web前端网站开发实例地推放单平台
多年来,我们一直在使用 Vector 在我们的 Kubernetes 平台中收集日志,并成功地将其应用于生产中以满足各种客户的需求,并且非常享受这种体验。因此,我想与更大的社区分享它,以便更多的 K8s 运营商可以看到潜力并考虑他们自己的设置的好处。
为此,我将首先简要回顾一下 Kubernetes 中可以收集哪些类型的信息。然后,我将探讨 Vector、它的架构以及我们为什么如此喜欢它。最后,我将分享我们对 Vector 的实际用例和实际经验。
Kubernetes 中的日志记录
让我们看一下 Kubernetes 中的日志。虽然 Kubernetes 的主要目标是在节点上运行容器,但必须记住,这些容器通常是根据 Heroku 的 12 个因素开发的。那么,他们如何在 Kubernetes 中生成日志,谁是其他生产者,日志驻留在何处?
1. 应用程序(pod)日志
在 K8s 中运行的应用程序将其日志写入 stdout 或 .然后,容器运行时收集这些日志并将其存储在一个目录中,该目录通常为 stderr/var/log/pods.它是可配置的,可以根据特定要求进行定制。

2. 节点服务日志
最重要的是,Kubernetes 节点上有一些服务在容器外部运行,例如 containerd 和 kubelet。
牢记这些服务并从 syslog 中收集相关消息(例如 SSH 身份验证消息)至关重要。
此外,在某些情况下,容器会将其日志写入特定的文件路径。例如,kube-apiserver,它通常会写入审计日志。因此,需要从相应的节点收集这些日志。
3. Events
Kubernetes 日志收集的另一个重要方面是事件。它们具有独特的结构,因为它们仅存在于 etcd 中,因此为了收集它们,您必须向 Kubernetes API 发出请求。
由于 reason 字段(请参阅下面的示例清单)和 count 字段(用作计数器,随着记录的事件越来越多而递增),因此可以将事件视为指标。
此外,还可以将事件收集为跟踪、特征和字段,这有助于创建全面的甘特图,以说明集群中的所有事件。firstTimestamp lastTimestamp
最后,事件提供人类可读的消息(字段),使它们能够作为日志收集。message
apiVersion: v1
kind: Event
count: 1
metadata:name: standard-worker-1.178264e1185b006fnamespace: default
reason: RegisteredNode
firstTimestamp: '2023-09-06T19:08:47Z'
lastTimestamp: '2023-09-06T19:08:47Z'
involvedObject:apiVersion: v1kind: Nodename: standard-worker-1uid: 50fb55c5-d97e-4851-85c6-187465154db6
message: 'Registered Node standard-worker-1 in Controller'从本质上讲,Kubernetes 可以收集 Pod 日志、节点服务日志和事件。但是,在本文中,我们将重点关注 Pod 日志和节点服务日志,因为事件需要额外的软件来抓取它们,这涉及到 Kubernetes API,因此将其扩展到我们的范围之外。
什么是 Vector
现在,让我们看看 Vector 是怎么回事。
Vector 显著特征(以及我们使用它的原因)
根据官方网站的说法,Vector 是一个“用于构建可观测性管道的轻量级、超快速工具”。但是,作为 Vector 用户,我想稍微改写一下这个定义,强调与我们的情况最相关的功能:
Vector 是一个开源的高效工具,用于构建日志收集管道。
对我们来说,这个定义中有什么重要意义?
