梁山做网站的公司查询网站域名
摘要:介绍常见的反爬手段和反反爬思路,内容详细具体,明晰解释每一步,非常适合小白和初学者学习!!!
目录
一、明确几个概念
二、常见的反爬手段及反反爬思路
1、检测user-agent
2、ip 访问频率的限制
(1)代理的基本原理
(2)代理的作用
(3)爬虫代理
(4)代理分类
(5)常见代理设置
3、必须账号登录
4、动态网页,JavaScript 压缩、 混淆和加密,加大分析难度
5、机器学习,分析爬虫行为
一、明确几个概念
- 爬虫:采用任何技术手段,用别人开发好的程序, 批量 获取对方数据,都是爬虫。
- 反爬:用任何技术手段,阻止别人批量获取自己的数据
- 反反爬:使用任何技术手段、绕过对方的反爬策略
二、常见的反爬手段及反反爬思路
1、检测user-agent
User-Agent:简称 UA,这是一个特殊的字符串头,可以使服务器识别客户端使用的操作系统及版本、浏览器及版本等信息。做爬虫时如果加上此信息,可以伪装为浏览器; 如果不加,很可能会被识别出来。
在我们进行爬虫的过程中,经常是通过刷新网页,通过浏览器向服务器的数据传输来获取User-agent,以此将其写入Header请求头中来模仿伪装成浏览器。
- user-agent的获取方法(示例):
- 使用Chrome浏览器打开百度网站
- 按下F12键,打开开发者界面
- 此时由于页面没有数据传输,属于静态页面,开发者界面也就没有任何数据传输的情况。
- 刷新一下,在开发者界面点击Network,选择all,点击第一个数据信息条目,在header视图中可以找到user-agent信息
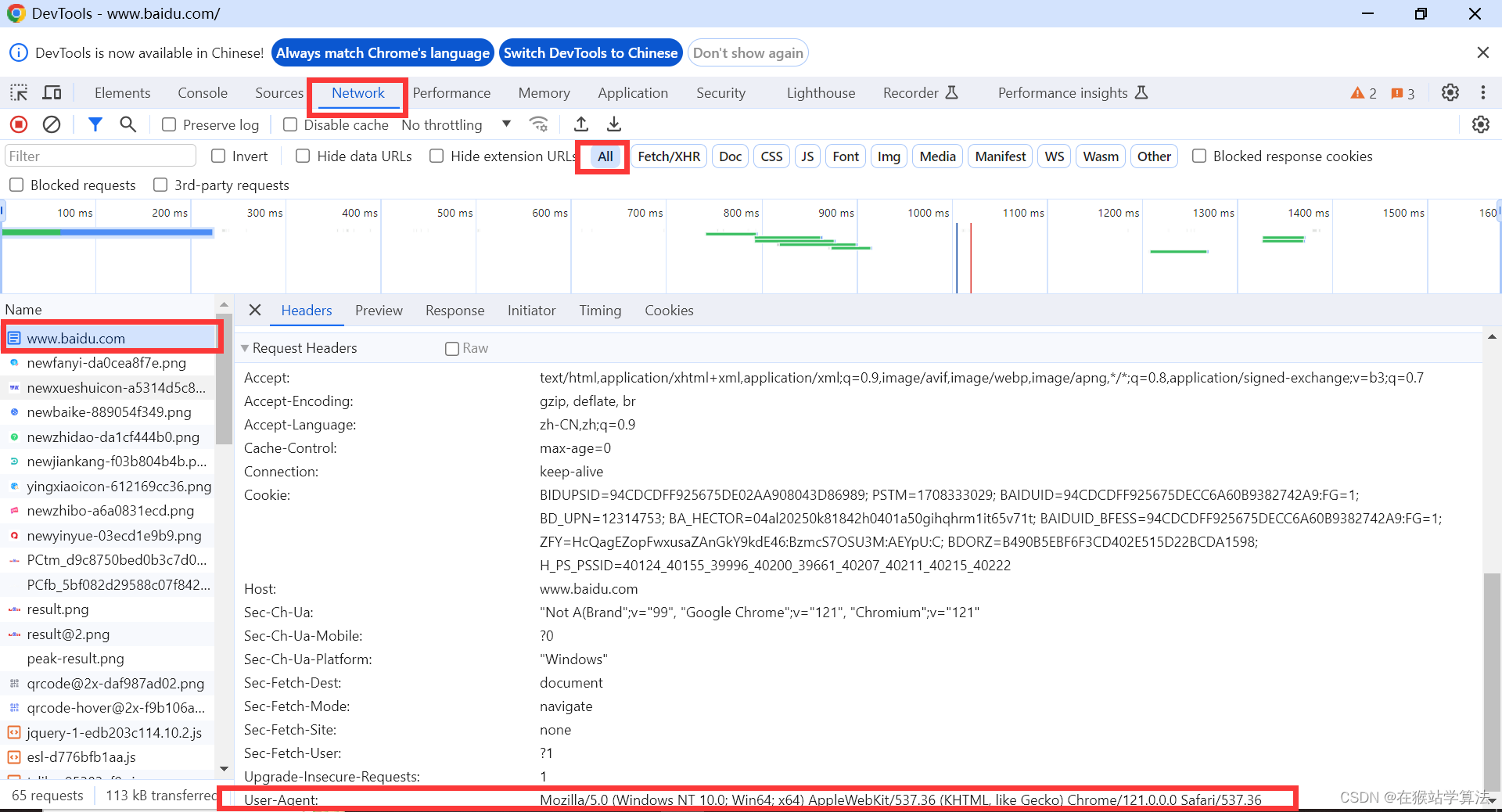
- 反爬手段
以上方式只能使用固定的一个useragent,那么这将存在一个隐患。做了反爬的网站会检测useragent,如果一直都只用这一个固定的useragent进行访问,次数多了网站会识别出是爬虫在访问其网站,由此对其反爬限制!!!
- 反反爬思路
采用随机选取正常浏览器的useragent池来访问网站,Python中有一个第三方库:fake-useragent,里面拥有大量正常浏览器的useragent池。我们每次访问网站时,可以随机调用其中一个useragent进行使用!!!
from fake_useragent import UserAgent
# 实例化一个UserAgent对象
ua = UserAgent()
# 调用UserAgent对象的方法:随机获取useragent的池中的一个useragent
user_agent = ua.random
# 每次打印的结果都是不同的正常浏览器的useragent
print(user_agent)
实战使用实例代码
import requests
# 该包拥有多个正常的user-agent的池
from fake_useragent import UserAgent
# 随机获取useragent的池中的一个useragent
ua = UserAgent()
user_agent = ua.random
headers = {'User-Agent':user_agent
}
url = 'https://www.baidu.com'
r =requests.get(url,headers=headers)
print(r.text)
2、ip 访问频率的限制
在做爬虫的过程中经常会遇到一种情况,就是爬虫最初是正常运行、正常抓取数据的,一切看起来来都是那么美好,然而一杯茶的工夫就出现了错误,例如403 Forbidden,这时打开网页一看,可能会看到“您的IP访问频率太高”这样的提示。出现这种现象是因为网站采取了一些反爬虫措施。例如服务器会检测某个IP在单位时间内的请求次数,如果请求次数超过设定的阈值,就直接拒绝提供服务,并返回一些错误信息,可以称这种情况为封IP(也就是ip访问频率限制)。
既然服务器检测的是某个IP在单位时间内的请求次数,那么借助某种方式把我们的IP伪装一下,让服务器识别不出请求是由我们本机发起的,不就可以成功防止封 IP 了吗?
一种有效的伪装方式是使用代理,后面会详细说明代理的用法。在这之前,需要先了解代理的基本原理,它是怎样实现伪装IP的呢?
(1)代理的基本原理
代理实际上就是指代理服务器,英文叫作 Proxy Server,功能是代网络用户取得网络信息。形象点说,代理是网络信息的中转站。当客户端正常请求一个网站时,是把请求发送给了 Web 服务器,Web服务器再把响应传回给客户端。设置代理服务器,就是在客户端和服务器之间搭建一座桥,此时客户端并非直接向 Web服务器发起请求,而是把请求发送给代理服务器,然后由代理服务器把请求发送给Web服务器,Web服务器返回的响应也是由代理服务器转发给客户端的。这样客户端同样可以正常访问网页,而且这个过程中Web服务器识别出的真实IP就不再是客户端的 IP了,成功实现了 IP伪装,这就是代理的基本原理。
(2)代理的作用
1、突破自身IP的访问限制,访问一些平时不能访问的站点。
2、访问一些单位或团体的内部资源。比如,使用教育网内地址段的免费代理服务器,就可以下载和上传对教育网开放的各类 FTP,也可以查询、共享各类资料等。
3、 提高访问速度。通常,代理服务器会设置一个较大的硬盘缓冲区,当有外界的信息通过时,会同时将其保存到自己的缓冲区中,当其他用户访问相同的信息时,直接从缓冲区中取出信息,提高了访问速度。
4、隐藏真实 IP。上网者可以通过代理隐藏自己的 IP,免受攻击。对于爬虫来说,使用代理就是为了隐藏自身IP,防止自身的 IP 被封锁。
(3)爬虫代理
对于爬虫来说,由于爬取速度过快,因此在爬取过程中可能会遇到同一个 IP 访问过于频繁的问题,此时网站会让我们输入验证码登录或者直接封锁IP,这样会给爬取造成极大的不便。使用代理隐藏真实的IP,让服务器误以为是代理服务器在请求自己。这样在爬取过程中不断更换代理,就可以避免IP被封锁,达到很好的爬取效果。
(4)代理分类
对代理进行分类时,既可以根据协议,也可以根据代理的匿名程度,这两种分类方式分别总结如下。
● 根据协议区分
根据代理的协议,代理可以分为如下几类。
FTP代理服务器:主要用于访问FTP服务器,一般有上传、下载以及缓存功能,端口一般为21、2121等。
HTTP代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口一般为80、8080、3128等。
SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持128位加密强度), 端口一般为 443。
RTSP代理: 主要用于 Realplayer 访问Real 流媒体服务器,一般有缓存功能,端口一般为554。
Telnet代理:主要用于 Telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口一般为23。
POP3/SMTP 代理: 主要用于以 POP3/SMTP 方式收发邮件,一般有缓存功能,端口一般为110/25。
SOCKS代理:只是单纯传递数据包,不关心具体协议和用法,所以速度快很多,一般有缓存功能,端口一般为1080。SOCKS代理协议又分为SOCKS4和SOCKS5, SOCKS4协议只支持TCP,SOCKS5 协议则支持 TCP和UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说, SOCKS4 能做到的 SOCKS5 都能做到, 但 SOCKS5 能做到的 SOCKS4不一定做得到。
●根据匿名程度区分
根据代理的匿名程度,代理可以分为如下几类。
高度匿名代理:高度匿名代理会将数据包原封不动地转发,在服务端看来似乎真的是一个普通客户端在访问,记录的 IP 则是代理服务器的 IP。
普通匿名代理:普通匿名代理会对数据包做一些改动,服务端可能会发现正在访问自己的是个代理服务器,并且有一定概率去追查客户端的真实IP。这里代理服务器通常会加入的 HTTP头有 HTTP VIA 和HTTP X FORWARDED FOR。
透明代理:透明代理不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理除了能用缓存技术提高浏览速度,用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网中的硬件防火墙。
间谍代理:间谍代理是由组织或个人创建的代理服务器,用于记录用户传输的数据,然后对记录的数据进行研究、监控等。
(5)常见代理设置
- 对于网上的免费代理,最好使用高度匿名代理,可以在使用前把所有代理都抓取下来筛选一下可用代理,也可以进一步维护一个代理池。
- 使用付费代理服务。互联网上存在许多可以付费使用的代理商,质量要比免费代理好很多。(例:快代理(快代理 - 企业级HTTP代理IP云服务))
