hidden_size)e_xi = torch.matmul(x, self.Wi)# gate (batch_size, seq_len, hidden_size)gate = torch.sigmoid(e_xi + self.bi)# e_xu (batch_size, seq_len, hidden_size)e_xu = torch.matmul(x, self.Wu)# value (batch_size, seq_len, hidden_size)value = torch.tanh(e_xu + self.bu)# x_bar (batch_size, seq_len, hidden_size)x_bar = gate * valuereturn x_bar
预处理层可以接收 Q Q Q和 A A A,分别得到 Q ‾ \overline{\pmb Q} Q和 A ‾ \overline{\pmb A} A。这里实现上分别计算门控和具体的值,然后将它们乘起来。
注意力层
注意力层构建在计算好的 Q ‾ \overline{\pmb Q} Q和 A ‾ \overline{\pmb A} A上:
G = softmax ( ( W g Q ‾ + b g ⊗ e Q ) T A ‾ ) H = Q ‾ G \begin{aligned} \pmb G &= \text{softmax}((W^g\overline{\pmb Q} + \pmb b^g \otimes \pmb e_Q)^T \overline{\pmb A}) \\ \pmb H &= \overline{\pmb Q}\pmb G \end{aligned} GH=softmax((WgQ+bg⊗eQ)TA)=QG
其中 W g ∈ R l × l W^g \in \R^{l \times l} Wg∈Rl×l, b g ∈ R l \pmb b^g \in \R ^l bg∈Rl是学习的参数; G ∈ R Q × A \pmb G \in \R^{Q \times A} G∈RQ×A是注意力矩阵; H ∈ R l × A \pmb H \in \R^{l \times A} H∈Rl×A是注意力加权的向量,即注意力运算结果,它的维度和 A \pmb A A一致。
具体地, h j \pmb h_j hj是 H \pmb H H的第 j j j列,是通过 Q ‾ \overline{\pmb Q} Q的所有列的加权和计算而来,表示最能匹配 A \pmb A A中地 j j j个单词的部分 Q \pmb Q Q。
class Attention(nn.Module):def __init__(self, hidden_size: int) -> None:super().__init__()self.Wg = nn.Parameter(torch.randn(hidden_size, hidden_size))self.bg = nn.Parameter(torch.randn(hidden_size))def forward(self, q_bar: torch.Tensor, a_bar: torch.Tensor) -> torch.Tensor:"""forward in attention layerArgs:q_bar (torch.Tensor): the question sentencce with shape (batch_size, q_seq_len, hidden_size)a_bar (torch.Tensor): the answer sentence with shape (batch_size, a_seq_len, hidden_size)Returns:torch.Tensor: weighted sum of q_bar"""# e_q_bar (batch_size, q_seq_len, hidden_size)e_q = torch.matmul(q_bar, self.Wg)# transform (batch_size, q_seq_len, hidden_size)transform = e_q + self.bg# attention_matrix (batch_size, q_seq_len, a_seq_len)attention_matrix = torch.softmax(torch.matmul(transform, a_bar.permute(0, 2, 1)))# h (batch_size, a_seq_len, hidden_size)h = torch.matmul(attention_matrix.permute(0, 2, 1), a_bar)return h
这里要注意这两个句子的长度,不能搞混了。显示地将句子长度写出来不容易出错。
比如attention_matrix注意力矩阵得到的维度是(batch_size, q_seq_len, a_seq_len),对应原论文中说的 Q × A Q \times A Q×A, Q Q Q表示句子 Q \pmb Q Q的长度, A A A表示句子 Q \pmb Q Q的长度。
最后计算出来的 H \pmb H H与 A \pmb A A一致。相当于是单向地计算了 A \pmb A A对 Q \pmb Q Q的注意力,即 A A A的每个时间步都考虑了 Q \pmb Q Q的所有时间步。
比较层
作者觉得光注意力不够,还添加了一个比较层。比较层的目的是匹配每个 a ‾ j \overline{\pmb a}_j aj,它表示上下文 A \pmb A A中第 j j j个单词;和 h j \pmb h_j hj,它表示能最好匹配 a ‾ j \overline{\pmb a}_j aj的加权版 Q \pmb Q Q。
