安监局网站建设指数函数公式
目录:导读
session简介
session登录
自动写博客
抓取写博客接口
requests自动写博客
写在最后

http协议是无状态的,也就是每个请求都是独立的。那么登录后的一系列动作,都需要用cookie来验证身份是否是登录状态,为了高效的管理会话,保持会话,于是就有了session。
session简介
session是一种管理用户状态和信息的机制,与cookies的不同的是,session的数据是保存在服务器端。说的明白点就是session相当于一个虚拟的浏览器,在这个浏览器上处于一种保持登录的状态。
session登录
格式:
# session 用法| Basic Usage::| | >>> import requests| >>> s = requests.Session()| >>> s.get('https://httpbin.org/get')| <Response [200]>| | Or as a context manager::| | >>> with requests.Session() as s:| >>> s.get('https://httpbin.org/get')| <Response [200]>1.举个例子,模拟百度登录场景
2.查看登录后百度账号的cookies值,经过观察发现是由”BAIDUID“和"BDUSS"

3.导入requests模块,使用session()函数
4.携带cookies进行请求,通过返回内容,判断是否登录成功。
# coding:utf-8
import requests
# 保持登录状态
s = requests.session()
url = 'https://www.baidu.com/'
# 请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
r = s.post(url,headers=headers)
# 查看的cookies值
cooks = {"BDUSS":"xxxxxxx","BAIDUID":"XXXXXXXX"
}
# 添加登录所携带的cookies
c = requests.cookies.RequestsCookieJar()
c.set("BDUSS",cooks["BDUSS"])
c.set("BAIDUID",cooks["BAIDUID"])
s.cookies.update(c)
# 判断是否登录成功
r2 = s.get(url,headers=headers)
if '我在谁身旁' in r2.text:print('登录成功')
else:print("登录失败")执行结果:登录成功这个时候就可以做一些登录过后的操作。
session模拟浏览器,浏览器中登录状态,只要浏览器不退出,就可以继续做其他的操作了。
自动写博客
我们先理下书写的思路:
1.通过request访问博客园;
2.通过session保存cookies;
3.携带保存的cookies进行请求写博客的接口
4.编写博客内容,进行保存,发博客
获取登录cookies
1.通过fiddler\F12进行抓取未登录的cookies值
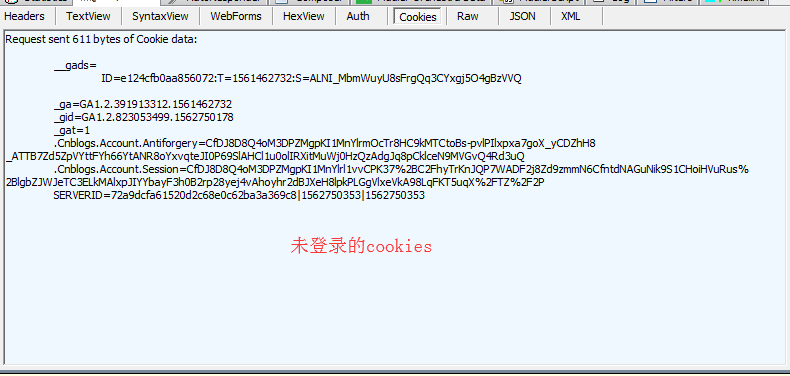
2.再次抓取Fiddler\F12进行抓取登录后的cookies值
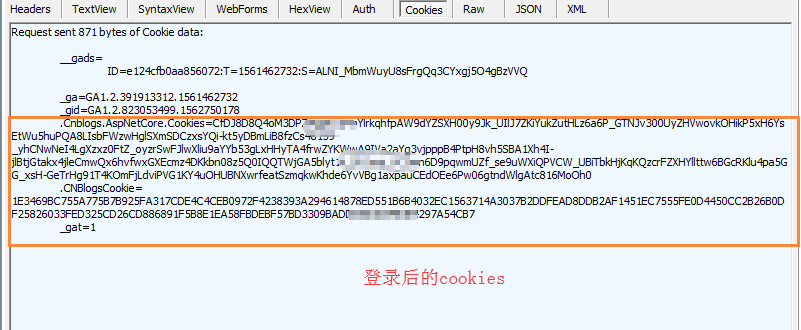
3.把cookies放到session中
# coding:utf-8
import requests
import urllib3
from bs4 import BeautifulSoup
urllib3.disable_warnings()
s = requests.session()
s.verify = False # 全局的
url = 'https://passport.cnblogs.com/user/signin'headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
r = s.get(url,headers=headers)
cooks = {".Cnblogs.AspNetCore.Cookies":"XXXXXXXX",".CNBlogsCookie":"XXXXXX"
}
c = requests.cookies.RequestsCookieJar()
c.set(".CNBlogsCookie", cooks[".CNBlogsCookie"]) # 登陆有效的cookies
c.set(".Cnblogs.AspNetCore.Cookies", cooks[".Cnblogs.AspNetCore.Cookies"])
s.cookies.update(c)
url1 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
