wordpress漂浮插件北京seo助理
一、前言
前面在介绍本地部署免费开源的知识库方案时,已经简单介绍过 Danswer《Danswer 快速指南:不到15分钟打造您的企业级开源知识问答系统》,它支持即插即用不同的 LLM 模型,可以很方便的将本地知识文档通过不同的连接器接入到 Danswer,然后实现本地基于知识库的语义检索。它是完全开源的(MIT 许可证)并且免费使用。
1.1、为什么选择 Danswer
默认设置下,Danswer 使用 OpenAI 的 GPT 系列模型,由于很多时候我们因为数据隐私问题需要在本地部署离线的知识库系统,需要接入本地开源的模型,今天本文将简单介绍下如何使用开源模型 Llama 2 接入 Danswer。
至于为什么选择 Danswer,简单啰嗦一下,更具体的信息可以访问官方文档:
-
它是完全开源的(MIT 许可证)并且免费使用。
-
允许您即插即用不同的 LLM 模型,例如 GPT、HuggingFace、GPT4All、Llama cpp,甚至自定义自托管模型。
-
具有开箱即用的关键功能,如文档访问控制、前端 UI、管理仪表板、轮询文档更新和灵活的部署选项。
-
与 Slack、GitHub、GoogleDrive 等其他工具的连接器的不错列表。
1.2、为什么选择 Llama 2
自从 Meta 公司发布了最新的 LLaMA 2 模型并且开源之后,在LLM领域掀起了一阵不小的浪潮,至少从各种排行榜和评估结果来看,Llama 2 在开源界要优于其它的产品,它击败了 Falcon-40B(之前最好的开源基础模型),与 GPT-3.5 相当,仅低于 GPT-4 和 PALM 2(均为闭源模型,分别由 OpenAI 和 Google 拥有)。

从以上排行榜不难看出,基本上整个列表大部分的开源模型都是由 Llama 2 衍生品组成的。
二、在 Google Colab 上托管 Llama 2 模型
Llama 2 型号有 3 种不同尺寸:7B、13B 和 70B 参数。700 亿参数版本需要多个 GPU,因此无法免费托管。在 13B 和 7B 版本中,13B 版本更强大,但需要一些压缩(量化或降低浮点精度)才能适合单个中档 GPU。幸运的是,Llama cpp 库使这变得相当简单。这里我们将以 Llama 2 13B量化模型来进行演示。
在开始之前,请确保在 Google Colab 上设置了 T4 GPU 运行时
2.1、安装依赖
-
运行 FastAPI 服务器所需的依赖项
-
通过 Ngrok 创建公共模型服务 URL 所需的依赖项
-
运行 Llama2 13B(包括量化)所需的依赖项
# 构建 Llama cpp
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python# 如果出现依赖解析器的错误提示,可以忽略
!pip install fastapi[all] uvicorn python-multipart transformers pydantic tensorflow# 这将在 Google Colab 实例中下载并设置 Ngrok 可执行文件
