淘宝联盟链接的网站怎么做最新国际新闻事件今天
🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
点我下载源码
1、物体检测
说到目标检测你能想到什么
faster-rcnn系列,开山之作,各种proposal方法
YOLO肯定也少不了,都是基于anchor这路子玩的
NMS那也一定得用上,输出结果肯定要过滤一下的
如果一个目标检测算法,上面这三点都木有,你说神不神!
faster-rcnn是开山之作,15年的物体检测算法,yolo系列实际上就是把faster-rcnn做的更加简单了,但是源码量确增加了。但是都有问题,都是基于anchor做的。
anchor base都会产生一些问题,因为会产生多个框,多个框就用NMS非极大值抑制过滤一下框。但是框的过滤效率比较低。
在之前,Transformer都是作为一个backbone,即特征提取的网络,主要在他的基础上做下游任务。物体检测这么多年了,一直也是faster-rcnn、YOLO、NMS这些没变过,如果突然把这些全部打破,是不是有点太夸张了?
2、DETR

DETR,Detection Transformer
首先还是和Swin Transformer一样,先用CNN把图像转换成Patch
再套用Transformer的self-Attention、Encoder、Decoder那一套,直接预测出100个坐标框出来
在编码器中初始化100个向量,让这100个向量都预测一个坐标框和一个类别的概率值。
这100个框中有物体和非物体,但是在非物体就不管了,过滤掉,只找出
但是这100个框是并行,不是串行的
3、基本架构
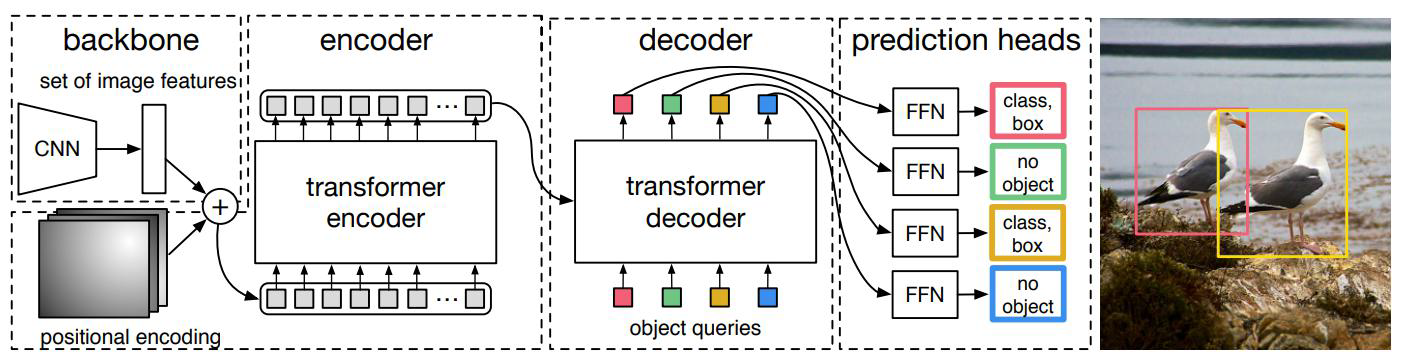
通过CNN得到patch再加上位置编码,作为Encoder的输入,这个输入没有cls
而Decoder初始化100个向量(object queries),Decoder利用Encoder的输出去重构这100个向量,Decoder输出去预测出100个框,这个框有没有物体,物体的类别,以及框的坐标
4、Encoder作用