r1 = s.get(url1)
if "博客后台管理" in r1.text:print("登录成功!")抓取写博客接口
1.抓取编写博客接口,获取编写内容,查看Raw获取接口内容
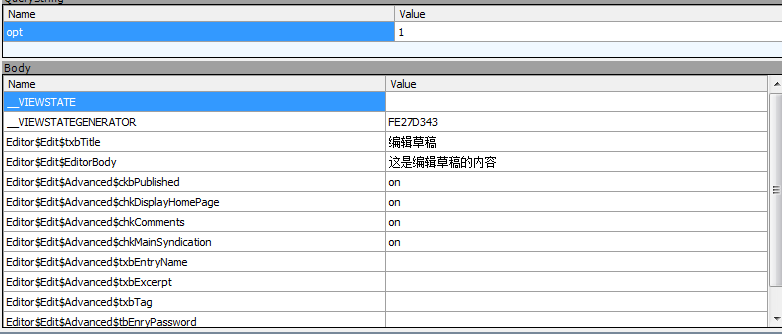
2.把这些值通过字典的形式进行编写如:{“name”:“value”}
body = {"__VIEWSTATE":"","__VIEWSTATEGENERATOR":"FE27D343","Editor$Edit$txbTitle":"编辑草稿","Editor$Edit$EditorBody":"这是编辑草稿的内容","Editor$Edit$Advanced$ckbPublished":"on","Editor$Edit$Advanced$chkDisplayHomePage":"on","Editor$Edit$Advanced$chkComments":"on","Editor$Edit$Advanced$chkMainSyndication":"on","Editor$Edit$Advanced$txbEntryName":"","Editor$Edit$Advanced$txbExcerpt":"","Editor$Edit$Advanced$txbTag":"","Editor$Edit$Advanced$tbEnryPassword":"","Editor$Edit$lkbDraft":"存为草稿"
}requests自动写博客
1.重新编写草稿内容,然后通过session进行重新发帖(草稿内容部分进行了改变,方便区分)
# coding:utf-8
import requests
import urllib3
from bs4 import BeautifulSoup
urllib3.disable_warnings()
s = requests.session()
s.verify = False # 全局的
url = 'https://passport.cnblogs.com/user/signin'headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
r = s.get(url,headers=headers)
cooks = {".Cnblogs.AspNetCore.Cookies":"XXXXXXXXX",".CNBlogsCookie":"XXXXXX"
}
c = requests.cookies.RequestsCookieJar()
c.set(".CNBlogsCookie", cooks[".CNBlogsCookie"]) # 登陆有效的cookies
c.set(".Cnblogs.AspNetCore.Cookies", cooks[".Cnblogs.AspNetCore.Cookies"])
s.cookies.update(c)
url1 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
r1 = s.get(url1)
if "博客后台管理" in r1.text:print("登录成功!")
body = {"__VIEWSTATE":"","__VIEWSTATEGENERATOR":"FE27D343","Editor$Edit$txbTitle":"编辑草稿自动写博客","Editor$Edit$EditorBody":"这是编辑草稿的内容自动写博客","Editor$Edit$Advanced$ckbPublished":"on","Editor$Edit$Advanced$chkDisplayHomePage":"on","Editor$Edit$Advanced$chkComments":"on","Editor$Edit$Advanced$chkMainSyndication":"on","Editor$Edit$Advanced$txbEntryName":"","Editor$Edit$Advanced$txbExcerpt":"","Editor$Edit$Advanced$txbTag":"","Editor$Edit$Advanced$tbEnryPassword":"","Editor$Edit$lkbDraft":"存为草稿"
}
# 请求保存草稿接口
r2 = s.post(url1,headers=headers,data=body)2.发送请求后通过查看博客园的草稿箱查看是否保存成功

写在最后
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
看到这篇文章的人有觉得我的理解有误的地方,也欢迎评论和探讨~
你也可以加入下方的的群聊去和同行大神交流切磋