学做网站多久百度的客服电话是多少
正则表达式
通常用于校验 比如说qq号 看输入的是否符合规则就可以用这个
public class regex {public static void main(String[] args) {//正则表达式判断qq号是否正确//规则 6位及20位以内 0不能再开头 必须全是数子String qq="1234567890";System.out.println(qq.matches("[1-9]\\d{5,19}"));//在正则表达式中 第一个表示不能以0开头所以写了1到9满足就行 第二个//写了\\d表示全是数字就行//第三写了5到19 因为规则是6位及20位以内.正则表达式开头不算算后面 后面是5到19位}
}正则表达式还有一个作用在一段文本中查找满足要求的内容

注意一个[]大括号只匹配一个字符


下面是知识引入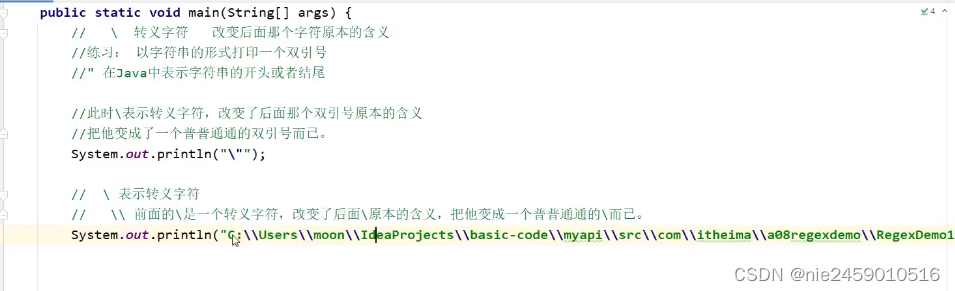
所以总结\在java中有特殊含义. 口诀:两个\才表示一个

正则表达式校验多个字符

X表示任意字符

练习
public class test {public static void main(String[] args) {//验证手机号码//拿到一个正确的数从左到右一次去写//13103719499 13103123499 13103716212//第一部分手机号码以1开头//第二个数字根据常识是3到9//第三个往后的都是任意数字String regex1="1[3-9]\\d{9}";System.out.println("13103719499".matches(regex1));//trueSystem.out.println("13103123499".matches(regex1));//trueSystem.out.println("131037162121".matches(regex1));//falseSystem.out.println("_____________________");//座机号码//020-2324252 02122442 027-42423 0712-3242434//思路//以0开头//后面是任意数字两位或者三位//-是只能出现1次或0次 用?表示//号码不能以0开头 所以携程[1-9]//最后面是任意数字 号码总长是5到10位String regex2="0\\d{2,3}-?[1-9]\\d{4,9}";System.out.println("020-2324252".matches(regex2));System.out.println("02122442".matches(regex2));System.out.println("------------------------");//邮箱号码//3231231@qq.com zhangsan@dawd.cnn dled0011@163.com dlei12321@pci.com.cn//思路//第一部分//@左边可以是任意数字字母或者包含下划线 \w+ 这个加号表示出现一次或者多次//第二部分 @ 只能一次//第三 3.1 可以是任意数字字母或者不包含下划线[\\w&&[^_]{2,6} 出现2到6次//3.2 . \\. 第一个\是告诉java编译器的第二个\是告诉正则表达式的 因为 . 在正则表达式中有特殊含义 所以这里要转译两次//3.3 大小写字母都可以 出现 2 到3次 [a-zA-Z]{2,3}//我们把3.2 3.3 看成一组括起来让他们出现1 次或2次就组成了dlei12321@pci.com.cnString regex3="\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2}";System.out.println("3231231@qq.com".matches(regex3));System.out.println("dlei12321@pci.com.cn".matches(regex3));}}注意"\\. 第一个\是告诉java编译器的第二个\是告诉正则表达式的 因为 . 在正则表达式中有特殊含义 所以这里要转译两次
练习2
public class test2 {public static void main(String[] args) {//要求以验证用户名是否满足要求//要求 大小写字母 数字下划线一共4到16位//dawd1231_dawdString regex1="\\w{4,16}";System.out.println("daw1231_dad".matches(regex1));//判断身份证号是否满足要求//简单要求 18位 前17位是任意数字 最后一位可以是大写或者小写xString regex2="[1-9]\\d{16}(\\d|x|X)";System.out.println("410922200206061619".matches(regex2));System.out.println("41092220020606169X".matches(regex2));System.out.println("______________________");//忽略大小写的方式String regex3="(?i)abc";System.out.println("abC".matches(regex3));//trueSystem.out.println("ABC".matches(regex3));//true//身份证号码严格校验//410922 