为什么前面要用Encoder的输出来重构初始化的向量呢?直接用CNN输出的向量来重构不可以吗?
论文中这样解释,基于注意力的结果,可以告诉解码器应该关注图像的哪些区域,即哪些区域是物体
如图所示,不同的patch提供了不同的注意力,左边上图和下图分别注意到了不同的两头牛,而右边上图和下图也分别注意到了不同的两头牛,这是不同的patch提取到的特征,关注到了不同的物体,即使图像中的物体有遮挡现象但是还是由于注意力机制还是不影响特征的提取。
5、整体架构
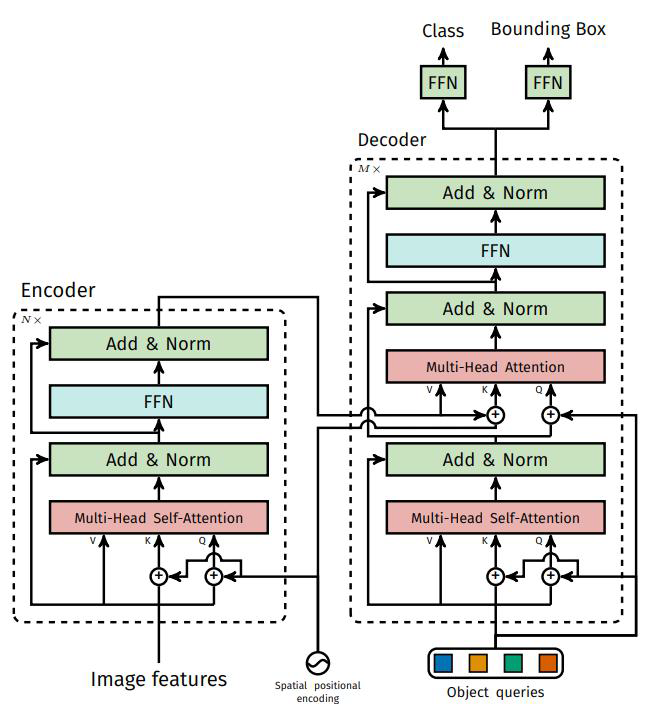
输出层就是100个object queries预测
编码器木有啥特别的,正常整就行
解码器首先随机初始化object queries
(0+位置编码,简直惊呆。。。)
通过多层让其学习如何利用输入特征
编码器和VIT、Swin Transformer一样没有特别的,原始图像CNN提取成patch再生成Q、K、V,经过多头注意力机制和MLP,中间还有一些残差连接
但是解码器竟然初始化全部都是0,然后这个0再加上位置编码,这个位置编码和原始图像的位置编码是没有关系的,是这100个向量的位置编码。这100个向量生成第一轮的Q、K、V,先去做self-Attention。
然后第一轮的输出作为Q,Encoder的输出作为K、V,其中K加上了位置编码,V没有加上位置编码,然后这里的QKV再去做多头注意力机制,这中间还有一些残差连接。
这两轮的输出再经过MLP后,一个经过全连接去做分类任务预测类别,一个经过全连接去做回归任务预测框
在DETR中的Decoder没有加入mask机制
6、输出匹配
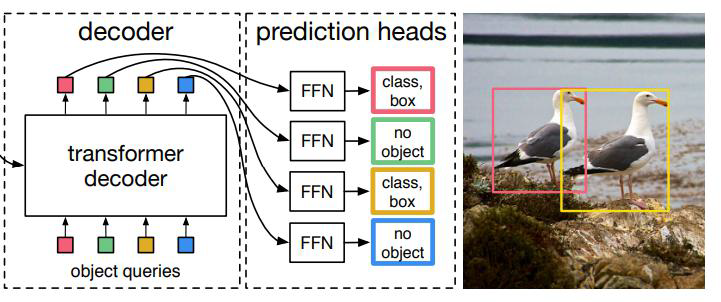
GT(Ground Truth)只有两个,但是预测的恒为100个,怎么匹配呢?
匈牙利匹配完成,按照LOSS最小的组合,剩下98个都是背景
7、Transformer的神奇之处

这是论文中给出的图片,蓝色的是大的大象,橙色是小的大象,注意力机制所关注到的地方是大象的鼻子和腿,即使这个腿的重叠遮挡这么严重,还是能够区别出来两头大象
8、论文细节补充
在Decoder的左上角有一个Mx,意为多次堆叠这个过程,但是论文中提到这个堆叠每一层都做了损失计算,也就是说每层都进行了类别的分类预测和框的回归预测。
在每一层都加上监督,能够确保这个过程进行的更加好一点。