模板做的网站不好优化网游百度搜索风云榜
web框架:
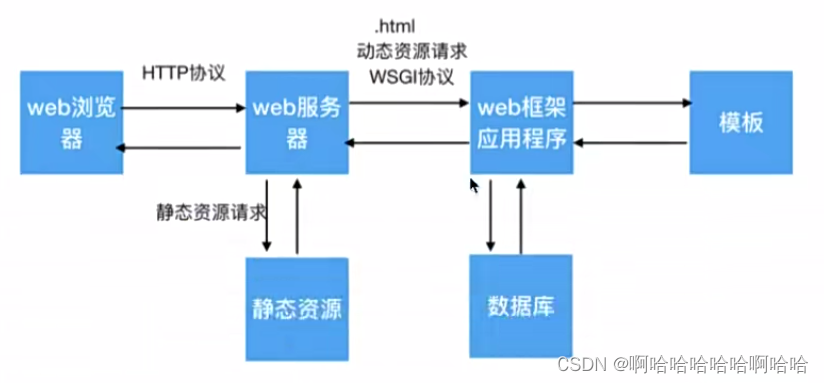
使用web框架专门负责处理用户的动态资源请求,这个web框架其实就是一个为web服务器提供服务的应用程序
什么是路由?
路由就是请求的url到处理函数的映射,也就是说提前把请求的URL和处理函数关联好
管理路由可以使用一个路由列表进行管理

web.py文件:
importsocketimportosimportthreadingimportsysimportframework#http协议的web服务器类classHttpWebServer(object):def__init__(self,port):#创建tcp服务端套接字tcp_server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#设置端口号复用,程序退出端口号立即释放tcp_server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,True)#绑定端口号tcp_server_socket.bind(("",port))#设置监听tcp_server_socket.listen(128)#把tcp服务器的套接字作为web服务器对象的属性self.tcp_server_socket=tcp_server_socket#处理客户端请求@staticmethoddefhandle_client_request(new_socket):#接收客户端的请求信息recv_data=new_socket.recv(4096)#判断接收的数据长度是否为0iflen(recv_data)==0:new_socket.close()return#对二进制数据进行解码recv_content=recv_data.decode("utf-8")print(recv_content)#对数据按照空格进行分割request_list=recv_content.split("",maxsplit=2)#获取请求的资源路径request_path=request_list[1]print(request_path)#判断请求的是否是根目录,如果是根目录设置返回的信息ifrequest_path=="/":request_path="/index.html"#判断是否是动态资源请求,以后把后缀是.html的请求任务是动态资源请求ifrequest_path.endswith(".html"):"""动态资源请求"""#动态资源请求找web框架进行处理,需要把请求参数给web框架#准备给web框架的参数信息,都要放到字典里面env={"request_path":request_path,#传入请求头信息,额外的参数可以在字典里面在进行添加}#使用框架处理动态资源请求,#1.web框架需要把处理结果返回给web服务器,#2.web服务器负责把返回的结果封装成响应报文发送给浏览器status,headers,response_body=framework.handle_request(env)print(status,headers,response_body)#响应行response_line="HTTP/1.1%s\r\n"%status#响应头response_header=""forheaderinheaders:response_header+="%s:%s\r\n"%header#响应报文response_data=(response_line+response_header+"\r\n"+response_body).encode("utf-8")#发送响应报文数据给浏览器new_socket.send(response_data)#关闭连接new_socket.close()else:"""静态资源请求"""#1.os.path.exits#os.path.exists("static/"+request_path)#2.try-excepttry:#打开文件读取文件中的数据,提示:这里使用rb模式,兼容打开图片文件withopen("static"+request_path,"rb")asfile:#这里的file表示打开文件的对象file_data=file.read()#提示:withopen关闭文件这步操作不用程序员来完成,系统帮我们来完成exceptExceptionase:#代码执行到此,说明没有请求的该文件,返回404状态信息#响应行response_line="HTTP/1.1404NotFound\r\n"#响应头response_header="Server:PWS/1.0\r\n"#读取404页面数据withopen("static/error.html","rb")asfile:file_data=file.read()#响应体response_body=file_data#把数据封装成http响应报文格式的数据response=(response_line+response_header+"\r\n").encode("utf-8")+response_body#发送给浏览器的响应报文数据new_socket.send(response)else:#代码执行到此,说明文件存在,返回200状态信息#响应行response_line="HTTP/1.1200OK\r\n"#响应头response_header="Server:PWS/1.0\r\n"#响应体response_body=file_data#把数据封装成http响应报文格式的数据response=(response_line+response_header+"\r\n").encode("utf-8")+response_body#发送给浏览器的响应报文数据new_socket.send(response)finally:#关闭服务于客户端的套接字new_socket.close()#启动服务器的方法defstart(self):#循环等待接受客户端的连接请求whileTrue:#等待接受客户端的连接请求new_socket,ip_port=self.tcp_server_socket.accept()#代码执行到此,说明连接建立成功sub_thread=threading.Thread(target=self.handle_client_request,args=(new_socket,))#设置成为守护主线程sub_thread.setDaemon(True)#启动子线程执行对应的任务sub_thread.start()defmain():##获取终端命令行参数#params=sys.argv#iflen(params)!=2:#print("执行的命令格式如下:python3xxx.py9000")#return#####判断第二个参数是否都是由数字组成的字符串#ifnotparams[1].isdigit():#print("执行的命令格式如下:python3xxx.py9000")#return#####代码执行到此,说明命令行参数的个数一定2个并且第二个参数是由数字组成的字符串#port=int(params[1])#创建web服务器web_server=HttpWebServer(8000)#启动服务器web_server.start()#判断是否是主模块的代码if__name__=='__main__':main()framework.py文件:"""web框架的职责专门负责处理动态资源请求"""importtimeroute_list=[]#定义带有参数的装饰器defroute(path):defdecorator(func):#装饰器执行的时候就需要把路由添加到路由列表里route_list.append((path,func))definner():result=func();returnresultreturninnerreturndecorator#获取首页数据@route("/index.html")defindex():#状态信息status="200OK"#响应头信息response_header=[("Server","PWS/1.1")]#1.