2002 0606 1619//前六位 第一位不能是0 后面5位是任意数字 [1-9]\\d{5}//年份前两位现在只有18 19 20 (18|19|20)//年后半段任意数字 \\d{2}//月份01-09 10-12 (0[1-9]|1[0-2])//日期 01-09 10-19 20-29 30 31 (0[1-9]|[12]\\d|3[01])//前三位是任意数字 最后一位可以是大小写的X \\d{3}[\\dXx]//[01]表示可以是0 也可以是1String regex4="([1-9]\\d{5})(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\\d|3[01])\\d{3}[\\dXx]";System.out.println("41092220000606161X".matches(regex4));}
}正则表达式小结
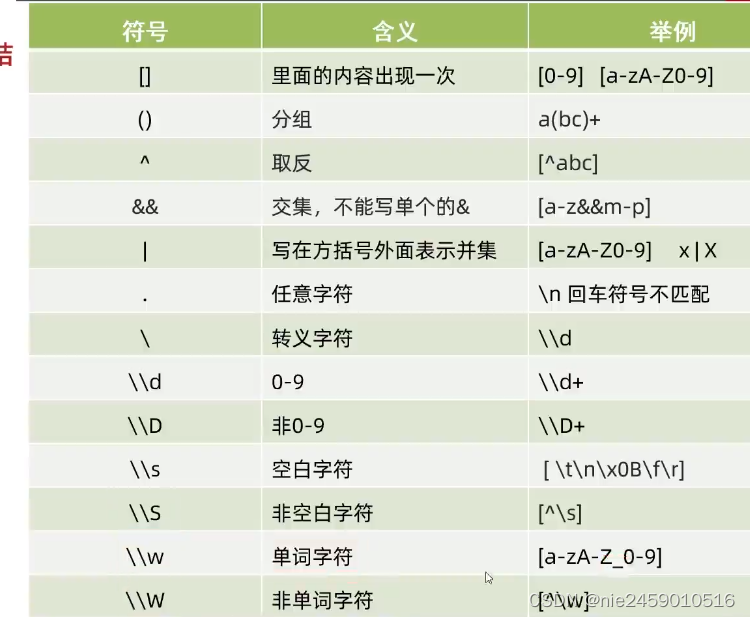
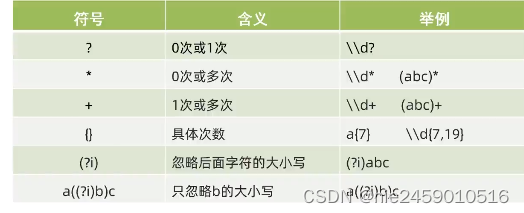
所以在java中书写\.就需要先转义\就是\\.而其他语言中就可以直接为\.
因为java编译的时候,会把两个\\看成一个\,而我们写\d,\d是特殊字符不需要转义
爬虫
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";//第一步获取正则表达式 括号里表示需要爬取的条件Pattern p = Pattern.compile("java\\d{0,2}");//用上面的爬取条件 获取文本匹配器对象//传入str是要查的文章内容//拿m读取str找到 找到符合p的子串Matcher m = p.matcher(str);//拿着文本匹配器从头开始读取找到满足规则的子串//如果没有返回false//底层记录字串的起始索引和结束索引加1//0,4 这个是boolean b = m.find();//根据find方法记录的索引进行字符串的截取//用到subString方法(起始索引,结束索引)包头不包尾 这就是为什么find最后要记录索引了//会把街区的小串返回String s = m.group();System.out.println(s);
普通写法 但是这种一次只能一个
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";//1.获取正则表达式Pattern p = Pattern.compile("Java\\d{0,2}");//2.获取文本匹配器的对象Matcher m = p.matcher(str);//3.利用循环获取while (m.find()) {//循环的意思是当find没有找完的情况下不会停止.如果没有满足条件的就会停止String s = m.group();//他会将find找的返回的索引返回字符串System.out.println(s);
循环写法
爬取网络上信息
public class internetPaQu {public static void main(String[] args) throws IOException {//爬取网络上的信息 比如是身份证号//创建一个url对象 可以理解为存网址的URL url=new URL("https://520zuowens.com/xiaoxue/1122109.html");//连接上这个网址URLConnection conn = url.openConnection();//创建一个对象读取网络中的信息BufferedReader br=new BufferedReader(new InputStreamReader(conn.getInputStream()));String line;//每次读一整行 只要没读完就不停下来while((line= br.readLine())!=null){System.out.println(line);}//br.close();}
}
接下来是待条件的读取 我只想要网址中身份证号
public class pachong2 {public static void main(String[] args) {String index = "手机号信息:13333333333 15555555555 18888888888" +"邮箱信息:12@qq.com s123@163.com sdjkaxh@pci.com.cn 400-100-3233" +"座机号码: 021-1584654 0215412111 0214511111"+"热线电话:400-618-9090,400-231-2344,4006182323";String regex = "(0\\d{2,6}-?\\d{5,20})|(\\w{1,30}@[0-9a-zA-Z]{2,20}(\\.[0-9a-zA-Z]{2,20}){1,2})" +"|(1[3-9]\\d{9})|(400-?\\d{3,9}-?\\d{3,9})|400-?[1-9]\\d{2}-?[1-9]\\d{3}";//这一步是获取正则表达式Pattern pattern = Pattern.compile(regex);
//这一步是把文本管理器读取index 根据prttern规则Matcher m = pattern.matcher(index);while(m.find()){System.out.println(m.group());}}
带条件的爬取