f f f表示一个比较函数,转换 a ‾ j \overline{\pmb a}_j aj和 h j \pmb h_j hj到一个向量 t j \pmb t_j tj,该向量表示比较的结果。
我们这里实现的是作者提出来的混合比较函数。
即组合了SUB和MULT接一个NN:
SUBMUTL+NN : t j = f ( a ‾ j , h j ) = ReLU ( W [ ( a ‾ j − h j ) ⊙ ( a ‾ j − h j ) a ‾ j ⊙ h j ] + b ) \text{SUBMUTL+NN}: \quad \pmb t_j = f(\overline{\pmb a}_j , \pmb h_j ) = \text{ReLU}(W\begin{bmatrix} (\overline{\pmb a}_j -\pmb h_j) \odot (\overline{\pmb a}_j -\pmb h_j) \\ \overline{\pmb a}_j \odot \pmb h_j \\ \end{bmatrix} + \pmb b) SUBMUTL+NN:tj=f(aj,hj)=ReLU(W[(aj−hj)⊙(aj−hj)aj⊙hj]+b)
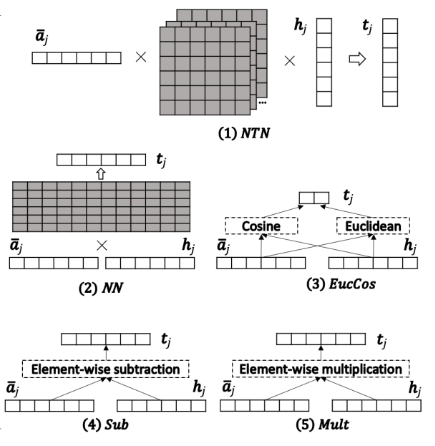
如果用图片表示的话,那就是上图(4)+(5)+(2)。
class Compare(nn.Module):def __init__(self, hidden_size: int) -> None:super().__init__()self.W = nn.Parameter(torch.randn(2 * hidden_size, hidden_size))self.b = nn.Parameter(torch.randn(hidden_size))def forward(self, h: torch.Tensor, a_bar: torch.Tensor) -> torch.Tensor:"""Args:h (torch.Tensor): the output of Attention layer (batch_size, a_seq_len, hidden_size)a_bar (torch.Tensor): proprecessed a (batch_size, a_seq_len, hidden_size)Returns:torch.Tensor:"""# sub (batch_size, a_seq_len, hidden_size)sub = (h - a_bar) ** 2# mul (batch_size, a_seq_len, hidden_size)mul = h * a_bar# t (batch_size, a_seq_len, hidden_size)t = torch.relu(torch.matmul(torch.cat([sub, mul], dim=-1), self.W) + self.b)return t
该比较层的输入接收上一层比较后的结果,和预处理后的 A \pmb A A。
最后是聚合层,以及整个模型架构的堆叠。
我们先来看聚合层。
聚合层
在通过上面的比较函数得到一系列 t j \pmb t_j tj向量之后,使用一层(Text) CNN来聚合这些向量:
r = CNN ( [ t 1 , ⋯ , t A ] ) \pmb r = \text{CNN}([\pmb t_1,\cdots, \pmb t_A]) r=CNN([t1,⋯,tA])
这里 r ∈ R n l \pmb r \in \R^{nl} r∈Rnl可以用于最终的分类, n n n是CNN中的窗口数(卷积核数)。
聚合层接收上一层的输出 t \pmb t t,这是一个长度为 A A A的向量序列。得到的 r \pmb r r维度是 n × l n \times l n×l, l l l我们知道是隐藏单元个数, n n n是卷积核数。
具体在实现这里的CNN之前,我们先来回顾一下CNN的知识。
CNN
我们通过图片来直观理解一下, https://ezyang.github.io/convolution-visualizer/ 提供了一个很好地可视化页面。

假设初始时有一张大小6x6的输入图片;卷积核大小为3,即这个filter(上图中的Weight)为3x3,filter中的权重是可学习的;填充为0;步长(stride)为1,代表这个filter每次移动一步。上面的这个Dilation参数我们这里不需要关心。
具体地,filter和它盖住的输入部分对应位置元素相乘再累加,得到一个标量输出,此时位于输出(output)矩阵的0,0处。

由于步长为1,filter可以右移一步,经过运算得到了Output中的0,1处的标量。以此类推:
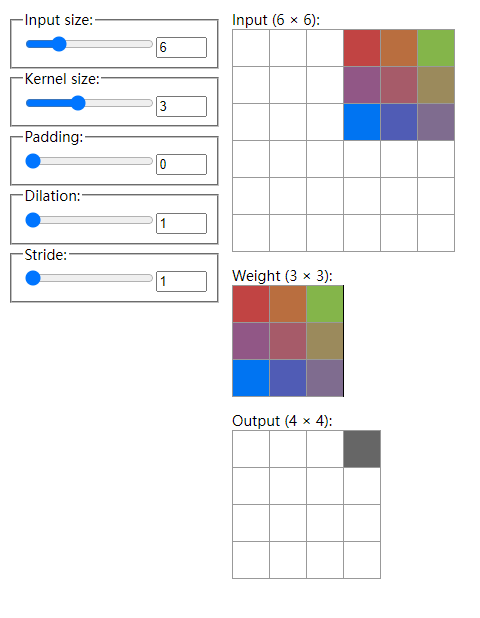
当它移动到输入的最右边时,计算出来Output中第一行的最后一个元素0,3处。
下一次移动该filter就会从输入的第二行开始:
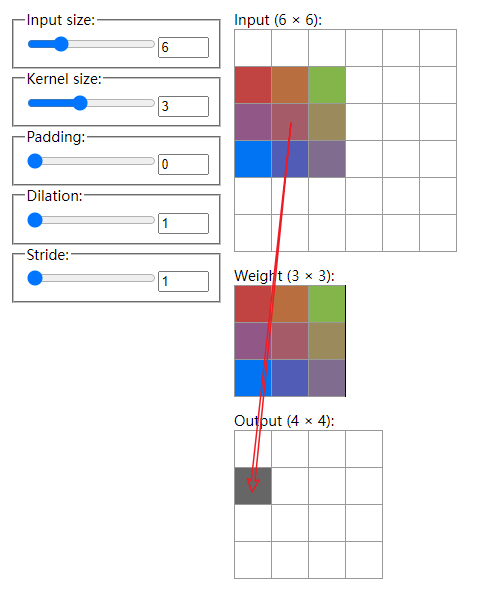
计算出Output中的1,0处元素。这就是卷积操作。该输出Output也叫feature map,这里只演示了一个filter,实际上如果再来一个同样大小但参数不同的卷积核,我们就可以得到2个4x4的feature map。
要注意的是,filter不一定是方阵。
那我们要怎么知道输出的大小呢?可以看出这是和输入大小以及filter大小有关的。
如果我们有一个 n × n n \times n n×n的图像,用一个 f × f f \times f f×f 的filter做卷积,那么得到的结果矩阵大小将是 ( n − f + 1 ) × ( n − f + 1 ) (n - f +1) \times (n - f +1) (n−f+1)×(n−f+1)。
