池州哪里有做网站精准客户信息一条多少钱
前沿
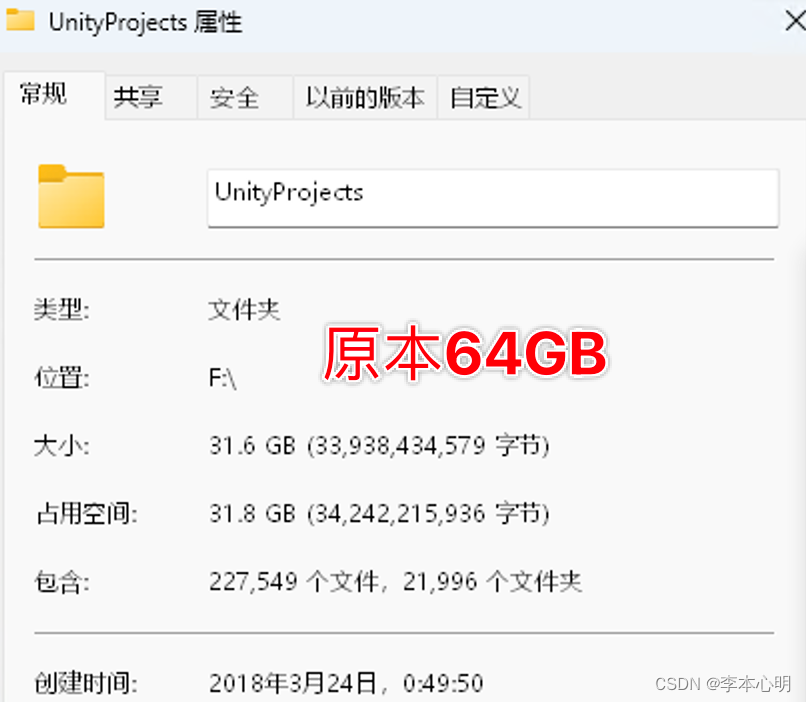
1. Unity工程越来越多,很久不用的工程里存在了很多无用的大文件夹,极大的影响电脑容量。
2. 我电脑里面U3D工程只有17个,但容量就高达60GB,使用自己编写的工具清理后,减到了30GB多。清理了不是很重要的文件和文件夹,保留了关键的工程文件。这样减少了电脑的容量,又保证Unity工程的不损坏。当然这个清理工具是针对很久不用的一些工程。
3. 在清理你的文件时,不会直接对其进行删除,而是放到回收站。 所以防止删除了你自定义的其他文件,建议运行程序后,请打开回收站,稍微过一遍,看一下是否有重要的文件,有的话还是需要还原的。
4. 关于如何使用,请百度怎么运行Python文件。
代码以及关键功能
- Print颜色化输出
- 自动获取脚本当前目标,判断是原python还是打包后的文件。防止删除的时候把自己也删除了。
- 自动对输入的根目录进行判断,可以对绝对路径,自身路径,自身路径的子目录进行检查。
- 自动简化路径长度,让Print输出正常。但同时会减少文件夹的可识别性。
- 可以检查脚本所在的文件夹,也可以处理子目录,默认子目录递归深度最深为5层,可以自己调节这个参数。
关键的字段
- root_path (str): 需要遍历的根目录,不能太浅,否则容易误删除文件
- target_folders (list): 目标文件夹,尽量多并且准,不然也容易雷同被删除
- protected_items (list): 删除的时候,需要保护的文件夹,或者文件
- protected_extensions (list): 对于一些有很多相同后缀的文件进行保护
- max_depth (int): 程序遍历文件夹的最大深度,默认为5
import sys
import os
from send2trash import send2trash# 定义颜色代码
WHITE = "\033[97m"
RED = "\033[91m"
YELLOW = "\033[93m"
RESET = "\033[0m"def get_program_path():# 检查程序是否被打包if getattr(sys, 'frozen', False):# 程序被打包,使用 sys.executable 获取可执行文件路径program_path = sys.executableelse:# 程序未被打包,使用 __file__ 获取当前脚本路径program_path = os.path.abspath(__file__)return program_path# 获取自身文件名
ScriptPath = get_program_path()
ScriptName = os.path.basename(ScriptPath)"""
Parameters:- root_path (str): 需要遍历的根目录,不能太浅,否则容易误删除文件- target_folders (list): 目标文件夹,尽量多并且准,不然也容易雷同被删除- protected_items (list): 删除的时候,需要保护的文件夹,或者文件- protected_extensions (list): 对于一些有很多相同后缀的文件进行保护- max_depth (int): 程序遍历文件夹的最大深度,默认为5
"""
def main():print("----------------------------------------------------------------")print(ScriptName + " 开始处理文件")#需要遍历的根目录root_path = '.' #你的目录前需要加‘r’,比如 r"F:\UnityProjects" #目标文件夹名称,对于Unity来说 "Assets"、"ProjectSettings" 和 "Packages" 是项目中最重要的文件target_folders = ["Assets","Packages","ProjectSettings"] #["a","b","c"] #需要被保护不被删除的文件或文件夹protected_items = ["Others","Python","config","UserSettings","Configs","LICENSE","user.keystore","素材","密钥",'.gitignore','.git','Server']#对于特定的后缀,直接会防止删除protected_extensions = ['.config','.htm','.txt','.gitignore','.git','.xlsx','.unitypackage', '.md', '.py', '.keystore','.jpg','.png','.jpeg','.mp4']protected_items.append(ScriptName)#校验根目录root_path = validate_and_adjust_root_path(root_path)find_and_clean_directories(root_path,target_folders,protected_items,protected_extensions)print("处理文件完成")print("----------------------------------------------------------")#识别根目录有效性并且对其进行校验
def validate_and_adjust_root_path(root_path):# 如果有效则直接返回if root_path and os.path.isdir(root_path):return root_path# 获取当前脚本所在目录self_path = os.path.dirname(ScriptPath)# 尝试将传入的 root_path 与当前脚本所在目录结合adjusted_root_path = os.path.join(self_path, root_path) if root_path else self_path# 如果组合后的路径是有效的目录,则返回该路径,否则返回当前脚本所在目录if os.path.isdir(adjusted_root_path):return adjusted_root_pathreturn self_pathSimplifyPath = {}
#对路径进行简化,隐藏过多的上级目录
def simplify_path(path, max_levels=3):global SimplifyPath # 检查路径是否已经被处理过if path in SimplifyPath:return SimplifyPath[path]# 自动检测系统的路径分隔符sep = os.path.sep# 将路径分割成单独的部分parts = path.split(sep)# 如果路径部分多于max_levels,则进行简化if len(parts) > max_levels + 1: # 加1是因为分割后第一个元素可能是空字符串(对于绝对路径)# 用".."替换多余的级别,并保留最后max_levels个级别simplified_parts = ['..'] * (len(parts) - max_levels - 1) + parts[-max_levels:]# 重新组合路径simplified_path = sep.join(simplified_parts)# 将处理结果存储在字典中SimplifyPath[path] = simplified_pathreturn simplified_pathelse:# 如果路径级别不多于max_levels,不做改变直接返回,并将结果存储在字典中#SimplifyPath[path] = pathreturn pathTotal_DelectNumber = 1
def find_and_clean_directories(root_path, target_folders, protected_items,protected_extensions, max_depth=5):#检查当前目录是否包含目标文件夹。有则进行放入回收站操作def is_match_and_clean(dir_path):global Total_DelectNumber contents = set(item.strip().lower() for item in os.listdir(dir_path)) # 将目录内容转换为小写targets = set(folder.strip().lower() for folder in target_folders)protected = set(item.strip().lower() for item in protected_items)# 检查当前目录中是否存在所有的目标文件夹(不区分大小写)if targets.issubset(contents):print(YELLOW+"第{0}轮回收准备:确定匹配的目录:{1}".format(Total_DelectNumber,simplify_path(dir_path))+RESET)# 通过删除所有非目标、非受保护的文件来清理目录trash_number = 0is_clean= Falsefor item in contents:original_item = next((orig for orig in os.listdir(dir_path) if orig.strip().lower() == item), None)if original_item and original_item.strip().lower() not in targets and original_item.strip().lower() not in protected:item_path = os.path.join(dir_path, original_item)#检查文件后缀是否否和标准_, ext = os.path.splitext(original_item)if not ext.lower() in protected_extensions:if os.path.isdir(item_path) or os.path.isfile(item_path):print(RED+"即将删除:" + simplify_path(item_path)+RESET) # 增强日志输出send2trash(item_path)trash_number += 1is_clean = Trueif is_clean : print(YELLOW+"2. 清理了{0}个文件 - 目录:{1}".format(trash_number,simplify_path(dir_path))+RESET)print(YELLOW+"-----总共清理了{0}个工程-----".format(Total_DelectNumber)+RESET)Total_DelectNumber += 1else: print(YELLOW+"3. 已经是干净的目录了:{0}".format(simplify_path(dir_path))+RESET)return Truereturn False#检查执行中的目录里面是否匹配条件,并进行匹配则回收def traverse_and_clean(dir_path, current_depth=1):if current_depth >= max_depth:return# 首先检查当前目录(dir_path)本身是否满足条件if is_match_and_clean(dir_path):returncleaned = Falsefull_path = ""for entry in os.listdir(dir_path):full_path = os.path.join(dir_path, entry)if os.path.isdir(full_path):print("检查目录:{0}".format(simplify_path(full_path)))# Check and clean the current directory if it's a matchif is_match_and_clean(full_path):cleaned = Truecontinue # break | Stop searching this level once a match is found and cleanedelse:# Recursively traverse the subdirectorytraverse_and_clean(full_path, current_depth + 1)if cleaned:# 如果对此目录进行清理了,则跳过这个级别的剩余目录returntraverse_and_clean(root_path)# find_and_clean_directories("/path/to/root", ["A", "B", "C"], ["D", "E.txt"])main()
效果展示