手机被网站安装软件有哪些内容如何开网店
完整的 LoRA 模型训练步骤:如何使用 Kohya_ss 进行 LoRA 训练
- 一、环境配置
- 1. 安装 Python 和虚拟环境
- 2. 克隆 Kohya_ss 仓库
- 3. 安装依赖
- 4. 启动 GUI
- lora训练
- 1. 准备数据 图片处理打标签
- 2. 配置 LoRA 训练
- 2.2 配置图片文件夹和输出目录
- 训练
- 解决方法:
使用kohya_ss来进行lora训练,难点就是各种报错的问题
如果你自己的CUDA,python,pytorch版本还和官网推荐的不一样,更是报错更多,
Kohya_ss 是一个功能强大的工具,专为 Stable Diffusion 模型的训练设计,可以帮助用户使用 LoRA 方法对模型进行微调。在本文中,我们将详细介绍如何使用 Kohya_ss 进行 LoRA 模型训练的完整步骤,包括环境配置、数据处理、以及模型训练等。
我是Linux centOS系列,用的英伟达CUDA11.2的服务器,虽然官方使用至少是CUDA11.8,但从底层的算子逻辑原理上CUDA11.2是兼容的。
具体步骤如下:
一、环境配置
1. 安装 Python 和虚拟环境
首先,你需要在 CentOS 系统上创建一个 Python 虚拟环境。以下是详细步骤:
安装 Conda: 如果你没有安装 Anaconda 或 Miniconda,可以从官方网站下载并安装它们。
创建 Python 3.10.9 环境: 安装完成后,使用以下命令创建一个 Python 3.10.9 的虚拟环境:
conda create --name kohya_ss python=3.10.9
注意必须是3.10.9,不然后续安装一些库的时候,不兼容报错
激活环境:
conda activate <your_env_name>
2. 克隆 Kohya_ss 仓库
Kohya_ss 项目托管在 GitHub 上,你可以使用以下命令克隆仓库:
git clone --recursive https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
3. 安装依赖
在 kohya_ss 目录下,运行以下命令安装必要的依赖:
chmod +x ./setup.sh
./setup.sh
如果安装这里,报错,或者没有权限去安装,也可以打开项目的requirements_linux.txt和requirements.txt的文件,手动pip安装。
我的CUDA是11.2 兼容的torch版本正好就是文件里requirements_linux.txt的:
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 xformers==0.0.23.post1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
最后安装完所有通过python -m bitsandbytes验证,如果没有报错就说明安装没问题了。
python -m bitsandbytes
4. 启动 GUI
若要在 Linux 上启动 GUI,你可以使用以下命令:
bash gui.sh --listen 0.0.0.0 --server_port 7860 --inbrowser --share