我们带入算一下,这里 n = 6 , f = 3 n=6,f=3 n=6,f=3,结果矩阵大小是 6 − 3 + 1 = 4 6-3+1=4 6−3+1=4,正确。
在CV中图片一般是用rgb来表示的,分别表示三个通道(channel),输入就会变成三维的。那么filter也会变成三维的,过滤器的通道数要和输入的通道数一致。
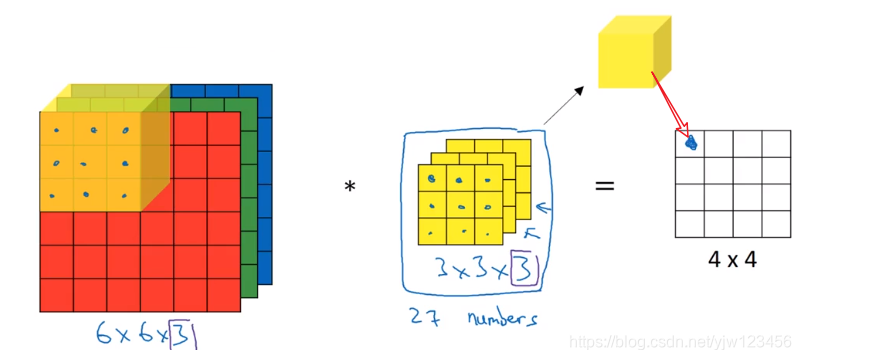
虽然是三维的,但过滤器一步计算出来的结果还是一个标量,之前是累加9个数,现在变成了累加27个数。这样我们得到的输出大小还是4x4的。
下面用一张动图作为一个总结,图片来自Lerner Zhang在参考3问题中的回答:
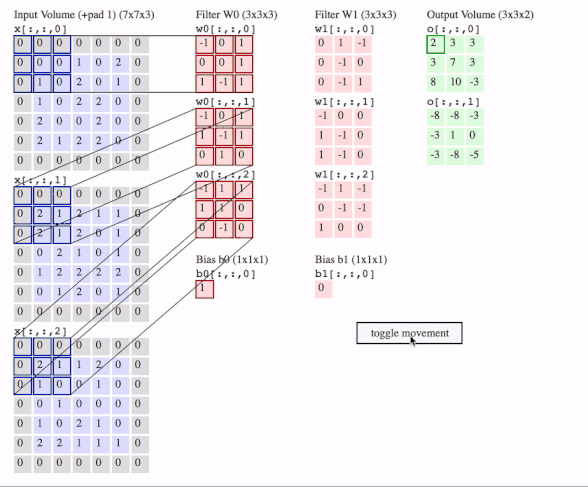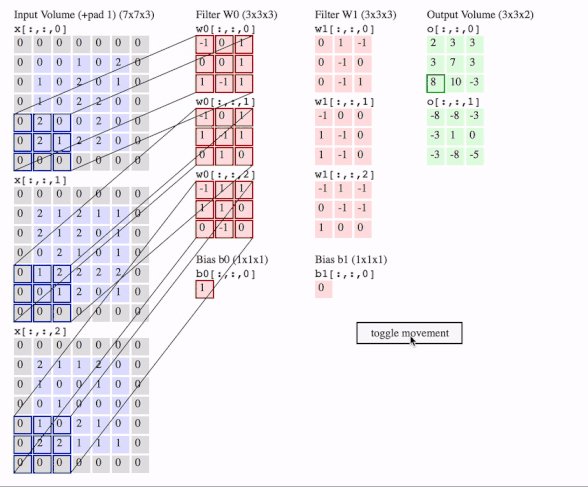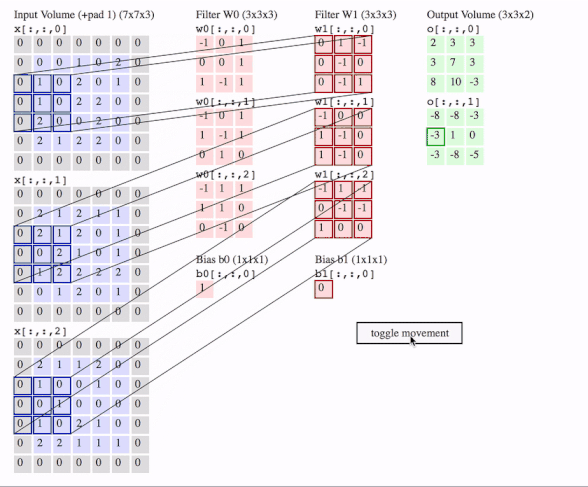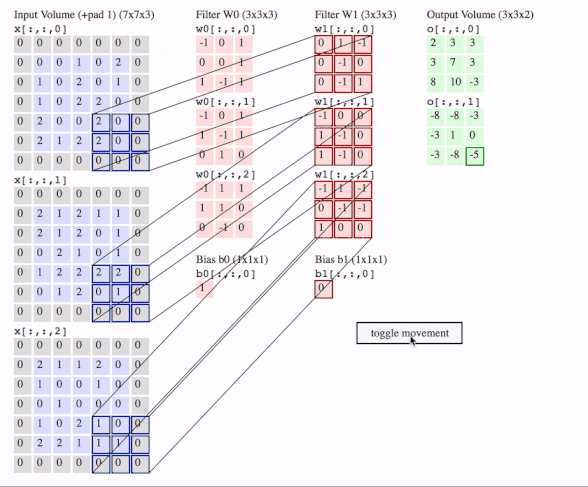
这里有三个通道,即图片是3D的,有两个filter,每个filter也是3D的,我们就得到了2个输出。图中还画了一个偏置。
等等,我们上面介绍的只是卷积操作,其实还有池化操作。
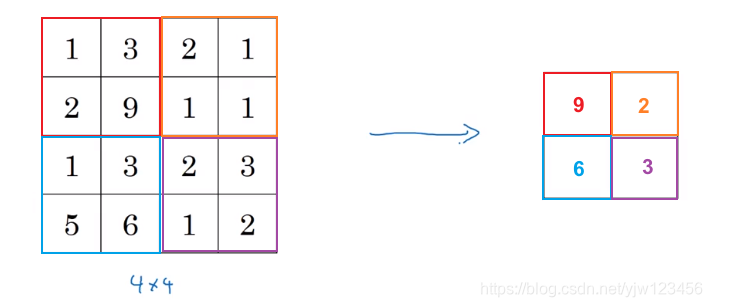
这里输入是一个 4 × 4 4 \times 4 4×4的矩阵,用到的池化类型是最大池化(max pooling),把输入分成了四组,每组中取最大元素,得到一个 2 × 2 2 \times 2 2×2的输出矩阵。
可以理解为应用了一个 2 × 2 2\times 2 2×2的filter,步长为2。
除了最大池化,比较常用的还有一种叫平均池化,就是计算对应元素的平均值。
池化操作的输出大小计算为 n − f s + 1 \frac{n-f}{s} + 1 sn−f+1, s s s表示步长, n n n是feature map的高度。
我们也计算一下, 4 − 2 2 + 1 = 2 \frac{4-2}{2}+1=2 24−2+1=2,没错。
最后的最后,一般还有一个激活函数,比如可以是 ReLU \text{ReLU} ReLU,应用在池化后的结果上。
以上是对CNN在图像应用的一个小回顾,更详细的可以见参考文章。
下面我们来看下CNN如何应用在文本上。
TextCNN
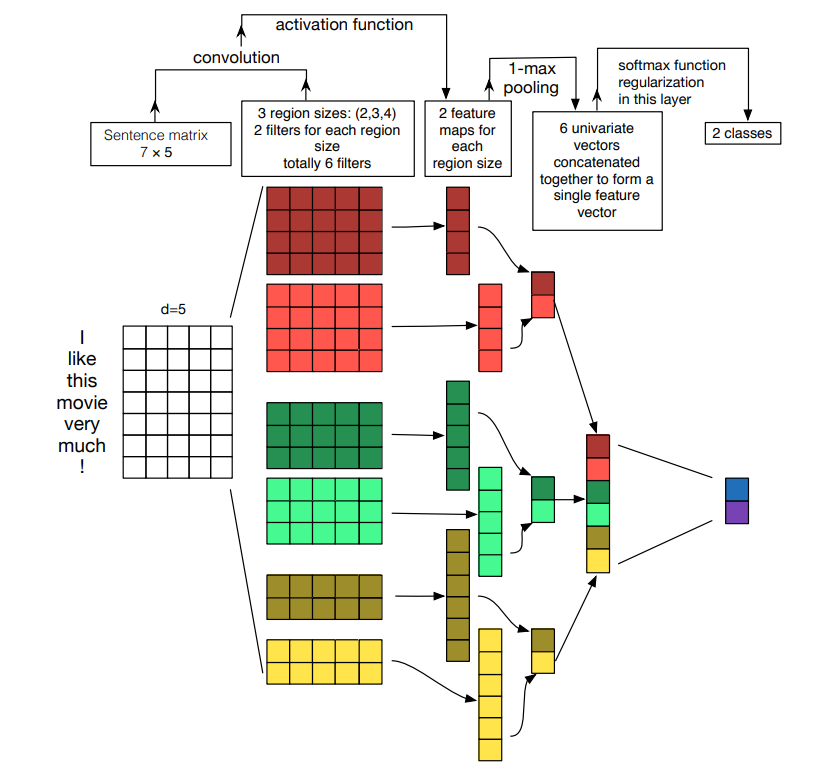
个人感觉描述TextCNN最清晰的就是这张图片,来自参考5的论文。
这张图片描述的内容有点多,我们来逐一分析一下。
按照从左往右、从上往下的顺序,①首先来看输入,输入是一个 7 × 5 7 \times 5 7×5的矩阵,也就是(seq_len, embedding_dim),句子长度为7,词嵌入大小为5。
② 然后应用了三个不同的filter大小(用不同的颜色表示),分别为2,3,4。 每个大小分配两个不同的filter(用同一颜色不同深浅表示,比如第二列矩阵第一个是棕红色,第二个是亮红色,都是大小为4的),即共6个filter。
这里要注意的是filter不再是方阵,而是(filter_size, embedding_dim)。且一般步长都会设成1,但不需要右移,直接往下移即可,这非常类似word2vec中n-gram的窗口大小(每次处理filter_size个单词),所以也称这个filter_size为window_size,这个在看论文的时候要注意。
就以这个 4 × 5 4 \times 5 4×5的filter为例,它得到的feature map大小是怎样的呢?由于filter的宽度是固定的为词嵌入大小,因此不管词嵌入大小有多大,每次filter计算输出是一个标量。所以我们只要关心filter的高度,也就是filter_size。在上面的图片中表示为region size。
所以这里的region size为4,基于步长为1的情况下,也可以通过上面小节介绍的公式 ( n − f + 1 ) (n - f +1) (n−f+1)来计算。 n n n是输入句子的长度; f f f就是filter_size。那么代入 7 − 4 + 1 = 4 7-4+1=4 7−4+1=4。即输出 4 × 1 4 \times 1 4×1的列向量(矩阵),对应上图第三列的第一个矩阵。
我们再来验证 f = 2 f=2 f=2的情况,输出应该为 7 − 2 + 1 = 6 7-2+1=6 7−2+1=6,对应上图第三列黄色的矩阵,数一下刚好也是 6 × 1 6 \times 1 6×1的。
由于共有6个filter,因此共得到了6个列向量,维度存在不一样的情况。对了,这里卷积运算完毕后会经过激活函数,不过不会改变维度。
③ 维度不一样没关系,我们可以应用池化层。把这6个filter的输出应用对应大小的池化层就得到了6个标量。把这6个标量拼接在一起就得到了 6 × 1 6 \times 1 6×1的列向量。有多少个filter,行的维度就是多少。所以这里是6,这是很自然的。
这样我们得到了一个固定大小的输出,如上图的倒数第二列。显然我们应用一个和filter输出的feature map同样大小的最大池化filter就可以得到一个标量。
④ 拿到这个定长向量,可以把它理解为CNN作为特征提取器提取的句向量,就可以应用到不同的任务。比如文本分类任务中,可以喂给一个分类器。
好了,所需要的知识就这些,现在我们来实现这个由CNN构建的聚合层。
聚合层实现