public static void main(String[] args) {String str ="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是JaVa8和Java11,"+"因为这两个是长期支持的版本,下一个长期支持的版本是JAva17,相信在未来不久Java17也会逐渐登上历史舞台";//需求1 爬取版本号为8 11 17的java文本 但只要java 不显示版本号//?可以理解为是java//=后边是java后面跟随的数据 但是获取的时候只要前半部分String regex1="((?i)java)(?=8|11|17)";//需求2 爬取版本号为8 11 17的java文本 需要加上后面的数字String regex2="((?i)java)(8|11|17)";//这种写法也可以还可以用占位的方法String regex21="((?i)java)(?:8|11|17)";//需求3 爬取除了 8 11 17String regex3="((?i)java)(?!8|11|17)";Pattern p = Pattern.compile(regex3);Matcher m = p.matcher(str);while(m.find()){System.out.println(m.group());}//s输出结果JaVa//Java//JAva//Java//(?i)忽略大小写}
}
在这里?相当于占位
贪婪爬取和非贪婪
贪婪爬取:爬取数据时尽可能多的爬取
贪婪爬取:爬取数据时尽可能少的爬取
String str ="Java自从95年问世以来,abbbbbbbbbbbbaaaaaaaaaaa"+"经历了很多版本,目前企业中用的最多的是JaVa8和Java11,"+"因为这两个是长期支持的版本,下一个长期支持的版本是JAva17,相信在未来不久Java17也会逐渐登上历史舞台";ab+ 加表示一个或多个 那么可以是abbbbbbbbbbbb也可以是ab
那么贪婪爬取(java默认的爬取)则是abbbbbbbbbbbb
非贪婪ab
只写+和*表示贪婪匹配 +?和*?表示非贪婪
public static void main(String[] args) {String str ="Java自从95年问世以来,abbbbbbbbbbbbaaaaaaaaaaa"+"经历了很多版本,目前企业中用的最多的是JaVa8和Java11,"+"因为这两个是长期支持的版本,下一个长期支持的版本是JAva17,相信在未来不久Java17也会逐渐登上历史舞台";String regex1="ab+";Pattern p = Pattern.compile(regex1);Matcher m = p.matcher(str);while(m.find()){System.out.println(m.group());}}//打印结果abbbbbbbbbbbb
正则表达式在字符串方法中使用

public static void main(String[] args) {//有一段字符串 小诗诗dadwdsdasda12312321小丹丹adafsge1234小惠惠//要求1 把字符串中三个名字之间的字母用vs替代//要求2 把字符串中的三个名字切割出去String regex="小诗诗dadwdsdasda12312321小丹丹adafsge1234小惠惠";//第一个传入需要代替文本的正则表达式dadwdsdasda//第二个传入需要替换成的字符 vs//底层原理他也会创见文本解析器对象 然后读取符合条件的字符 用第二个代替String result = regex.replaceAll("[\\w&&[^_]]+", "vs");System.out.println(result);//小诗诗vs小丹丹vs小惠惠//2要求2 把字符串中的三个名字切割出去//传入需要切割字符的正则表达式即可 返回值为数组String[] s = regex.split("[\\w&&[^_]]+");for (int i = 0; i < s.length; i++) {System.out.println(s[i]);}
分组

捕获分组
捕获分组就是把这一组的数据捕获出来,再用一次。
- 需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
- 举例:a123a、b456b、17891、&abc&
- 需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符
- 举例:abc123abc、b456b、123789123、&!@abc&!@
- 需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致
- 举例:aaa123aaa、bbb456bbb、111789111、&&abc&&
public static void main(String[] args) {/* 需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符* 举例:a123a、b456b、17891、&abc&*//* (.): 表示把首字符分成一组,可以出现1个任意字符.+: 表示任意字符至少出现1次\\1: 表示把第1组的内容再用1次*///拿到一个字符串 可以把他拆成3分看 然后写正则表达式 a 123 aString regex="(.).+\\1";System.out.println("a123a".matches(regex));//trueSystem.out.println("&abc&".matches(regex));//tSystem.out.println("a123b".matches(regex));//false/* * 需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符* 举例:abc123abc、b456b、123789123、&!@abc&!@*/String regex1="(.+).+\\1";//第一个(.+)表示 任意字符出现一次或者多次//第二个同上//\\1: 表示把第1组的内容再用1次 第一组就是第一个左括号的内容System.out.println("ab123ab".matches(regex1));//trueSystem.out.println("&aabc&a".matches(regex1));//tSystem.out.println("aa123ab".matches(regex1));//false/*需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致* 举例:aaa123aaa、bbb456bbb、111789111、&&abc&&*/String regex2="((.)\\2*).+\\1";//(.)表示任意字符 加上\\2表示首字符拿出来再次使用///* 表示把\\2重复0次或多次System.out.println("aaa123aaa".matches(regex2));//trueSystem.out.println("111789111".matches(regex2));//tSystem.out.println("aab123abb".matches(regex2));//false在正则表达式内部使用分组:\\组号
在正则表达式外部使用分组:$组号
练习
public static void main(String[] args) {String str="我要学学编编编编程程程程程";//学学//编编编编//程程程程程//要做的是去点重复 用方法 replaceAll//写正则表达式//(.)表示任意字符出现0次或多次 \\1表示重复第一组 +表示出现1次或多次//第二个内容$1表示要替换的内容 为第一组第一个String s = str.replaceAll("(.)\\1+", "$1");System.out.println(s);}
非捕获分组
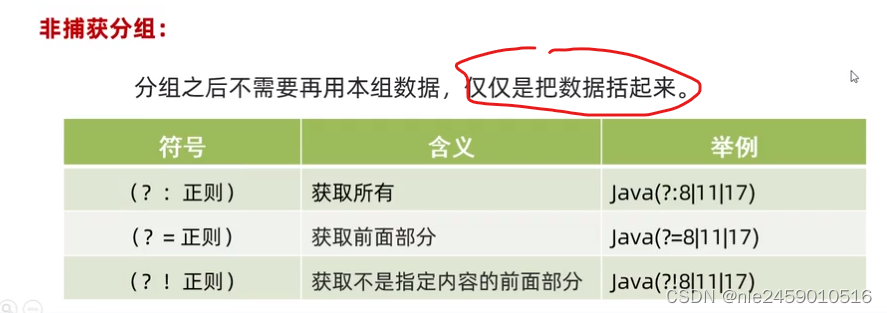
public static void main(String[] args) {/*非捕获分组:分组之后不需要再用本组数据,仅仅把数据括起来。身份证号码:41080119930228457x51080119760902230915040119810705387X430102197606046442*/// 身份证号的简易正则表达式String IDRegex = "[1-9]\\d{16}(?:\\d|X|x)";//非捕获分组 不占用组好总结