- 开源是我们必须在其上构建可信的、持久的解决方案并将其推荐给其他人的必要条件。
- 另一个重要因素是 Vector 的效率。如果一个工具是轻量级的,但不能处理大量数据,它就不能满足我们的要求。同样,如果一个工具速度超快,但消耗大量资源,它也不适合作为日志收集器。因此,效率起着至关重要的作用。
- 值得一提的是,Vector 收集其他类型数据的能力对我们来说并不重要,因为我们目前的重点是日志。
Vector 的一个特殊功能是其与供应商无关。尽管 Vector 归 Datadog 所有,但它与其他各种供应商的解决方案无缝集成,包括 Splunk、Grafana Cloud 和 Elasticsearch Cloud。这种灵活性确保了单个软件解决方案可以跨多个供应商使用。
Vector 提供的另一个令人愉快的好处是它消除了在 Rust 中重写 Go 应用程序以提高其性能的需要。Vector 已经是用 Rust 编写的。
此外,它被设计为高性能。这是如何实现的?Vector 具有一个 CI 系统,可以对任何提议的拉取请求运行基准测试。维护人员会严格评估新功能对 Vector 性能的影响。如果出现任何不利影响,请贡献者及时纠正问题,因为性能仍然是 Vector 团队的首要任务。
此外,Vector 是一个灵活的构建块,我们将在下面详细介绍。
Vector 的架构
作为一种处理工具,Vector 从各种来源收集数据。它通过抓取或充当 HTTP 服务器来积累其他工具摄取的数据来做到这一点。
Vector 擅长转换日志条目,可以将多条消息修改、删除或聚合为一条消息。(不要被下面架构图中所示的转换数量所迷惑,它提供了更多功能。
在此转换之后,Vector 处理消息并将其转发到存储或队列系统。

Vercor 架构:收集日志、转换日志并发送日志
简而言之,Vector 包含一种强大的转换语言,称为矢量重映射语言 (VRL),允许无限数量的可能转换。
矢量重映射语言示例
让我们快速浏览一下 VRL,然后从日志过滤开始。在下面的代码片段中,我们使用 VRL 表达式来确保 severity 字段不等于 :info
[transforms.filter_severity]
type = "filter"
inputs = ["logs"]
condition = '.severity != "info"'当 Vector 收集 Pod 日志时,它还会使用其他 Pod 元数据(例如 Pod 名称、Pod IP 和 Pod 标签)来丰富日志行。但是,在 Pod 标签中,可能有一些标签只有 Kubernetes 控制器使用,因此对人类用户没有价值。为了获得最佳存储性能,我们建议删除以下标签:
[transforms.sanitize_kubernetes_labels]
type = "remap"
inputs = ["logs"]
source = '''if exists(.pod_labels."controller-revision-hash") {del(.pod_labels."controller-revision-hash")}if exists(.pod_labels."pod-template-hash") {del(.pod_labels."pod-template-hash")}
'''下面是如何将多个日志行连接成一行的示例:
[transforms.backslash_multiline]
type = "reduce"
inputs = ["logs"]
group_by = ["file", "stream"]
merge_strategies."message" = "concat_newline"
ends_when = '''matched, err = match(.message, r'[^\\]$');if err != null {false;} else {matched;}
'''
在本例中,该字段将向消息字段添加换行符。最重要的是,该部分使用 VRL 表达式来检查一行是否以反斜杠结尾(以连接多行 Bash 注释的方式)。merge_strategies ends_when
日志收集拓扑
好了,是时候探索几种不同的日志收集拓扑以用于 Vector 了。第一种是分布式拓扑,其中 Vector 代理部署在 Kubernetes 集群中的所有节点上。然后,这些代理收集、转换日志并将其直接发送到存储。
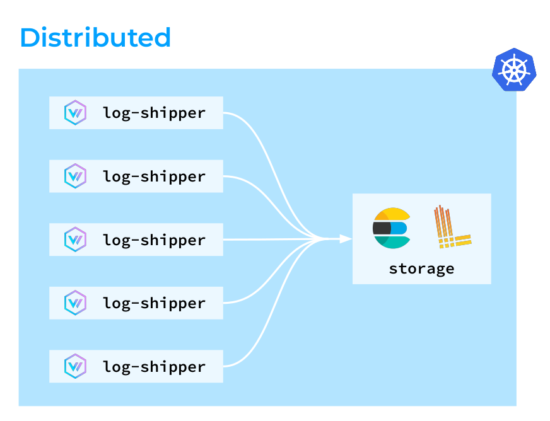
第二个是集中式拓扑。在其中,Vector 代理也在所有节点上运行,尽管它们不执行任何复杂的转换:聚合器会处理这些转换。这种设置的好处是其出色的负载可预测性。您可以为聚合器部署专用节点,并在必要时对其进行扩展,从而优化 Vector 在集群节点上的资源消耗。

第三种拓扑是基于流的方法。在其中,Kubernetes Pod 会尽快“摆脱”日志。日志被直接摄取到存储中,然后 Elasticsearch 解析日志行并调整索引,这可能是一个占用大量资源的过程。尽管如此,在 Kafka 的案例中,消息被简单地视为字符串。因此,我们可以轻松地从 Kafka 中检索这些日志,以便进一步存储和分析。
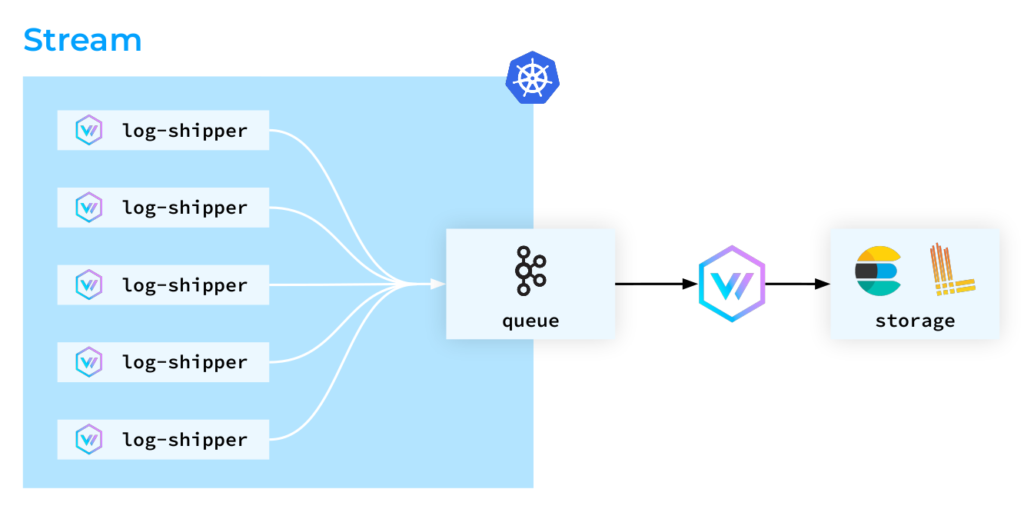
请注意,在本文中,我们不会介绍 Vector 充当聚合器的拓扑结构。相反,我们将只关注它作为群集节点上的日志收集代理的角色。
Kubernetes 中的 Vector
我们将如何看待 Kubernetes 中的 Vector?让我们看一下下面的 pod:

Kubernetes 部署为 DaemonSet 后的 Vector 容器
这样的设计乍一看可能很复杂,但这背后是有原因的。我们在这个 pod 中有三个容器:
- 第一个运行 Vector 本身。其主要目的是收集日志。
- 第二个容器称为 Reloader,使我们的平台用户能够创建自己的日志收集和引入管道。我们有一个特殊的运算符,它假设用户定义的规则并为 Vector 生成配置映射。Reloader 容器验证该配置映射并相应地重新加载 Vector。
- 第三个容器 Kube RBAC 代理起着至关重要的作用,因为 Vector 公开了有关其收集的日志行的各种指标。由于此信息可能是敏感的,因此必须通过适当的授权对其进行保护。
Vector 被部署为 DaemonSet(参见下面的列表),因为我们必须在 Kubernetes 集群中的所有节点上部署它的代理。
为了有效地收集日志,我们需要将额外的目录挂载到 Vector 中:
- 目录,因为如前所述,所有 Pod 的日志都存储在那里。
/var/log - 最重要的是,我们需要将一个持久卷挂载到 Vector 中,用于存储检查点。每次 Vector 发送日志行时,它都会写入一个检查点,以避免重复发送到同一存储的日志。
- 此外,我们挂载 以查看节点的时区。
localtime
apiVersion: apps/v1
kind: DaemonSet
volumes:
- name: var-loghostPath:path: /var/log/
- name: vector-data-dirhostPath:path: /mnt/vector-data
- name: localtimehostPath:path: /etc/localtime
volumeMounts:
- name: var-logmountPath: /var/log/readOnly: true
terminationGracePeriodSeconds: 120
shareProcessNamespace: true关于此列表的其他一些说明:
- 挂载目录时,请务必记住启用该模式。此预防措施可防止未经授权修改日志文件。
/var/logreadOnly - 我们使用终止宽限期(120 秒)来确保 Vector 在重新启动之前完成分配给它的所有任务。
- 共享进程命名空间对于使 Reloader 能够向 Vector 发送信号以重新启动它至关重要。
这总结了我们在 Kubernetes 中部署 Vector 的设置。
接下来,让我们继续讨论最有趣的部分——实际用例。所有这些都不是假设的场景——它们是我们在值班期间遇到的真实世界的停电。
实际用例
案例 #1:设备空间不足
有一天,由于磁盘空间不足,所有 Pod 都被逐出节点。我们展开了调查,发现 Vector 实际上保留了已删除的文件。现在,为什么会这样?
