怎么查询一个网站从哪做的网站seo 优化
💓博主CSDN主页:麻辣韭菜💓
⏩专栏分类:Linux知识分享⏪
🚚代码仓库:Linux代码练习🚚
🌹关注我🫵带你学习更多Linux知识
🔝
目录
前言
一. 进程间通信介绍
1.进程间通信目的
2.进程间通信发展
3.进程间通信分类
二.管道
用fork来共享管道原理
匿名管道
进程池

前言
从进程控制篇章,我们知道了进程是具有独立性,既然各进程具有独立性,它们之间是互不联系的,那它们是怎么通过一种方式取得联系?为什么要有进程间通信?进程间通信本质是什么?
一. 进程间通信介绍
1.进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另
- 一个进程的所有陷入和异常,并能够及时知道它的状态改变。
2.进程间通信发展
- 管道
- System V进程间通信
- POSIX进程间通信
3.进程间通信分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
二.管道
管道是Linux原生能提供的,管道有两种,匿名和命名。

进程间通信的前提,是需要让不同的进程看到同一块“内存”(特定的组织结构)
所以你所谓的进程看到同一块“内存” 其实是不隶属于任何一个进程,应该更强调共享。
那如何让两个进程看到同一块“内存”?
用fork来共享管道原理


在实现之前我们需要了解一个接口函数 pipe

创建管道需要使用
pipe函数。pipe函数会返回两个文件描述符,分别代表着管道的两端。这两个文件描述符可以用于在父进程和子进程之间传输数据。pipefd[0]:读下标
pipefd[1]: 写下标
#include <iostream>
#include <sys/types.h>
#include <sys/wait.h>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <string>
#include <unistd.h>
#define N 2void Write(int fd)
{std::string str = "hello, I am child process";pid_t pid = getpid();int number = 0;char buf[1024];while (1){sleep(1);buf[0] = '\0';snprintf(buf, sizeof(buf), "%s-%d- %d\n", str.c_str(), number++, pid);write(fd, buf, strlen(buf));// std::cout <<number << std::endl;// if(number > 5)// break;}
}void Read(int fd)
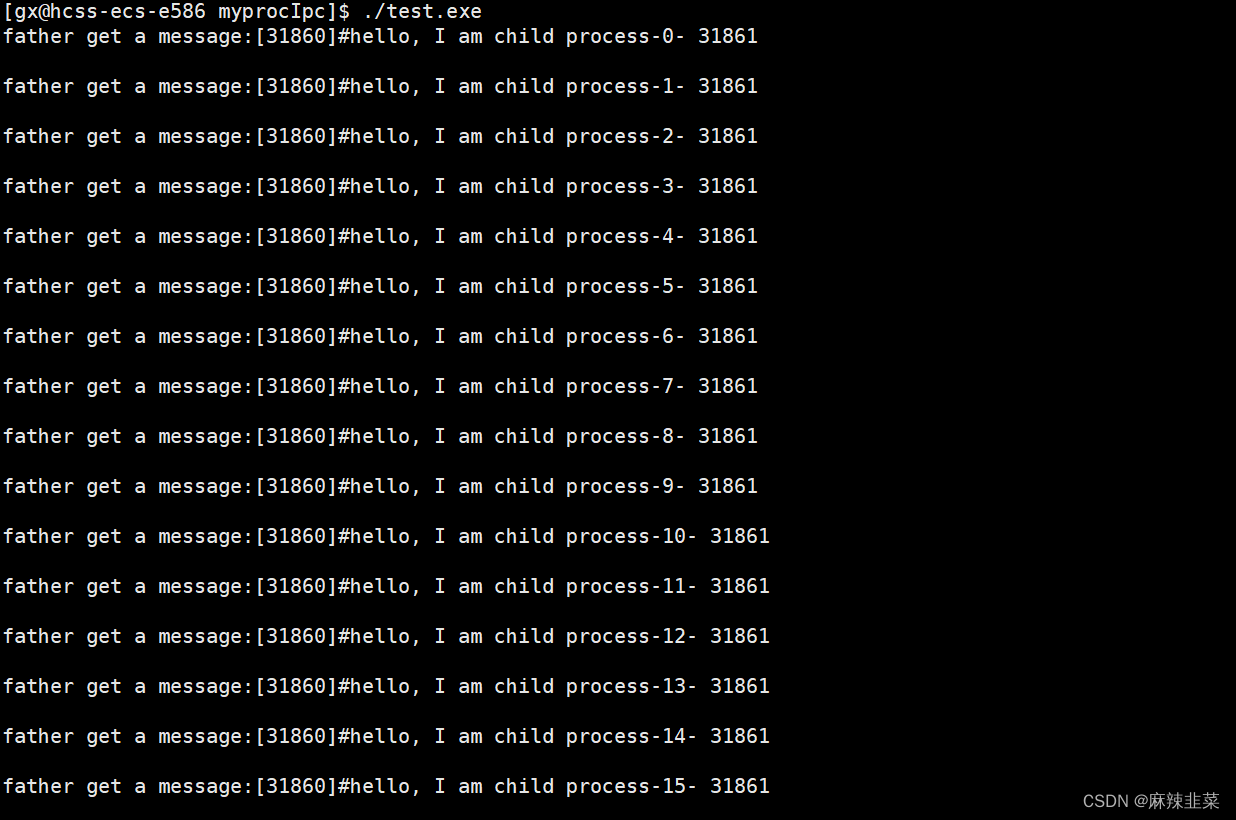
{char buf[1024];int cnt = 0;while (1){memset(buf, 0, sizeof(buf));size_t n = read(fd, buf, sizeof(buf));if (n > 0){std::cout << "father get a message:[" << getpid() << "]#" << buf << std::endl;}else if (n == 0){printf("father read file done\n");break;}else{std::cout << "father read error" << std::endl;break;}cnt++;if (cnt > 5)break;}
}int main()
{int pipefd[N];int n = pipe(pipefd);if (n < 0){std::cout << "pipe error" << std::endl;return 1;}pid_t pid = fork();if (pid < 0){std::cout << "fork error" << std::endl;}else if (pid == 0){// child processclose(pipefd[0]);Write(pipefd[1]);close(pipefd[1]);exit(0);}else{// parent processRead(pipefd[0]);close(pipefd[0]);// wait child processstd::cout << "father close read fd: " << pipefd[0] << std::endl;sleep(5); // wait child process exitpid_t status = 0;pid_t child_pid = waitpid(pid, &status, 0);if (child_pid < 0){std::cout << "waitpid error" << std::endl;return 2;}std::cout << "wait child success: " << child_pid << " exit code: " << ((status >> 8) & 0xFF)<< " exit signal: " << (status & 0x7F) << std::endl;}sleep(3); // wait father process exitreturn 0;
}运行代码
管道的特征:
1.具有血缘关系的进程才能进行进程间通信
2.管道只能单向通信
3.父子进程是会进程协同的,同步与互斥——保护管道内数据。
4.管道是面向字节流的 ps:这个我们后面网络在讲
5.管道是基于文件的,而文件的生命周期是随进程的。
下面我们就来挖一挖细节,基于第3点特征衍生出来的管道内的4种情况
读端正常,管道内容为空,读端就要堵塞
读端正常,管道内容写满,读端就要堵塞
读端正常,写段关闭,读端就会读到0,表明读到了文件的结尾,不会阻塞
写段正常写入,读端关闭,OS就会杀掉正在写入的进程。
子进程写代码是有sleep1秒的 而父进程是没有sleep1秒 ,从视频我们可以得出父进程在等待子进程写入到管道中,上一次数据被读到,说明管道的内容空了,而子进程休眠1秒钟这期间对应父进程阻塞1秒钟。
第二种情况 我们让写段写快一点,读段慢一点休眠5秒钟 写段不休眠
读端正常,管道内容写满,读端就要堵塞
第三种情况 我们写代码的number等于5时直接break;
读端正常,写段关闭,读端就会读到0,表明读到了文件的结尾,不会阻塞
第四情况 我们让读端变量cnt == 5时,读端退出。