class Aggregation(nn.Module):def __init__(self,embedding_dim: int,num_filter: int,filter_sizes: list[int],output_dim: int,conv_activation: str = "relu",dropout: float = 0.1,) -> None:"""_summary_Args:embedding_dim (int): embedding sizenum_filter (int): the output dim of each convolution layerfilter_sizes (list[int]): the size of the convolving kerneloutput_dim: (int) the number of classesconv_activation (str, optional): activation to use after the convolution layer. Defaults to "relu".dropout (float): the dropout ratio"""super().__init__()if conv_activation.lower() == "relu":activation = nn.ReLU()else:activation = nn.Tanh()self.convs = nn.ModuleList([nn.Sequential(nn.Conv2d(in_channels=1,out_channels=num_filter,kernel_size=(fs, embedding_dim),),activation,)for fs in filter_sizes])pooled_output_dim = num_filter * len(filter_sizes)self.linear = nn.Linear(pooled_output_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, t: torch.Tensor) -> torch.Tensor:"""Args:t (torch.Tensor): the output of Compare (batch_size, a_seq_len, hidden_size)Returns:torch.Tensor:"""# t (batch_size, 1, a_seq_len, hidden_size)t = t.unsqueeze(1)# the shape of convs_out(t) is (batch_size, num_filter, a_seq_len - filter_size + 1, 1)# element in convs_out with shape (batch_size, num_filter, a_seq_len - filter_size + 1)convs_out = [self.dropout(conv(t).squeeze(-1)) for conv in self.convs]# adaptive_avg_pool1d applies a 1d adaptive max pooling over an input# adaptive_avg_pool1d(o, output_size=1) returns an output with shape (batch_size, num_filter, 1)# so the elements in maxpool_out have a shape of (batch_size, num_filter)maxpool_out = [F.adaptive_avg_pool1d(o, output_size=1).squeeze(-1) for o in convs_out]# cat (batch_size, num_filter * len(filter_sizes))cat = torch.cat(maxpool_out, dim=1)# (batch_size, output_dim)return self.linear(cat)
这就是聚合层的实现,我们这里一次可以处理整个批次的数据。
我们这里用Conv2d来实现卷积,它有几个必填参数:
in_channels输入的通道数,对于图片来说的就是3,对于文本来说可以简单的认为就是1;out_channels就是filter的个数,对于同样大小的卷积核,可以设定参数不同的filter;kernel_size卷积核大小,这里不再是一个方阵,而是(filter_size, hidden_size)的矩阵
原论文中用了不同的filter_size,hidden_size是经过前面层转换过的嵌入的维度,和词嵌入维度可以不同,所以用hidden_size来描述更准确。
此外,这里应用了adaptive_max_pool1d方法来做最大池化操作,它需要指定一个输出大小,不管输入大小是怎样的,都会转换成这样的输出大小,我们就不需要关心其他东西。不然的话,用max_pool1d来实现还要考虑它的参数。
也有不少人通过
Conv1d来实现对文本的卷积,实际上是一样的,只不过参数不同,Conv1d应该还简单些,看个人的喜好。
整体实现
最后用一个模型把上面所有定义的模型封装起来:
class Aggregation(nn.Module):def __init__(self,embedding_dim: int,num_filter: int,filter_sizes: list[int],output_dim: int,conv_activation: str = "relu",dropout: float = 0.1,) -> None:"""_summary_Args:embedding_dim (int): embedding sizenum_filter (int): the output dim of each convolution layerfilter_sizes (list[int]): the size of the convolving kerneloutput_dim: (int) the number of classesconv_activation (str, optional): activation to use after the convolution layer. Defaults to "relu".dropout (float): the dropout ratio"""super().__init__()if conv_activation.lower() == "relu":activation = nn.ReLU()else:activation = nn.Tanh()self.convs = nn.ModuleList([nn.Sequential(nn.Conv2d(in_channels=1,out_channels=num_filter,kernel_size=(fs, embedding_dim),),activation,)for fs in filter_sizes])pooled_output_dim = num_filter * len(filter_sizes)self.linear = nn.Linear(pooled_output_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, t: torch.Tensor) -> torch.Tensor:"""Args:t (torch.Tensor): the output of Compare (batch_size, a_seq_len, hidden_size)Returns:torch.Tensor:"""# t (batch_size, 1, a_seq_len, hidden_size)t = t.unsqueeze(1)# the shape of convs_out(t) is (batch_size, num_filter, a_seq_len - filter_size + 1, 1)# element in convs_out with shape (batch_size, num_filter, a_seq_len - filter_size + 1)convs_out = [self.dropout(conv(t).squeeze(-1)) for conv in self.convs]# adaptive_avg_pool1d applies a 1d adaptive max pooling over an input# adaptive_avg_pool1d(o, output_size=1) returns an output with shape (batch_size, num_filter, 1)# so the elements in maxpool_out have a shape of (batch_size, num_filter)maxpool_out = [F.adaptive_avg_pool1d(o, output_size=1).squeeze(-1) for o in convs_out]# cat (batch_size, num_filter * len(filter_sizes))cat = torch.cat(maxpool_out, dim=1)# (batch_size, output_dim)return self.linear(cat)class ComAgg(nn.Module):"""The Compare aggregate MODEL model implemention."""def __init__(self, args) -> None:super().__init__()self.embedding = nn.Embedding(args.vocab_size, args.embedding_dim)self.preprocess = Preprocess(args.embedding_dim, args.hidden_size)self.attention = Attention(args.hidden_size)self.compare = Compare(args.hidden_size)self.aggregate = Aggregation(args.hidden_size,args.num_filter,args.filter_sizes,args.num_classes,args.conv_activation,args.dropout,)self.dropouts = [nn.Dropout(args.dropout) for _ in range(4)]def forward(self, q: torch.Tensor, a: torch.Tensor) -> torch.Tensor:"""_summary_Args:q (torch.Tensor): the inputs of q (batch_size, q_seq_len)a (torch.Tensor): the inputs of a (batch_size, a_seq_len)Returns:torch.Tensor: _description_"""q_embed = self.dropouts[0](self.embedding(q))a_embed = self.dropouts[0](self.embedding(a))q_bar = self.dropouts[1](self.preprocess(q_embed))a_bar = self.dropouts[1](self.preprocess(a_embed))h = self.dropouts[2](self.attention(q_bar, a_bar))# t (batch_size, a_seq_len, hidden_size)t = self.dropouts[3](self.compare(h, a_bar))# out (batch_size, num_filter * len(filter_sizes))out = self.aggregate(t)return out作者在附录透露了模型实现一些细节:
词嵌入由GloVe初始化,并且是 固定参数的,这里我们直接用自己初始化词嵌入层向量;隐藏层维度 l = 150 l=150 l=150;使用ADAMAX优化器,我们使用Adam就够了;批大小为 30 30 30,有点小;学习率为 0.002 0.002 0.002;唯一需要的超参数是dropout中的丢弃率,用于词嵌入层;对于不同的任务使用了不同的卷积核,最多同时使用了[1,2,3,4,5]。
训练模型
定义评估指标:
def metrics(y: torch.Tensor, y_pred: torch.Tensor) -> Tuple[float, float, float, float]:TP = ((y_pred == 1) & (y == 1)).sum().float() # True PositiveTN = ((y_pred == 0) & (y == 0)).sum().float() # True NegativeFN = ((y_pred == 0) & (y == 1)).sum().float() # False NegatvieFP = ((y_pred == 1) & (y == 0)).sum().float() # False Positivep = TP / (TP + FP).clamp(min=1e-8) # Precisionr = TP / (TP + FN).clamp(min=1e-8) # RecallF1 = 2 * r * p / (r + p).clamp(min=1e-8) # F1 scoreacc = (TP + TN) / (TP + TN + FP + FN).clamp(min=1e-8) # Accuraryreturn acc, p, r, F1
定义评估函数:
def evaluate(data_iter: DataLoader, model: nn.Module
) -> Tuple[float, float, float, float]:y_list, y_pred_list = [], []model.eval()for x1, x2, y in tqdm(data_iter):x1 = x1.to(device).long()x2 = x2.to(device).long()y = torch.LongTensor(y).to(device)output = model(x1, x2)pred = torch.argmax(output, dim=1).long()y_pred_list.append(pred)y_list.append(y)y_pred = torch.cat(y_pred_list, 0)y = torch.cat(y_list, 0)acc, p, r, f1 = metrics(y, y_pred)return acc, p, r, f1
定义训练函数:
def evaluate(data_iter: DataLoader, model: nn.Module
) -> Tuple[float, float, float, float]:y_list, y_pred_list = [], []model.eval()for x1, x2, y in tqdm(data_iter):x1 = x1.to(device).long()x2 = x2.to(device).long()y = torch.LongTensor(y).to(device)output = model(x1, x2)pred = torch.argmax(output, dim=1).long()y_pred_list.append(pred)y_list.append(y)y_pred = torch.cat(y_pred_list, 0)y = torch.cat(y_list, 0)acc, p, r, f1 = metrics(y, y_pred)return acc, p, r, f1def train(data_iter: DataLoader,model: nn.Module,criterion: nn.CrossEntropyLoss,optimizer: torch.optim.Optimizer,print_every: int = 500,verbose=True,
) -> None:model.train()for step, (x1, x2, y) in enumerate(tqdm(data_iter)):x1 = x1.to(device).long()x2 = x2.to(device).long()y = torch.LongTensor(y).to(device)output = model(x1, x2)loss = criterion(output, y)optimizer.zero_grad()loss.backward()optimizer.step()if verbose and (step + 1) % print_every == 0:pred = torch.argmax(output, dim=1).long()acc, p, r, f1 = metrics(y, pred)print(f" TRAIN iter={step+1} loss={loss.item():.6f} accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")定义整体参数:
args = Namespace(dataset_csv="text_matching/data/lcqmc/{}.txt",vectorizer_file="vectorizer.json",model_state_file="model.pth",save_dir=f"{os.path.dirname(__file__)}/model_storage",reload_model=False,cuda=True,learning_rate=1e-3,batch_size=128,num_epochs=10,max_len=50,embedding_dim=200,hidden_size=100,num_filter=1,filter_sizes=[1, 2, 3, 4, 5],conv_activation="relu",num_classes=2,dropout=0,min_freq=2,print_every=500,verbose=True,
)
开始训练:
make_dirs(args.save_dir)if args.cuda:device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
else:device = torch.device("cpu")print(f"Using device: {device}.")vectorizer_path = os.path.join(args.save_dir, args.vectorizer_file)train_df = build_dataframe_from_csv(args.dataset_csv.format("train"))
test_df = build_dataframe_from_csv(args.dataset_csv.format("test"))
dev_df = build_dataframe_from_csv(args.dataset_csv.format("dev"))if os.path.exists(vectorizer_path):print("Loading vectorizer file.")vectorizer = TMVectorizer.load_vectorizer(vectorizer_path)args.vocab_size = len(vectorizer.vocab)
else:print("Creating a new Vectorizer.")train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list()vocab = Vocabulary.build(train_sentences, args.min_freq)args.vocab_size = len(vocab)print(f"Builds vocabulary : {vocab}")vectorizer = TMVectorizer(vocab, args.max_len)vectorizer.save_vectorizer(vectorizer_path)train_dataset = TMDataset(train_df, vectorizer)
test_dataset = TMDataset(test_df, vectorizer)
dev_dataset = TMDataset(dev_df, vectorizer)train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True
)
dev_data_loader = DataLoader(dev_dataset, batch_size=args.batch_size)
test_data_loader = DataLoader(test_dataset, batch_size=args.batch_size)print(f"Arguments : {args}")
model = ComAgg(args)print(f"Model: {model}")model_saved_path = os.path.join(args.save_dir, args.model_state_file)
if args.reload_model and os.path.exists(model_saved_path):model.load_state_dict(torch.load(args.model_saved_path))print("Reloaded model")
else:print("New model")model = model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
criterion = nn.CrossEntropyLoss()for epoch in range(args.num_epochs):train(train_data_loader,model,criterion,optimizer,print_every=args.print_every,verbose=args.verbose,)print("Begin evalute on dev set.")with torch.no_grad():acc, p, r, f1 = evaluate(dev_data_loader, model)print(f"EVALUATE [{epoch+1}/{args.num_epochs}] accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")model.eval()acc, p, r, f1 = evaluate(test_data_loader, model)