- Vector 监视目录中的文件。
/var/log/pods - 当应用程序主动写入日志时,文件大小会超过 10 兆字节的限制,达到 20、30、40、50......兆 字节。
- 在某些时候,kubelet 会轮换日志文件,使其恢复到原始大小 10 MB。
- 然而,与此同时,Vector 试图将日志发送给 Loki。不幸的是,Loki 无法处理如此大量的数据!
- Vector 作为一个负责任的软件,仍然打算将所有日志发送到存储中。
不幸的是,应用程序不会等待所有这些内部操作完成,它们只是继续运行。这导致 Vector 尝试保留所有日志文件,并且随着 kubelet 继续轮换它们,节点上的可用空间会耗尽。

那么,如何解决这个问题呢?
- 首先,您可以从调整缓冲区设置开始。默认情况下,如果 Vector 无法将所有日志发送到存储,则会将其存储在内存中。默认缓冲区容量限制为仅 1000 条消息,这是相当低的。您可以将其扩展到 10000。
- 或者,将行为从阻止更改为删除新日志也可能有所帮助。通过该行为,Vector 将简单地丢弃其缓冲区中无法容纳的任何日志。
drop newest - 另一种选择是使用磁盘缓冲区而不是内存缓冲区。不利的一面是 Vector 会花费更多时间在输入输出操作上。在这种情况下,在决定此方法是否适合您时,必须考虑性能要求。
消除此问题的经验法则是采用流拓扑。通过允许日志尽快离开节点,可以降低生产应用程序中断的风险。我们当然不想因为监控问题而毁掉生产集群,不是吗?
最后,如果你足够勇敢,你可以用它来调整一个进程的最大打开文件数。但是,我不推荐这种方法。sysctl
案例#2:Prometheus “爆炸”
Vector 在一个节点上运行并执行几个不同的任务。它从 Pod 收集日志,并公开收集的日志行数和遇到的错误数等指标。这要归功于 Vector 卓越的可观测性功能。
但是,许多指标都有特定的文件标签,这可能会导致高基数,这是 Prometheus 无法消化的。这是因为当 Pod 重新启动时,Vector 开始公开新 Pod 的指标,同时仍保留旧 Pod 的指标,这意味着这些指标具有不同的文件标签。此行为是 Prometheus 导出器工作方式(按设计)的结果。不幸的是,在几个吊舱重新启动后,这种情况导致普罗米修斯的负载突然激增,随后发生了“爆炸”。
为了解决这个问题,我们应用了一个指标标签规则来消除麻烦的文件标签。这解决了 Prometheus 的问题——它现在运行正常。
然而,一段时间后,Vector 遇到了自己的问题。问题是,Vector 消耗了越来越多的内存来存储所有这些指标,导致内存泄漏。为了纠正这个问题,我们在 Vector 中使用了一个全局选项,称为:expire_metric_secs
- 如果将其设置为 60 秒,Vector 将检查它是否仍在从这些 pod 收集数据。
- 否则,它将停止导出这些文件的指标。
尽管此解决方案有效运行,但它也影响了其他一些指标,例如 Vector 组件错误指标。如下图所示,最初记录了 7 个错误,但在触发过期后,数据中出现了差距。

不幸的是,Prometheus,尤其是 PromQL 函数(和类似函数),无法处理这样的数据差距。相反,Prometheus 希望指标在整个时间段内公开。rate
为了解决这个限制,我们修改了 Vector 的代码,以完全消除文件标签——只需删除几个地方的“文件”条目即可。事实证明,此解决方法已成功解决该问题。
案例 #3:Kubernetes 控制平面中断