从第4个结论来说确实OS会杀掉进程,资源有限,都没有人读了,写入后还要写时拷贝,浪费资源。
匿名管道



从上面我们看到3个sleep的父进程是bash 那这样我们可以知道它们是有血缘关系的,
我们在shell打命令行,执行后,然后shell解释我们的命令看到两个|直接创建两个管道,然后再程序替换 然后3个sleep根据重定向原理重定向到管道中。
所以我们以前在命令行执行的管道 | 就是传说之中的匿名管道!!!
进程池
根据前面程序控制,和本节的管道知识,我们可以用fork创建多个子进程,父进程写入,子进程读取,根据读取的内容,子进程完成一些相应的事情。这些子进程就好比池子里的水,我们要用的时候直接就可以拿来用。
代码实现
#include "task.hpp"
#include <string>
#include <unistd.h>
#include <cstdlib>#define ProcessNum 5 // 进程个数// 先描述
class channle
{
public:channle(int cmdfd, int slaverid, const std::string &processname): _cmdfd(cmdfd), _slaverid(slaverid), _processname(processname){}public:int _cmdfd; // 发送任务的文件描述符pid_t _slaverid; // 子进程的PIDstd::string _processname; // 子进程的名字
};
对于一个进程池来说,进程多了,我们肯定是要管理起来的,所以定义一个对象方面我们管理,对象定义出来了后,我们就要创建管道和子进程。
void InitProcessPool(std::vector<channel> *channels)
{std::vector<int> oldfds;for (int i = 0; i < ProcessNum; i++){// 创建管道int pipefd[2];int n = pipe(pipefd);if (n < 0){perror("pipe");exit(1);}// 创建子进程pid_t id = fork();if (id < 0){perror("fork");exit(2);}else if (id == 0){ // 子进程for (auto fd : oldfds) //关闭之前继承下来的写端{close(fd);}close(pipefd[1]); // 子进程读,关闭写端。dup2(pipefd[0], 0); // 管道的读端替换成标准输入0close(pipefd[0]);slaver();exit(0);}else{// 父进程close(pipefd[0]); // 父进程写,关闭读端。// 添加channle字段std::string name = "process-" + std::to_string(i);channels->push_back(channel(pipefd[1], id, name)); // 利用零时对象初始化oldfds.push_back(pipefd[1]); // 子进程会继承父进程的写端 方便我们在fork之后关闭写端}}
}我们再写个Debug测试一下。
void Debug(const std::vector<channel> &channels)
{for (auto &it : channels){std::cout << it._cmdfd << ' ' << it._slaverid << ' ' << it._processname << std::endl;}
}int main()
{std::vector<channel> channels;InitProcessPool(channels);Debug(channels);return 0;
}

5个子进程创建完毕。那么下一步就是通过cmdfd这个文件描述符父进程写入,子进程读取
我们可以用dup2,我们从键盘读入输入的内容,从管道读取。这样做的好处就是slaver这个函数不用传参
else if (id == 0){ // 子进程close(pipefd[1]); // 子进程读,关闭写端。dup2(pipefd[0],0) //管道的读端替换成标准输入0slaver();exit(0);}slaver这个函数就是获取任务的函数,怎么获取系统调用read获取,我们通过dup2原本是从标准输入读取,现在从管道里读取。 然后执行相应的任务
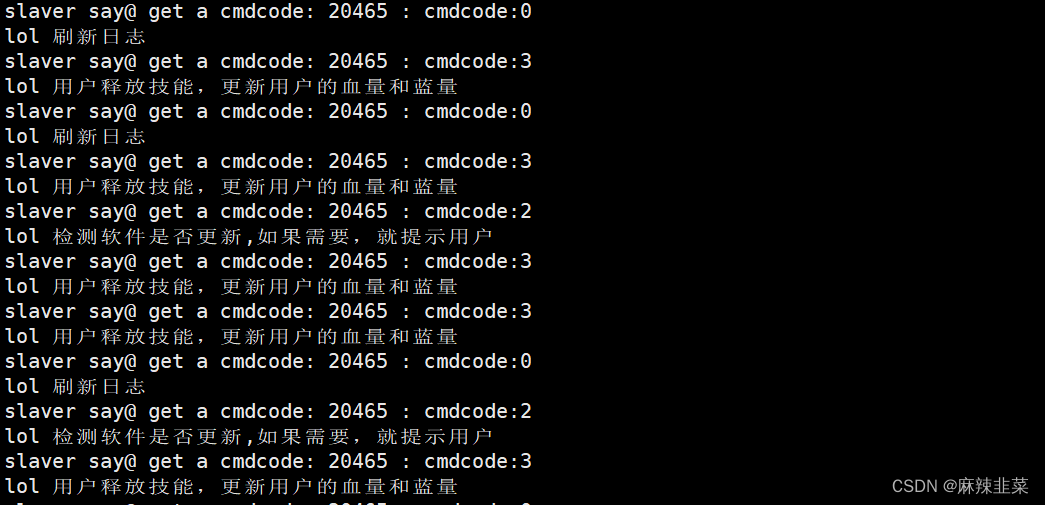
void slaver()
{int cmdcode = 0;while (true){int n = read(0, &cmdcode, sizeof(int));if (n == sizeof(int)){std::cout << "slaver say@ get a cmdcode: " << getpid() << " : cmdcode:" << cmdcode << std::endl;if (cmdcode > = 0 && cmdcode < task.size())task.[cmdcode]();}if (n == 0)break;}
}#pragma once
#include <vector>
#include <iostream>typedef void (*task_t)();void task1()
{std::cout << "lol 刷新日志" << std::endl;
}
void task2()
{std::cout << "lol 更新野区,刷新出来野怪" << std::endl;
}
void task3()
{std::cout << "lol 检测软件是否更新,如果需要,就提示用户" << std::endl;
}
void task4()
{std::cout << "lol 用户释放技能,更新用户的血量和蓝量" << std::endl;
}void LoadTask(std::vector<task_t> *tasks)
{tasks->push_back(task1);tasks->push_back(task2);tasks->push_back(task3);tasks->push_back(task4);
}现在还有没有任务,我们可以写一个简单的函数把函数的指针放进vector这个容器中然后根据cmdcode下标访问进行函数调用。
有了任务列表我们就要派发任务,这里博主选择随机派发任务,当然你下去实现的时候可以选择轮循方式派发任务。
void ctrlSlaver(const std::vector<channel> &channels)
{while (true){std::cout << "Please Enter@ ";// 1. 选择任务int cmdcode = rand() % tasks.size();// 2. 选择进程int processpos = rand() % channels.size();std::cout << "father say: "<< " cmdcode: " << cmdcode << " already sendto " << channels[processpos]._slaverid << " process name: "<< channels[processpos]._processname << std::endl;// 3. 发送任务write(channels[processpos]._cmdfd, &cmdcode, sizeof(cmdcode));// sleep(1);}
} 
最后我们还再利用wiatpid这个函数回收子进程
void QuitProcess(const std::vector<channel> &channels)
{for (const auto &c : channels){close(c._cmdfd);waitpid(c._slaverid, nullptr, 0);}
}