这里 0.0.0.0 表示可以从任何 IP 地址访问服务器,7860 是端口号,–share 参数允许你共享链接。你可以根据需要调整这些参数。
后续在训练的时间,需要通过网络访问huggingface下载预训练模型,但通常linux服务器没有代理,是无法访问的,下载不了模型,或者在下载模型时出现连接超时的问题
我的方法是
HF_ENDPOINT=https://hf-mirror.com bash gui.sh --listen 0.0.0.0 --server_port 7860 --inbrowser --share
利用一个镜像地址: http://hf-mirror.com下载
lora训练
1. 准备数据 图片处理打标签
首先,你需要准备原始训练图片,并使用 Kohya_ss 中的 BLIP Captioning 工具对这些图片进行描述。
在 Kohya_ss 的 GUI 中,点击 Utilities,然后选择 Captioning 和 BLIP Captioning。
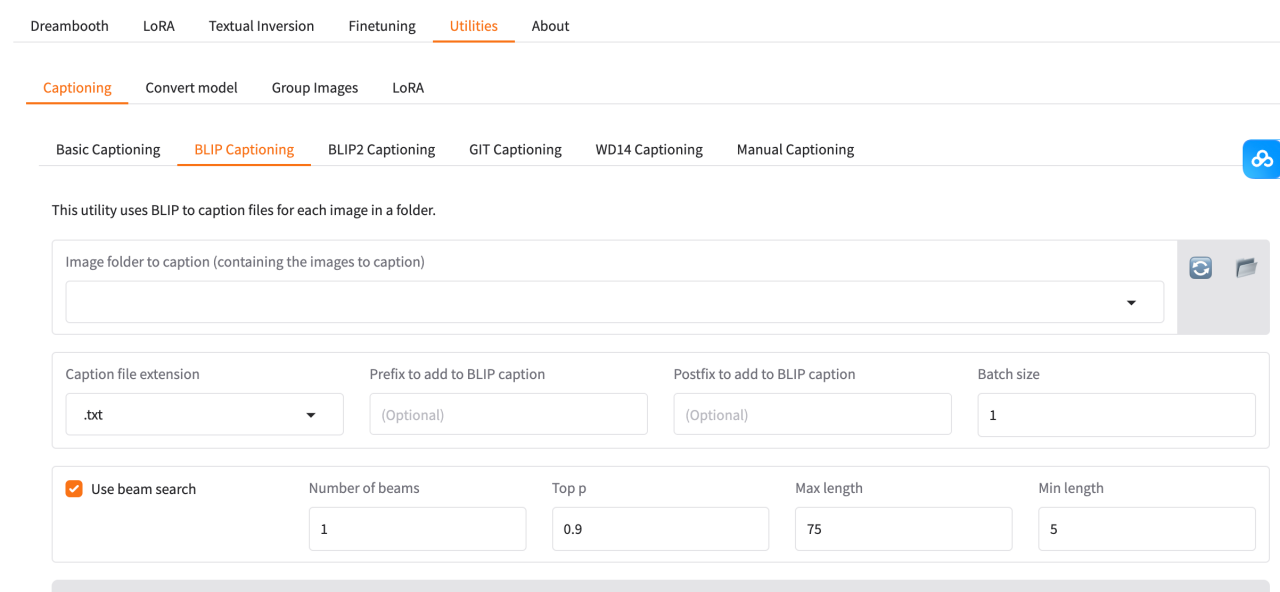
在弹出的界面中,选择存储训练图片的文件夹,
并在 “Prefix to add to BLIP caption” 栏目中填写图片描述的前缀文字(可选)(不填的话,后续点Caption images,生成标签过程也会下载预训练的blip模型,给你图像描述的)。
点击 Caption images 按钮开始对图片进行处理。
此时,BLIP 将生成每张图片的文字描述,这些描述将用于训练LoRA 模型。
linux日志出现如下,就说明生成出来了

为什么打标签:标签为模型学习提供明确的目标和方向。在 LoRA 训练中,模型通过对数据集中图像和对应标签的学习,理解不同数据特征与期望输出之间的关系。例如在训练一个生成动漫角色的 LoRA 模型时,标签可以是角色的名字、性格特点、所属动漫等信息。模型在训练过程中,依据这些标签,将图像中的人物外貌、服饰风格等特征与标签内容建立联系,从而学习到如何生成符合特定角色设定的图像。如果没有标签,模型就无法得知这些图像代表的具体概念,难以进行针对性学习。
2. 配置 LoRA 训练
在 Configuration file 部分,你可以选择加载一个预定义的配置文件。可以在网上找到一些常用的配置文件,或者根据你的需求自行编写。这个文件通常是一个 JSON 格式的文件,包含了训练过程的参数和设置,其实也不需要自己准备,在你lora,gui界面训练的时候,就会自动生成,可以直接跳过这里。
例如,配置文件可能看起来像这样:
{"LoRA_type": "Standard","LyCORIS_preset": "full","adaptive_noise_scale": 0,"additional_parameters": "","async_upload": false,"block_alphas": "","block_dims": "","block_lr_zero_threshold": "","bucket_no_upscale": true,"bucket_reso_steps": 64,"bypass_mode": false,"cache_latents": true,"cache_latents_to_disk": false,"caption_dropout_every_n_epochs": 