打开指定模板文件,读取模板文件中的数据withopen("template/index.html","r",encoding='utf-8')asfile:file_data=file.read()#2.查询数据库,模板里面的模板变量替换成以后从数据库里查询的数据#web框架处理后的数据#获取当前时间,模拟数据库内容data=time.ctime()response_body=file_data.replace("{%content%}",data)#这里返回的是元组returnstatus,response_header,response_body#获取个人中心数据@route("/center.html")defcenter():#状态信息status="200OK"#响应头信息response_header=[("Server","PWS/1.1")]#1.打开指定模板文件,读取模板文件中的数据withopen("template/center.html","r",encoding='utf-8')asfile:file_data=file.read()#2.查询数据库,模板里面的模板变量替换成以后从数据库里查询的数据#web框架处理后的数据#获取当前时间,模拟数据库内容data=time.ctime()response_body=file_data.replace("{%content%}",data)#这里返回的是元组returnstatus,response_header,response_body#处理没有找到的动态资源defnot_found():#状态信息status="404NotFound"#响应头信息response_header=[("Server","PWS/1.1")]#web框架处理后的数据data="notfound"#这里返回的是元组returnstatus,response_header,data#处理动态资源请求defhandle_request(env):#获取动态的请求资源路径request_path=env["request_path"]print("动态资源请求的地址:",request_path)#判断请求的动态资源路径,选择指定的函数处理对应的动态资源请求forpath,funcinroute_list:ifrequest_path==path:result=func()returnresultelse:result=not_found()returnresult#ifrequest_path=="/index.html":##获取首页数据#result=index()##把处理后的结果返回给web服务器使用,让web服务器拼接响应报文时使用#returnresult#elifrequest_path=="/center.html":##个人中心#result=center()#returnresult#else:##没有动态资源数据,返回404状态信息#result=not_found()##把处理后的结果返回给web服务器使用,让web服务器拼接响应报文时使用#returnresultif__name__=="__main__":print(route_list)framework.py文件:
"""web框架的职责专门负责处理动态资源请求"""
import time
route_list=[]
#定义带有参数的装饰器
def route(path):def decorator(func):#装饰器执行的时候就需要把路由添加到路由列表里route_list.append((path, func))def inner():result=func();return resultreturn innerreturn decorator# 获取首页数据
@route("/index.html")
def index():# 状态信息status = "200 OK"# 响应头信息response_header = [("Server", "PWS/1.1")]# 1.打开指定模板文件,读取模板文件中的数据with open("template/index.html","r",encoding='utf-8') as file:file_data=file.read()# 2.查询数据库,模板里面的模板变量替换成以后从数据库里查询的数据# web框架处理后的数据# 获取当前时间,模拟数据库内容data = time.ctime()response_body=file_data.replace("{%content%}",data)# 这里返回的是元组return status, response_header, response_body#获取个人中心数据
@route("/center.html")
def center():# 状态信息status = "200 OK"# 响应头信息response_header = [("Server", "PWS/1.1")]# 1.打开指定模板文件,读取模板文件中的数据with open("template/center.html","r",encoding='utf-8') as file:file_data=file.read()# 2.查询数据库,模板里面的模板变量替换成以后从数据库里查询的数据# web框架处理后的数据# 获取当前时间,模拟数据库内容data = time.ctime()response_body=file_data.replace("{%content%}",data)# 这里返回的是元组return status, response_header, response_body# 处理没有找到的动态资源
def not_found():# 状态信息status = "404 Not Found"# 响应头信息response_header = [("Server", "PWS/1.1")]# web框架处理后的数据data = "not found"# 这里返回的是元组return status, response_header, data# 处理动态资源请求
def handle_request(env):# 获取动态的请求资源路径request_path = env["request_path"]print("动态资源请求的地址:", request_path)# 判断请求的动态资源路径,选择指定的函数处理对应的动态资源请求for path, func in route_list:if request_path == path:result = func()return resultelse:result = not_found()return result# if request_path == "/index.html":# # 获取首页数据# result = index()# # 把处理后的结果返回给web服务器使用,让web服务器拼接响应报文时使用# return result# elif request_path=="/center.html":# #个人中心# result=center()# return result# else:# # 没有动态资源数据, 返回404状态信息# result = not_found()# # 把处理后的结果返回给web服务器使用,让web服务器拼接响应报文时使用# return result
if __name__=="__main__":print(route_list)