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip -o ngrok-stable-linux-amd64.zip
Ngrok 用于通过公共 URL 访问 FastAPI 服务器。
用户需要创建一个免费账户并提供他们的身份验证令牌以使用 Ngrok。免费版本只允许一个本地隧道,并且身份验证令牌用于跟踪此使用限制。
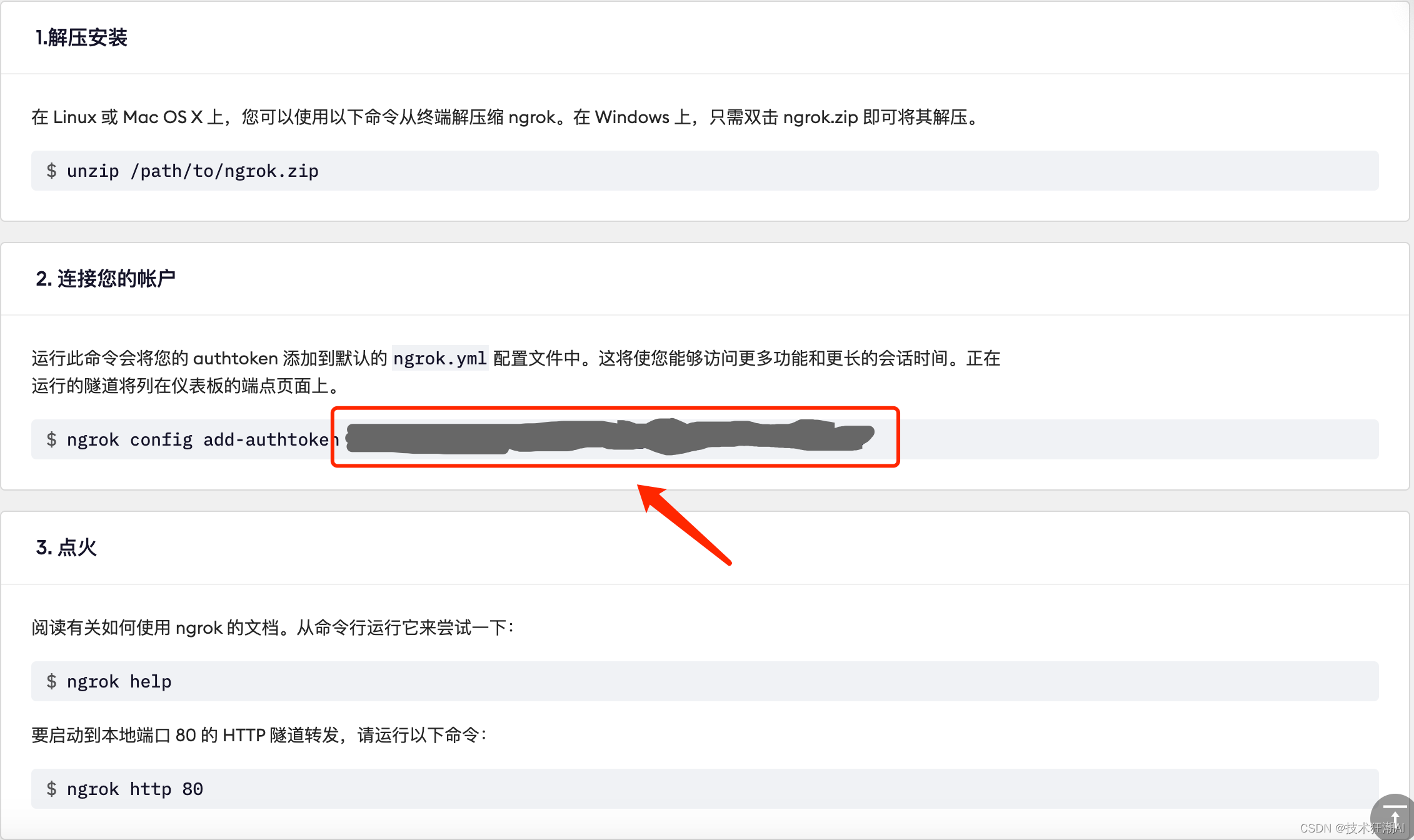
在 Ngrok 设置页面上获取 Auth token,如图中红框所示
# https://dashboard.ngrok.com/signup
!./ngrok authtoken <YOUR-NGROK-TOKEN-HERE>
2.2、创建 FastAPI 应用
这里提供了一个与 Llama 2 模型交互的 API。可以根据需要在下面的代码中更改模型版本。在这个演示示例中,我们将使用 130 亿参数版本,该版本经过微调以进行指令(聊天)跟随。尽管进行了压缩,但它仍然比 70 亿变体更强大。
%%writefile app.py
from typing import Anyfrom fastapi import FastAPI
from fastapi import HTTPException
from pydantic import BaseModel
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
import tensorflow as tf# 在 T4 GPU 上拟合 Llama2-13B 需要 GGML 模型
GENERATIVE_AI_MODEL_REPO = "TheBloke/Llama-2-13B-chat-GGML"
GENERATIVE_AI_MODEL_FILE = "llama-2-13b-chat.ggmlv3.q5_1.bin"model_path = hf_hub_download(repo_id=GENERATIVE_AI_MODEL_REPO,filename=GENERATIVE_AI_MODEL_FILE
)llama2_model = Llama(model_path=model_path,n_gpu_layers=64,n_ctx=2000
)# 测试推理
print(llama2_model(prompt="Hello ", max_tokens=1))app = FastAPI()# 这里定义了端点所期望的数据 JSON 格式,根据需要进行更改
class TextInput(BaseModel):inputs: strparameters: dict[str, Any] | None@app.get("/")
def status_gpu_check() -> dict[str, str]:gpu_msg = "Available" if tf.test.is_gpu_available() else "Unavailable"return {"status": "I am ALIVE!","gpu": gpu_msg}@app.post("/generate/")
async def generate_text(data: TextInput) -> dict[str, str]:try:params = data.parameters or {}response = llama2_model(prompt=data.inputs, **params)model_out = response['choices'][0]['text']return {"generated_text": model_out}except Exception as e:raise HTTPException(status_code=500, detail=str(e))
2.3、启动 FastAPI 服务器
由于需要下载模型并将其加载到 GPU 上,初始运行时间会很长。
注意:中断 Google Colab 运行时会发送 SIGINT 并停止服务器。
# 此单元格很快完成,因为它只需要启动服务器
# 服务器将开始下载模型,并需要一段时间才能启动
# 约 5 分钟
!uvicorn app:app --host 0.0.0.0 --port 8000 > server.log 2>&1 &
检查 server.log 日志以查看进度。在继续之前,请等待模型加载完成并使用下一个单元格进行检查。
# 如果看到 "Failed to connect",那是因为服务器仍在启动中
# 等待模型下载完成和服务器完全启动
# 检查 server.log 文件以查看状态
!curl localhost:8000
2.4、使用 Ngrok 为 FastAPI 服务器创建公共 URL。
重要提示:如果您通过电子邮件创建了一个账户,请验证您的电子邮件,否则下面的两个单元格将无法正常工作。
如果您通过 Google 或 GitHub 账户注册,那就没问题了。
# 这将启动 Ngrok 并创建一个公共 URL。
from IPython import get_ipython
get_ipython().system_raw('./ngrok http 8000 &')
检查下一个单元格生成的 URL,它应该显示 FastAPI 服务器正在运行,并且 GPU 可用。
要访问模型的端点,只需在 URL 后面添加 /generate。
curl --location --request POST '<REPLACE-WITH-YOUR-NGROK-PUBLIC-URL>/generate' \
--header 'Content-Type: application/json' \
--data-raw '{"inputs": "请介绍下 Danswer 如何接入 Llama 2 模型?","parameters": {"temperature": 0.0,"max_tokens": 25}
}'
# 获取公共 URL
# 如果无法正常工作,请确保您已验证您的电子邮件。
# 然后再次运行上一个代码单元格和这个代码单元格。
!curl -s http://localhost:4040/api/tunnels | python3 -c "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
2.5、关闭服务
要关闭进程,请在一个新的单元格中运行以下命令:
!pkill uvicorn
!pkill ngrok
[Google Colab 代码]
https://colab.research.google.com/drive/1HhqGGzV-q1m0igdhpGt5Wmf8VmDiyIcn#scrollTo=liqVEsGfZPse
三、在 Danswer 中接入 Llama 2 模型
Danswer 可以通过 REST 请求向任意模型服务器发出请求。可以选择传入访问令牌。要自定义请求格式和响应处理,可能需要更新/重建 Danswer 容器。
3.1、部署 Danswer
Danswer 提供 Docker 容器,可以轻松部署在任何云上,无论是在单个实例上还是通过 Kubernetes。在本演示中,我们将使用 Docker Compose 在本地运行 Danswer。
首先拉去 danswer 代码:
git clone https://github.com/danswer-ai/danswer.git
接下来导航到部署目录:
cd danswer/deployment/docker_compose
Danswer 默认使用的模型是 GPT-3.5-Turbo,如果想使用开源的如 Llama 2 模型API,通过创建 .env 文件来覆盖一些默认值(针对 Linux 显示),将 Danswer 配置为使用新的 Llama 2 端点:
GEN_AI_MODEL_PROVIDER=custom
GEN_AI_API_ENDPOINT=<REPLACE-WITH-YOUR-NGROK-PUBLIC-URL>/generate
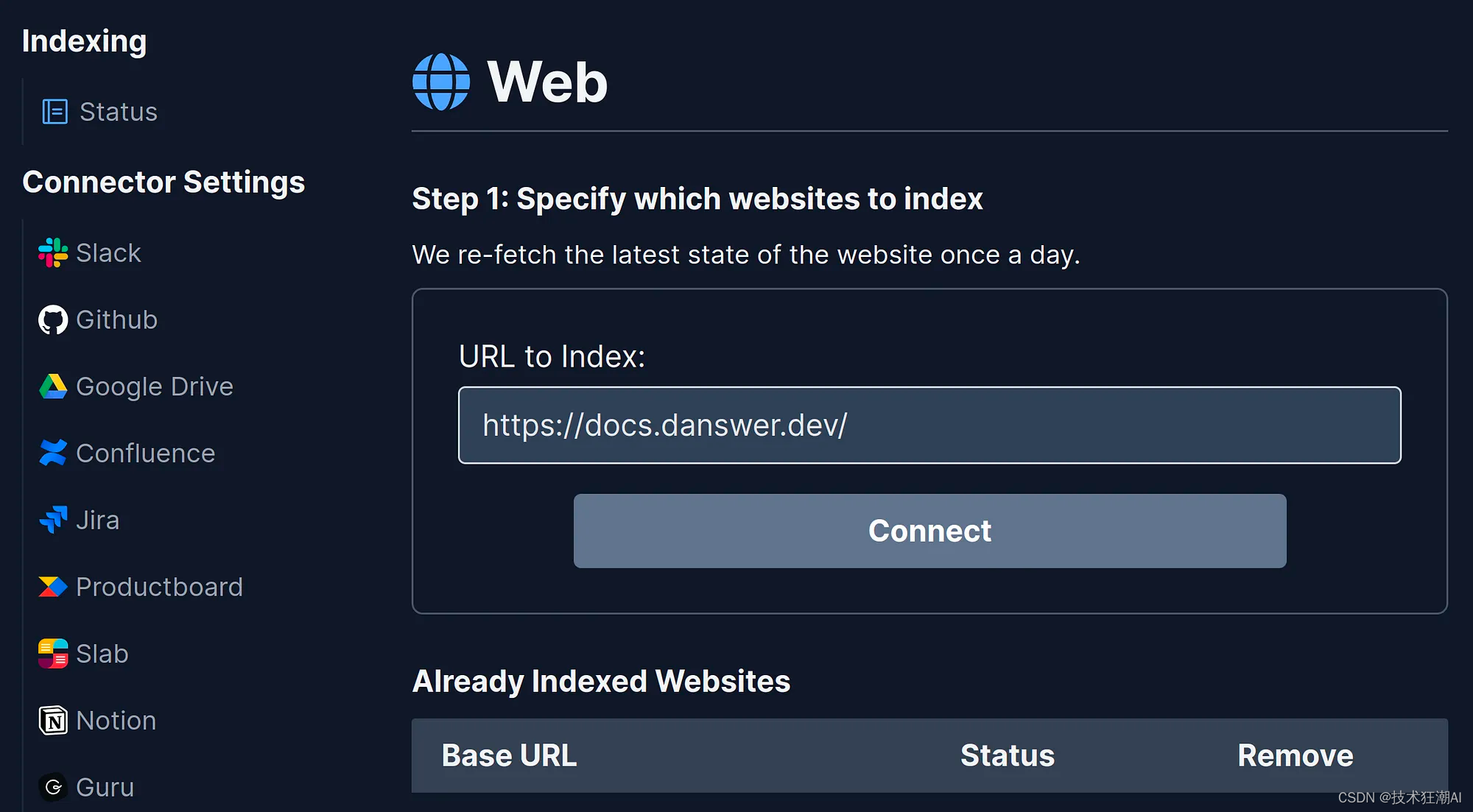
3.3、添加文档到 Danswer
这里我们将 Danswer 文档网站建立索引。只需要在Web连接器中添加文档URL地址即可。
3.4、从 Danswer 获取答案
单击 Danswer 徽标返回主页,现在您可以询问有关新索引文档的问题。

四、总结
本文主要介绍了如何在Google Colab上托管Llama 2模型,并将其接入Danswer。Danswer是一个开源的知识问答系统,支持不同的LLM模型,可以方便地将本地知识文档接入到Danswer,实现基于知识库的语义检索。
虽然使用 Google Colab 可以免费托管您的 LLM,但是需要注意以下几点:
-
Google Colab 更适用于开发目的,如果您想要永久端点,可能需要投资专用硬件,因为在一段时间不活动后,Google Colab 将回收实例。也可考虑在 HF 上托管。
-
免费套餐中不支持高端 GPU 如 A100。
-
在免费套餐中,每个会话最多只能申请 12 小时的实例。
五、References
[1] Danswer 代码:https://github.com/danswer-ai/danswer
[2] Danswer 文档:https://docs.danswer.dev/