0,"caption_dropout_rate": 0,"caption_extension": ".txt","clip_skip": 1,"color_aug": false,"constrain": 0,"conv_alpha": 1,"conv_block_alphas": "","conv_block_dims": "","conv_dim": 1,"dataset_config": "","debiased_estimation_loss": false,"decompose_both": false,"dim_from_weights": false,"dora_wd": false,"down_lr_weight": "","dynamo_backend": "no","dynamo_mode": "default","dynamo_use_dynamic": false,"dynamo_use_fullgraph": false,"enable_bucket": true,"epoch": 1,"extra_accelerate_launch_args": "","factor": -1,"flip_aug": false,"fp8_base": false,"full_bf16": false,"full_fp16": false,"gpu_ids": "","gradient_accumulation_steps": 1,"gradient_checkpointing": false,"huber_c": 0.1,"huber_schedule": "snr","huggingface_path_in_repo": "","huggingface_repo_id": "","huggingface_repo_type": "","huggingface_repo_visibility": "","huggingface_token": "","ip_noise_gamma": 0,"ip_noise_gamma_random_strength": false,"keep_tokens": 0,"learning_rate": 0.0001,"log_tracker_config": "","log_tracker_name": "","log_with": "","logging_dir": "/data/kohya_ss/logs","loss_type": "l2","lr_scheduler": "cosine","lr_scheduler_args": "","lr_scheduler_num_cycles": 1,"lr_scheduler_power": 1,"lr_warmup": 10,"main_process_port": 0,"masked_loss": false,"max_bucket_reso": 2048,"max_data_loader_n_workers": 0,"max_grad_norm": 1,"max_resolution": "512,512","max_timestep": 1000,"max_token_length": 75,"max_train_epochs": 0,"max_train_steps": 1600,"mem_eff_attn": false,"metadata_author": "","metadata_description": "","metadata_license": "","metadata_tags": "","metadata_title": "","mid_lr_weight": "","min_bucket_reso": 256,"min_snr_gamma": 0,"min_timestep": 0,"mixed_precision": "fp16","model_list": "","module_dropout": 0,"multi_gpu": false,"multires_noise_discount": 0.3,"multires_noise_iterations": 0,"network_alpha": 1,"network_dim": 8,"network_dropout": 0,"network_weights": "","noise_offset": 0,"noise_offset_random_strength": false,"noise_offset_type": "Original","num_cpu_threads_per_process": 2,"num_machines": 1,"num_processes": 1,"optimizer": "AdamW8bit","optimizer_args": "","output_dir": "/data/kohya_ss/outputs","output_name": "tianqiong1","persistent_data_loader_workers": false,"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5","prior_loss_weight": 1,"random_crop": false,"rank_dropout": 0,"rank_dropout_scale": false,"reg_data_dir": "","rescaled": false,"resume": "","resume_from_huggingface": "","sample_every_n_epochs": 0,"sample_every_n_steps": 0,"sample_prompts": "","sample_sampler": "euler_a","save_every_n_epochs": 1,"save_every_n_steps": 0,"save_last_n_steps": 0,"save_last_n_steps_state": 0,"save_model_as": "safetensors","save_precision": "fp16","save_state": false,"save_state_on_train_end": false,"save_state_to_huggingface": false,"scale_v_pred_loss_like_noise_pred": false,"scale_weight_norms": 0,"sdxl": false,"sdxl_cache_text_encoder_outputs": false,"sdxl_no_half_vae": false,"seed": 0,"shuffle_caption": false,"stop_text_encoder_training_pct": 0,"text_encoder_lr": 0.0001,"train_batch_size": 1,"train_data_dir": "/data/kohya_ss/dataset","train_norm": false,"train_on_input": true,"training_comment": "","unet_lr": 0.0001,"unit": 1,"up_lr_weight": "","use_cp": false,"use_scalar": false,"use_tucker": false,"v2": false,"v_parameterization": false,"v_pred_like_loss": 0,"vae": "","vae_batch_size": 0,"wandb_api_key": "","wandb_run_name": "","weighted_captions": false,"xformers": "xformers"
}
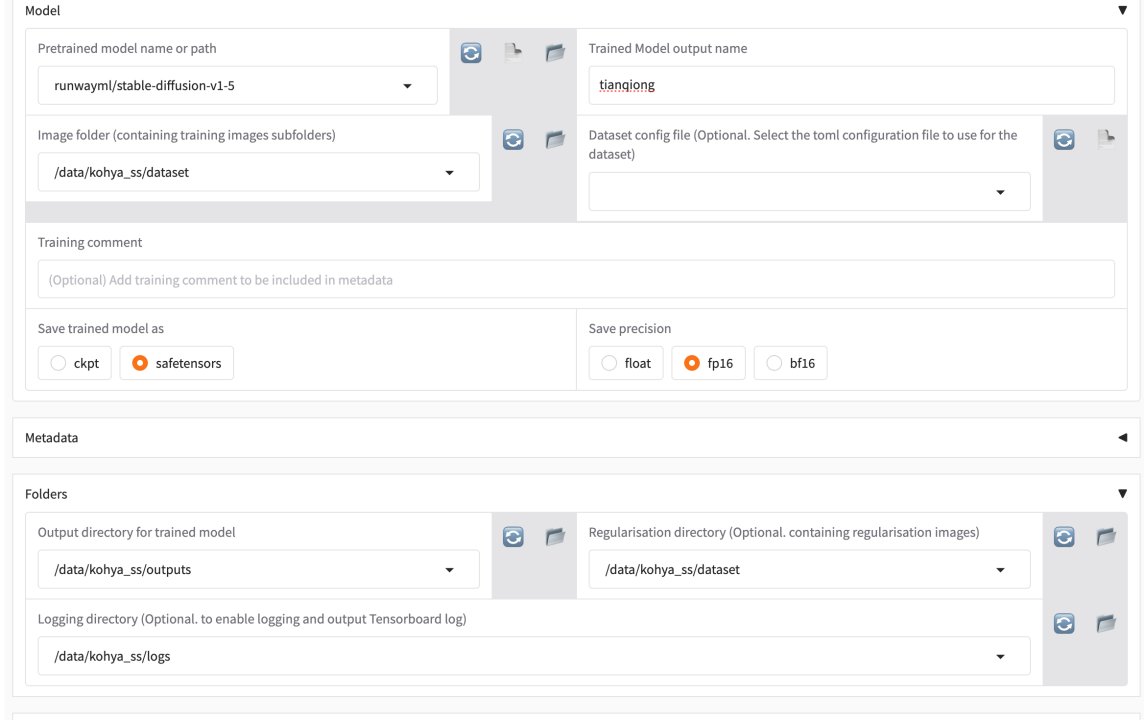
2.2 配置图片文件夹和输出目录
在 Kohya_ss 的 GUI 中,点击 loRA,然后选择 Training
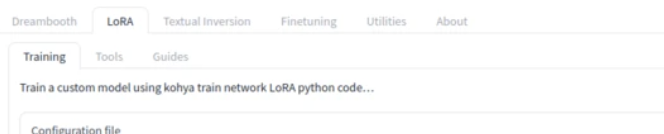
在 Image folder 选项中选择你存储训练图片的文件夹。在 Output folder 中选择你希望保存训练结果(LoRA 文件)的目录。
放图片的文件夹用数字_英文的格式,比如100_abc这样的名字来命名,100代表重复图像100次,如果你要训练500次,就改成500_abc。jpg和txt都放在一起。为什么要这么取名字,因为这是kohya_ss软件作者定的规矩
文件夹必须放在kohya_ss/dataset下面
后面详细的参数配置里有Epoch和Max train step
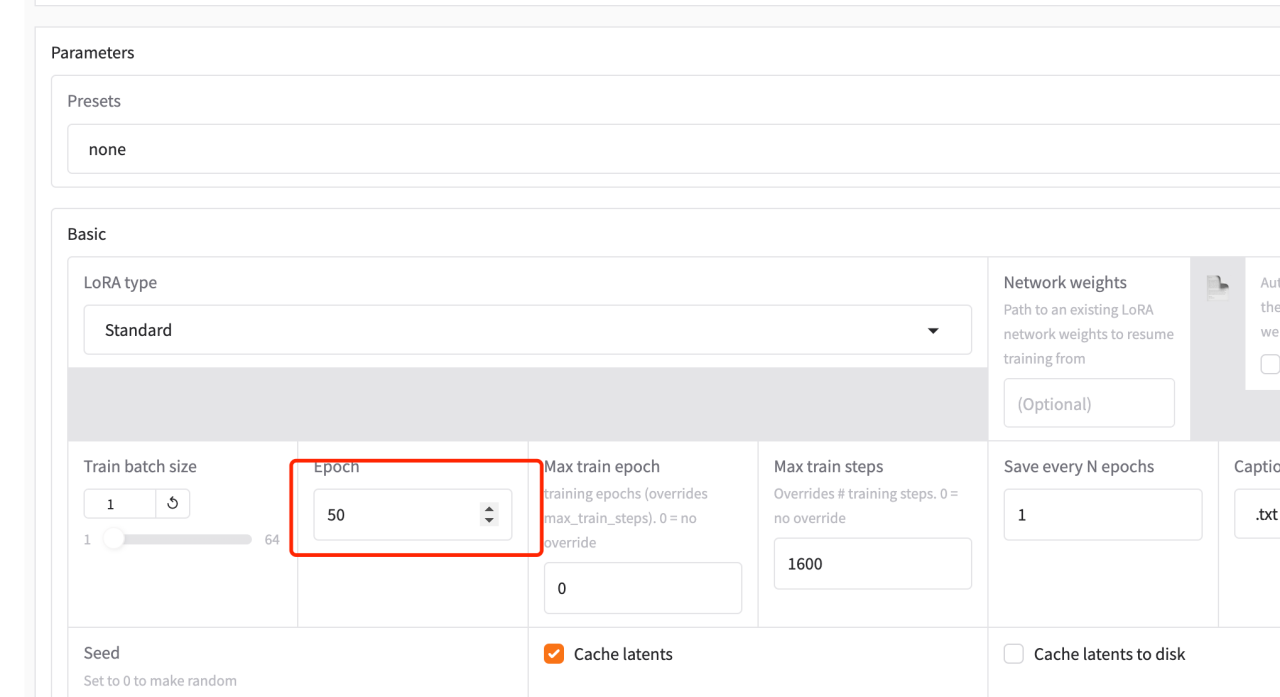
Train batch size (训练批量大小)
这个参数指定了每次训练时输入到模型中的样本数量。它决定了每一轮(batch)计算的训练数据量。大批量训练能够利用GPU的并行计算能力,但也会消耗更多的内存。较小的批量大小则会减少内存占用,但可能会导致训练速度变慢。
举例来说:
如果设置为 batch size = 64,每次训练时会使用64张图片进行 前向传播和反向传播。
如果内存较小,可能需要降低批量大小以避免内存溢出。
Max train epoch (最大训练周期数)
训练周期数(epoch)指的是整个训练数据集被模型完整使用的次数。一个 epoch 代表训练集中的所有图像都被用来训练了一次。如果这个参数设置为 1,那么模型只会遍历一次训练数据集。
如果设置为 Max train epoch = 1,表示在训练过程中,数据集将只被使用一次。如果你希望模型多次遍历数据集以进行优化,可以增加这个值。
Max train steps (最大训练步数)
训练步数指的是模型参数更新的次数。每个训练步骤对应于一批数据的处理和权重更新。如果设置了 Max train steps,训练将会在达到指定的步数后停止。
如果设置为 Max train steps = 1600,意味着模型将在达到1600步之后停止训练,尽管最大训练周期数可能允许更多的遍历。
注意:如果你同时设置了 Max train epoch 和 Max train steps,训练将会根据更先达到的条件停止。即,如果训练步骤达到了最大步数,训练会提前停止。
还记得之前的文件夹命名吗,10_abc就等于,把文件夹里所有的图片乘以100下,也就是有1000张图片,下面用一段案列分析
假设你有 1000 张图像,epoch 设置为 50,batch_size 为 1,以下是一些相关参数的影响和内存占用的计算。
- 内存占用分析
内存占用主要取决于以下几个因素:
- 每张图像的大小(例如,尺寸、颜色通道等)
- 批量大小(batch_size)
- 图像数量(num_train_images)
- 模型本身的内存占用
但在此情况下,我们主要关注每次训练时的图像数据占用。
假设:
每张图像的尺寸:假设每张图像大小为 256 x 256 x 3(RGB图像)。
图像数据存储:每个像素点使用 4 字节(float32),即 32 位。
每张图像的内存占用:
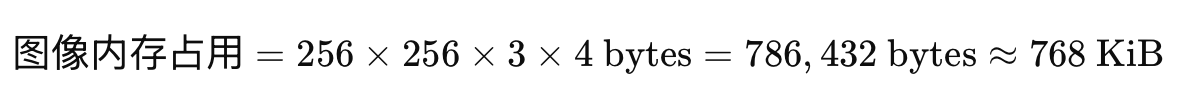
- 每次训练的内存占用
由于 batch_size = 1,每个批次会加载一张图像到内存中,因此每次训练所需的内存大小就是每张图像的大小。对于每个批次:

- 总训练内存占用
每个 epoch 会遍历所有训练图像一次。在你的配置中,epoch = 50,每个 epoch 会训练 1000 张图像。所以:

每次训练时,每个批次都要将当前的图像加载到 GPU 内存中,因此每个 epoch 的内存占用大约为 750 MiB。所有训练的时候要考虑一下文件夹命名需要重复几次,还有图像的分辨率如果太高了,很可能导致GPU内存不足
训练
点击start training

可能会出现报错
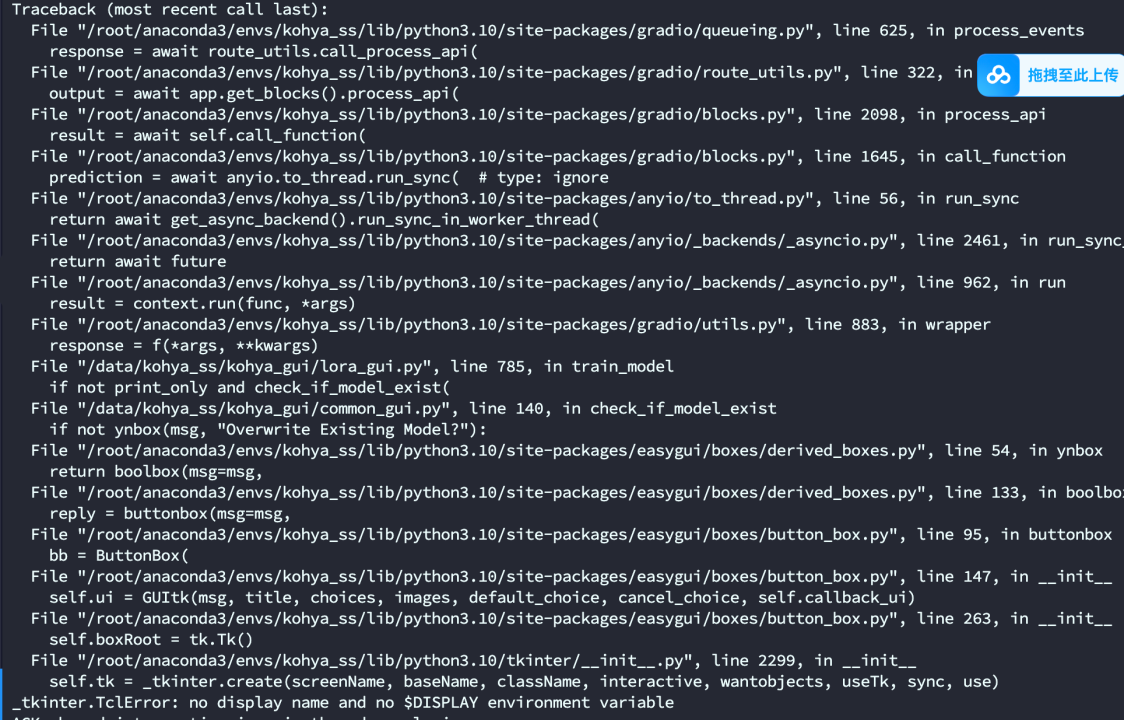
解决方法:
在 CentOS 上设置虚拟显示器(Xvfb)的方法与 Ubuntu 类似。以下是为 CentOS 配置 Xvfb 和运行 GUI 程序的详细步骤:
- 安装 Xvfb
首先,安装 Xvfb 包:
我是centOS用的yuml,如果是Ubuntu用lapt-getl
yum install xorg-x11-server-Xvfb
- 启动 Xvfb
启动 Xvfb 服务器并指定显示编号(通常使用 :99):
Xvfb :99 &
这个命令将启动一个虚拟显示器,并且在后台运行。
- 设置 DISPLAY 环境变量
然后,设置 DISPLAY 环境变量,让系统知道应该使用虚拟显示器:
export DISPLAY=:99
这一步非常重要,必须指向 Xvfb 模拟的显示器。你可以将这行代码添加到 .bashrc 或 .bash_profile 文件中,以便在每次登录时自动设置。
验证模型:训练好了,找到文件模型,可以在stable diffusion weui或者comfyui上验证,我用的comfyui,我先找到一张原图,通过反向推理提示词,生成提示词文本,导入到clip进行生成。