- ADSL拨号,拨一次号换一次IP,稳定性高,也是一种比较有效的封锁解决方案。
- 蜂窝代理,即用4G或5G网卡等制作的代理。由于用蜂窝网络作为代理的情形较少,因此整体被封锁的概率会较低,但搭建蜂窝代理的成本是较高的。
3、必须账号登录
在浏览网站的过程中,我们经常会遇到需要登录的情况,有些页面只有登录之后才可以访问。在登录之后可以连续访问很多次网站,但是有时候过一段时间就需要重新登录。还有一些网站,在打开浏览器时就自动登录了,而且在很长时间内都不会失效,这又是什么情况? 其实这里面涉及 Session 和Cookie 的相关知识。
很多页面是需要登录之后才可以查看的。按照一般的逻辑,输入用户名和密码登录网站,肯定是拿到了一种类似凭证的东西,有了这个凭证,才能保持登录状态,访问那些登录之后才能看得到的页面。这种凭证就是Session 和Cookie 共同作用产生的结果。
- 无状态HTTP
在了解Session 和Cookie 之前,我们还需要了解 HTTP的一个特点, 叫作无状态。HTTP的无状态是指 HTTP协议对事务处理是没有记忆能力的,或者说服务器并不知道客户端处于什么状态。客户端向服务器发送请求后,服务器解析此请求,然后返回对应的响应,服务器负责完成这个过程,而且这个过程是完全独立的,服务器不会记录前后状态的变化,也就是缺少状态记录。这意味着之后如果需要处理前面的信息,客户端就必须重传,导致需要额外传递一些重复请求,才能获取后续响应,这种效果显然不是我们想要的。为了保持前后状态,肯定不能让客户端将前面的请求全部重传一次,这太浪费资源了,对于需要用户登录的页面来说,更是棘手。
这时,两种用于保持HTTP连接状态的技术出现了,分别是Session 和Cookie。Session在服务端,也就是网站的服务器,用来保存用户的 Session 信息; Cookie 在客户端,也可以理解为在浏览器端,有了 Cookie,浏览器在下次访问相同网页时就会自动附带上它,并发送给服务器,服务器通过识别Cookie 鉴定出是哪个用户在访问,然后判断此用户是否处于登录状态,并返回对应的响应。
可以这样理解,Cookie 里保存着登录的凭证,客户端在下次请求时只需要将其携带上,就不必重新输入用户名、密码等信息重新登录了。
- 反反爬思路
因此在爬虫中,处理需要先登录才能访问的页面时,我们一般会直接将登录成功后获取的Cookie 放在请求头里面直接请求,而不重新模拟登录。
4、动态网页,JavaScript 压缩、 混淆和加密,加大分析难度
对于动态网页来说, 其逻辑是依赖于 JavaScript来实现的。JavaScript有如下特点。
- JavaScript代码运行于客户端,也就是它必须在用户浏览器端加载并运行。
- JavaScript代码是公开透明的,也就是说浏览器可以直接获取到正在运行的 JavaScript 的源码。
基于这两个原因,JavaScript 代码是不安全的,任何人都可以读、分析、复制、盗用甚至篡改代码。所以说,对于上述情形,客户端 JavaScript 对于某些加密的实现是很容易被找到或模拟的,了解了加密逻辑后,模拟参数的构造和请求也就轻而易举了,所以如果 JavaScript 没有做任何层面的保护的话,接口加密技术基本上对数据起不到什么防护作用。
如果你不想让自己的数据被轻易获取,不想他人了解 JavaScript 逻辑的实现,或者想降低被不怀好意的人甚至是黑客攻击的风险,那么就需要用到JavaScript 压缩、混淆和加密技术了。
- 代码压缩:去除JavaScript代码中不必要的空格、换行等内容,使源码都压缩为几行内容,降低代码的可读性,当然同时也能提高网站的加载速度。
- 代码混淆:使用变量替换、字符串阵列化、控制流平坦化、多态变异、僵尸函数、调试保护等手段,使代码变得难以阅读和分析,达到最终保护的目的。但这不影响代码的原有功能,是理想、实用的 JavaScript保护方案。
- 代码加密:可以通过某种手段将JavaScript代码进行加密,转成人无法阅读或者解析的代码,如借用WebAssembly技术, 可以直接将 JavaScript代码用C/C++ 实现, JavaScript调用其编译后形成的文件来执行相应的功能。
反反爬思路:
遇到这种情况,我们就得硬着头皮去想方设法找出其中隐含的关键逻辑了。这个过程可以成为JavaScript逆向, 这是一个较为复杂庞大的技术,后续我将另做介绍。
5、机器学习,分析爬虫行为
这种反爬技术非常的高端,但成本也高,很少网站会进行使用此种反爬手段。网站具备机器学习能力,可以自主分析出一种行为是否是爬虫行为。