有一天,我们注意到当 Vector 实例同时重启时,Kubernetes 控制平面往往会失败。在分析我们的仪表板后,我们确定这个问题源于过度的内存使用,主要是 etcd 内存消耗。

为了更好地理解根本原因,我们首先需要深入研究 Kubernetes API 的内部工作原理。
当 Vector 实例启动时,它向 Kubernetes API 发出请求,以使用 Pod 元数据填充缓存。如前所述,Vector 依赖于此元数据来丰富日志条目。LIST

因此,每个 Vector 实例都请求 Kubernetes API 为 Vector 运行的同一节点上的 Pod 提供元数据。但是,对于每个单独的请求,Kubernetes API 都会从 etcd 读取。
etcd 用作键值数据库。键由资源的种类、命名空间和名称组成。对于节点上涉及 110 个 Pod 的每个请求,Kubernetes API 都会访问 etcd 并检索所有 Pod 的数据。这会导致 kube-apiserver 和 etcd 的内存使用量激增,最终导致它们失败。
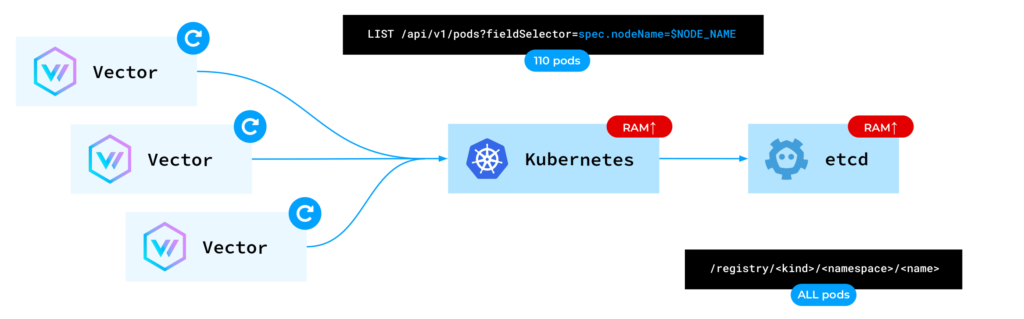
此问题有两种可能的解决方案。首先,我们可以采用缓存读取方法。在这种方法中,我们指示 API 服务器从其现有的缓存中读取数据,而不是从 etcd 中读取数据。尽管在某些情况下可能会出现不一致,但这对于监视工具来说是可以接受的。不幸的是,这样的功能在 Kubernetes Rust 客户端中不可用。因此,我们向 Vector 提交了一个拉取请求,启用了该选项。use_apiserver_cache=true
第二种解决方案涉及利用 Kubernetes 优先级和公平性 API 的独特功能。问题是,你可以定义一个请求队列:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:name: limit-list-custom
spec:type: Limitedlimited:assuredConcurrencyShares: 5limitResponse:queuing:handSize: 4queueLengthLimit: 50queues: 16type: Queue...并将其与特定服务帐户相关联:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:name: limit-list-custom
spec:priorityLevelConfiguration:name: limit-list-customdistinguisherMethod:type: ByUserrules:- resourceRules:- apiGroups: [""]clusterScope: truenamespaces: ["*"]resources: ["pods"]verbs: ["list", "get"]subjects:- kind: ServiceAccountserviceAccount:name: ***namespace: ***通过此类配置,您可以限制并发预检请求的数量,并有效降低峰值的严重性,从而最大程度地减少其影响。
最后,您可以使用 kubelet API 通过向 /pods 端点发送请求来获取 Pod 元数据,而不是依赖 Kubernetes API。但是,此功能尚未在 Vector 中实现。
结论
Vector 非常适合平台工程工作,因为它具有灵活性、多功能性和日志摄取和传输选项的广度。我全心全意地推荐 Vector,并鼓励您充分利用它的功能。