print(f"TEST accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")Using device: cuda:0.
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.531 seconds.
Prefix dict has been built successfully.
Loading vectorizer file.
Arguments : Namespace(dataset_csv='text_matching/data/lcqmc/{}.txt', vectorizer_file='vectorizer.json', model_state_file='model.pth', reload_model=False, cuda=True, learning_rate=0.001, batch_size=128, num_epochs=10, max_len=50, embedding_dim=200, hidden_size=100, num_filter=1, filter_sizes=[1, 2, 3, 4, 5], conv_activation='relu', num_classes=2, dropout=0, min_freq=2, print_every=500, verbose=True, vocab_size=35925)
Model: ComAgg((embedding): Embedding(35925, 200)(preprocess): Preprocess()(attention): Attention()(compare): Compare()(aggregate): Aggregation((convs): ModuleList((0): Sequential((0): Conv2d(1, 1, kernel_size=(1, 100), stride=(1, 1))(1): ReLU())(1): Sequential((0): Conv2d(1, 1, kernel_size=(2, 100), stride=(1, 1))(1): ReLU())(2): Sequential((0): Conv2d(1, 1, kernel_size=(3, 100), stride=(1, 1))(1): ReLU())(3): Sequential((0): Conv2d(1, 1, kernel_size=(4, 100), stride=(1, 1))(1): ReLU())(4): Sequential((0): Conv2d(1, 1, kernel_size=(5, 100), stride=(1, 1))(1): ReLU()))(linear): Linear(in_features=5, out_features=2, bias=True)(dropout): Dropout(p=0, inplace=False))
)
New model
...
TRAIN iter=500 loss=0.427597 accuracy=0.805 precision=0.803 recal=0.838 f1 score=0.820153%|███████████████████████████████████████████████████████████████████████████████████████████████████▎ | 996/1866 [00:29<00:25, 34.26it/s]
TRAIN iter=1000 loss=0.471204 accuracy=0.789 precision=0.759 recal=0.900 f1 score=0.823580%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 1499/1866 [00:44<00:10, 34.42it/s]
TRAIN iter=1500 loss=0.446409 accuracy=0.773 precision=0.774 recal=0.867 f1 score=0.8176
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [00:55<00:00, 33.47it/s]
Begin evalute on dev set.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:00<00:00, 80.59it/s]
EVALUATE [10/10] accuracy=0.640 precision=0.621 recal=0.719 f1 score=0.6666
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 98/98 [00:01<00:00, 85.45it/s]
TEST accuracy=0.678 precision=0.628 recal=0.871 f1 score=0.7301
参考
- [论文笔记]A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES
- 李宏毅机器学习——深度学习卷积神经网络
- https://stats.stackexchange.com/questions/295397/what-is-the-difference-between-conv1d-and-conv2d
- 吴恩达深度学习——卷积神经网络基础
- A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification