做翻译网站 知乎营销技巧培训

探索GLM:一种新型的通用语言模型预训练方法
随着人工智能技术的不断进步,自然语言处理(NLP)领域也迎来了革命性的发展。OpenAI的ChatGPT及其后续产品在全球范围内引起了广泛关注,展示了大型语言模型(LLM)的强大能力。在这一背景下,GLM(General Language Model)作为一种创新的预训练语言模型,以其独特的自编码和自回归结合的训练方法,为NLP领域带来了新的视角。
GLM的核心特点
GLM模型结合了自编码和自回归两种预训练方法的优点,通过随机MASK输入中连续跨度的token,并使用自回归空白填充的方法重新构建这些跨度中的内容。此外,GLM还采用了二维编码技术,以更好地表示跨间和跨内的信息。这种独特的结合使得GLM在处理多种NLP任务时都能展现出优异的性能。
预训练目标:自回归空白填充
GLM的预训练目标是通过自回归空白填充来优化的。具体来说,给定一个输入文本,模型会从中采样多个文本片段,并将这些片段用[MASK]符号替换,形成一个损坏的文本。模型随后以自回归的方式,从损坏的文本中预测缺失的词。为了捕捉不同片段之间的相互依赖关系,GLM会随机打乱片段的顺序,类似于排列语言模型。
架构与实现
GLM的架构设计巧妙地结合了双向编码器和单向解码器。在模型的输入部分,文本被分为两部分:Part A是损坏的文本,Part B是被遮盖的片段。Part A的词可以相互看到,但不能看到Part B中的任何词;而Part B的词可以看到Part A和Part B中的前置词,但不能看到Part B中的后续词。这种设计使得模型能够在统一的框架内同时学习双向和单向的注意力机制。
GLM预训练方法分析
输入文本处理
- 输入文本:给定一个输入文本 x = [ x 1 , . . . , x n ] \bm{x} = [x_1, ..., x_n] x=[x1,...,xn],模型从中采样多个文本片段 { s 1 , . . . , s m } \{ \bm{s}_1, ..., \bm{s}_m \} {s1,...,sm}。
- 文本片段:每个片段 s i \bm{s}_i si 对应于输入文本中的一系列连续的词 [ s i , 1 , . . . , s i , l i ] [s_{i,1}, ..., s_{i,l_i}] [si,1,...,si,li]。
损坏文本的生成
- [MASK]替换:每个采样的文本片段 s i \bm{s}_i si 被一个单独的 [MASK] 符号替换,形成一个损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt。

自回归预测
- 预测方式:模型以自回归的方式从损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt 中预测缺失的词。这意味着在预测一个片段中的缺失词时,模型可以访问损坏的文本和之前已经预测的片段。
片段顺序的随机打乱
- 打乱顺序:为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
- 排列集合:令 Z m Z_m Zm 为长度为 m m m 的索引序列 [ 1 , 2 , . . . , m ] [1, 2, ..., m] [1,2,...,m] 的所有可能排列的集合。
- 片段表示:令 s z < i ∈ [ s z 1 , . . . , s z i − 1 ] \bm{s}_{z<i} \in [\bm{s}_{z_1}, ..., \bm{s}_{z_{i-1}}] sz<i∈[sz1,...,szi−1],表示在排列 z z z 中,索引小于 i i i 的片段。
GLM的预训练方法
通过自回归空白填充目标进行优化,这是一种结合了自编码和自回归特性的创新方法。下面是对这一过程的详细分析:
-
输入文本处理:
- 给定一个输入文本 x = [ x 1 , . . . , x n ] \bm{x} = [x_1, ..., x_n] x=[x1,...,xn],模型从中采样多个文本片段 { s 1 , . . . , s m } \{ \bm{s}_1, ..., \bm{s}_m \} {s1,...,sm}。
- 每个片段 (\bm{s}_i) 对应于输入文本中的一系列连续的词 [ s i , 1 , . . . , s i , l i ] [s_{i,1}, ..., s_{i,l_i}] [si,1,...,si,li]。
-
损坏文本的生成:
- 每个采样的文本片段 s i \bm{s}_i si被一个单独的 [MASK] 符号替换,形成一个损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt。
-
自回归预测:
- 模型以自回归的方式从损坏的文本 (\bm{x}_{\text{corrupt}}) 中预测缺失的词。这意味着在预测一个片段中的缺失词时,模型可以访问损坏的文本和之前已经预测的片段。
-
片段顺序的随机打乱:
- 为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
$$ - 令 (Z_m) 为长度为 (m) 的索引序列 ([1, 2, …, m]) 的所有可能排列的集合。
- 令 s z < i ∈ [ s z 1 , . . . , s z i − 1 ] \bm{s}_{z<i} \in [\bm{s}_{z_1}, ..., \bm{s}_{z_{i-1}}] sz<i∈[sz1,...,szi−1],表示在排列 (z) 中,索引小于 (i) 的片段。
- 为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
-
预训练目标函数:
- 预训练目标函数可以表示为最大化期望,即最大化模型在所有可能的片段排列下预测缺失词的对数概率之和。
- 数学表达式为:
max θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x corrupt , s z < i ) ] \underset{\theta}{\text{max}} \space \mathbb{E}_{z\sim Z_m} \left[ \sum_{i=1}^{m} \text{log} \space p_{\theta} \left( \bm{s}_{z_i} | \bm{x}_{\text{corrupt}}, \bm{s}_{z_{<i}} \right) \right] θmax Ez∼Zm[i=1∑mlog pθ(szi∣xcorrupt,sz<i)] - 这里, p θ ( s z i ∣ x corrupt , s z < i ) p_{\theta} \left( \bm{s}_{z_i} | \bm{x}_{\text{corrupt}}, \bm{s}_{z_{<i}} \right) pθ(szi∣xcorrupt,sz<i) 表示在给定损坏的文本和之前预测的片段条件下,模型预测当前片段 s z i \bm{s}_{z_i} szi 的概率。
按照从左到右的顺序生成每个空白中的词,即生成片段 s i \bm{s}_i si 的概率可以分解为:
p θ ( s i ∣ x corrupt , s z < i ) = ∏ j = 1 l i p ( s i , j ∣ x corrupt , s z < i , s i , < j ) (2) p_{\theta}\left( \bm{s}_i|\bm{x}_{\text{corrupt}},\bm{s}_{z_{<i}} \right) = \prod_{j=1}^{l_i}p\left( s_{i,j}|\bm{x}_{\text{corrupt}},\bm{s}_{z_{<i}},\bm{s}_{i,<j} \right) \tag{2} pθ(si∣xcorrupt,sz<i)=j=1∏lip(si,j∣xcorrupt,sz<i,si,<j)(2)
使用以下方式实现了自回归空白填充目标。
输入 x \bm{x} x 被分成两部分:Part A 是损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt,Part B 是被遮盖的片段。Part A 的词可以相互看到,但不能看到 Part B 中的任何词。Part B 的词可以看到 Part A 和 Part B 中的前置词,但不能看到 Part B 中的后续词。为了实现自回归生成,每个片段都用特殊的符号 [START] 和 [END] 进行填充,分别用于输入和输出。这样,模型就自动地在一个统一的模型中学习了一个双向编码器(用于 Part A)和一个单向解码器(用于 Part B)。
在GLM模型中,原始文本 x = [ x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ] \bm{x} = [x_1, x_2, x_3, x_4, x_5, x_6] x=[x1,x2,x3,x4,x5,x6] 被随机地进行连续的掩码处理。假设我们掩码掉了 [ x 3 ] [x_3] [x3] 和 [ x 5 , x 6 ] [x_5, x_6] [x5,x6],这些跨度的长度遵循泊松分布(参数 λ = 3 \lambda = 3 λ=3),这一策略与BART模型相似。

具体操作是将 [ x 3 ] [x_3] [x3] 和 [ x 5 , x 6 ] [x_5, x_6] [x5,x6] 替换为特殊的 [M] 标志,代表 [MASK]。接着,我们将这些被掩码的片段(Part B)的顺序打乱,以捕捉跨度之间的内在联系。这种随机交换跨度顺序的做法有助于模型学习到更丰富的上下文信息。
GLM模型采用自回归的方式来生成Part B的内容。在输入时,每个片段前面会加上 [S] 标志,代表 [START],而在输出时,每个片段后面会加上 [E] 标志,代表 [END]。这种做法有助于模型明确每个片段的开始和结束。
为了更好地表示不同片段之间以及片段内部的位置关系,GLM引入了二维位置编码。这种编码方式使得模型能够更精确地理解文本的结构和语义。
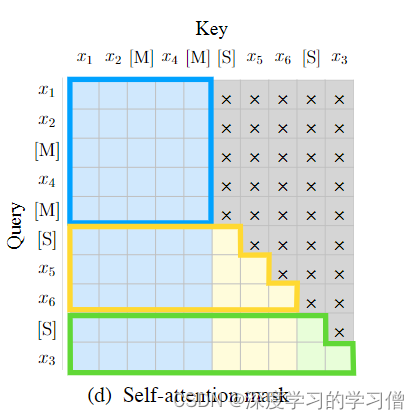
在自注意力机制中,使用了特定的掩码策略。灰色区域表示被掩盖的部分。Part A的词语可以相互看到(如图2(d)中的蓝色框所示),但不能看到Part B中的任何内容。相反,Part B的词语可以看到Part A和Part B中位于它们之前的词语(如图2(d)中的黄色和绿色框所示,分别对应两个不同的片段)。这种设计确保了模型在生成文本时能够考虑到正确的上下文信息。
通过这种方式,GLM模型不仅能够学习到文本中的上下文信息,还能够捕捉到不同文本片段之间的复杂依赖关系,从而在多种NLP任务中展现出优异的性能。这种结合了自编码和自回归特性的预训练方法,为语言模型的预训练提供了新的思路和方法。
GLM模型架构与微调方法分析
模型架构
GLM采用了一个单一的Transformer架构,并对其进行了一些关键的修改:
- 层归一化和残差连接的重新排列:这种调整对于避免大规模语言模型中的数值错误至关重要。
- 单一的线性层用于输出词预测:简化了输出层,提高了模型的预测效率。
- GeLU激活函数替换ReLU:GeLU(Gaussian Error Linear Unit)激活函数在许多现代神经网络模型中表现更好。
二维位置编码
GLM引入了二维位置编码,以更好地处理自回归空白填充任务中的位置信息。每个词使用两个位置ID进行编码:
- 第一个位置ID表示词在损坏文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt 中的位置。
- 第二个位置ID表示区域内的位置,Part A的词此ID为0,Part B的词此ID从1到区域长度。
这种编码方法确保模型在重建被遮盖的跨度时不知道其长度,与其他模型如XLNet和SpanBERT相比,这是一个显著的区别。
微调GLM
NLU分类任务
GLM将自然语言理解(NLU)分类任务重新制定为填空生成任务,遵循PET(Pattern Exploiting Training)方法。例如,情感分类任务可以被表述为“{SENTENCE}。这真的是 [MASK]”。标签如“positive”和“negative”分别映射到单词“good”和“bad”。
文本生成任务
对于文本生成任务,GLM可以直接应用预训练模型进行无条件生成,或者在条件生成任务上进行微调。给定的上下文构成了输入的Part A,末尾附加了一个mask符号,模型自回归地生成Part B的文本。
通过这些创新的方法和架构调整,GLM在处理各种自然语言处理任务时展现出了卓越的性能和灵活性。
应用与展望
GLM模型的出现,不仅为NLP领域提供了新的研究方向,也为实际应用带来了新的可能性。无论是在文本分类、翻译、问答还是文本生成等任务中,GLM都展现出了其独特的优势。随着模型的进一步优化和应用场景的拓展,GLM有望在未来的AI领域中扮演更加重要的角色。
总之,GLM作为一种结合了自编码和自回归优点的预训练语言模型,为NLP领域带来了新的活力。通过其独特的预训练方法和架构设计,GLM在多个NLP任务中都展现出了卓越的性能,预示着其在未来的广阔应用前景。