制作企业网站的步骤网络推广方案范例
vmalloc与vfree
vmalloc函数也是内核模块会使用到的一个内存分配函数,它的特点是分配的虚拟地址空间是连续的,但是这段虚拟地址空间所映射的物理地址可能是不连续的。vmalloc函数主要对vmalloc区进行操作,它返回的虚拟地址就来自于该区域。
在驱动程序中并不鼓励使用vmalloc函数,这主要是出于以下几个方面的考虑:首先,vmalloc的实现机制决定了它的使用效率没有kmalloc这样的函数高;其次,在某些体系结构比如x86上,因为物理内存通常都比较大,这使得vmalloc区域相对变得很小,对vmalloc的调用失败的可能性增大。当然在嵌入式领域,内存通常都比较小,这个问题并不是很明显;最后,vmalloc分配出的地址空间在物理上并不能保证是连续的,这对那些要求物理地址空间连续的设备比如DMA造成了麻烦。
然而,如果获得连续物理内存的可能性不是很大,那么可以通过vmalloc来用不连续的物理内存组装出一块连续的内存区域(在虚拟地址空间)。模块加载过程就使用了vmalloc来为模块的ELF文件数据分配空间,这主要是因为模块可以随时被加载进系统,如果系统运行了很长的时间而且模块的ELF文件又比较大,就很有可能无法分配出连续的物理空间来容纳ELF文件中的数据,所以内核选择用vmalloc来为模块分配空间。下面简单讨论vmalloc函数的实现原理。vmalloc函数原型为
void *vmalloc(unsigned long size)
vmalloc函数的实现可概括为三大步骤:(1)在vmalloc区分配出一段连续的虚拟内存区域。(2)通过伙伴系统获得物理页。(3)通过对页表的操作将步骤1中分配的虚拟内存映射到步骤2中获得的物理页上。在内核具体的代码实现上,步骤1利用红黑树来解决vmalloc区中动态虚拟内存块的分配和释放。对于vmalloc区中每一个分配出来的虚拟内存块,内核用struct vm_struct对象来表示。struct vm_struct定义如下:
<include/linux/vmalloc.h>
struct vm_struct {struct vm_struct *next;void *addr;unsigned long size;unsigned long flags;struct page **pages;unsigned int nr_pages;unsigned long phys_addr;void *caller;
};
其中,next用来把vmalloc区中所有已分配的struct vm_struct对象构成链表,该链表的表头为一全局变量struct vm_struct *vmlist。addr为对应虚拟内存块的起始地址,应该是页对齐。size为虚拟内存块的大小,总是页面大小的整数倍。flags为表示当前虚拟内存块映射特性的标志,目前只介绍VM_ALLOC和VM_IOREMAP,余下的标志推迟到“内存映射与DMA”再讨论:VM_ALLOC标志表示当前虚拟内存块是给vmalloc函数使用,映射的是实际物理内存(RAM);VM_IOREMAP标志表示当前虚拟内存块是给ioremap相关函数使用,映射的是I/O空间地址,也就是设备内存。pages是被映射的物理内存页面所形成的数组首地址。nr_pages表示映射的物理页的数量。phys_addr多在ioremap函数中使用,表示映射的I/O空间起始地址,页对齐。
内核总是会把vmalloc函数的参数size调整到页对齐,同时会在调整后的数值上再加一个页面的大小:
size = PAGE_ALIGN(size);
…
size += PAGE_SIZE;
内核之所以在把size对齐到页面大小之后再加上一个页面的大小,是为了防止可能出现的越界访问。因为在步骤3的页表操作中并不会向这个附加在末尾的虚拟地址上提交实际物理页面,所以当有访问进入到这个区间时,处理器将会产生异常。
步骤2中内核在调用伙伴系统获取物理内存页时,使用了GFP_KERNEL |__GFP_HIGHMEM标志,GFP_KERNEL意味着vmalloc函数在执行过程中可能睡眠,因而不可以在中断等非进程上下文中调用,__GFP_HIGHMEM标志则告诉伙伴系统在ZONE_HIGHMEM区中查找空闲页,这是因为ZONE_NORMAL区中的物理内存资源非常宝贵,主要留给kmalloc这类函数使用来获得连续的物理内存页面,因此对于vmalloc函数应该尽量使用高端的物理内存页。此外,内核在分配物理页时使用alloc_page或者是order=0情形下的alloc_pages_node函数,这意味着内核在此处是以每次只分配单个页面的形式来完成物理页的分配,这与vmalloc的设计初衷是完全吻合的:用来分配大块内存但无须保证在物理内存空间上的连续性。
步骤3没有特别需要注意的地方,唯一的一点是不对步骤1中内存区域的末尾4 KB大小部分作映射(步骤2中当然也不会为这段虚拟空间分配物理页):
<mm/vmalloc.c>
int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
{…unsigned long end = addr + area->size - PAGE_SIZE; //去掉末尾的页面不映射…
}
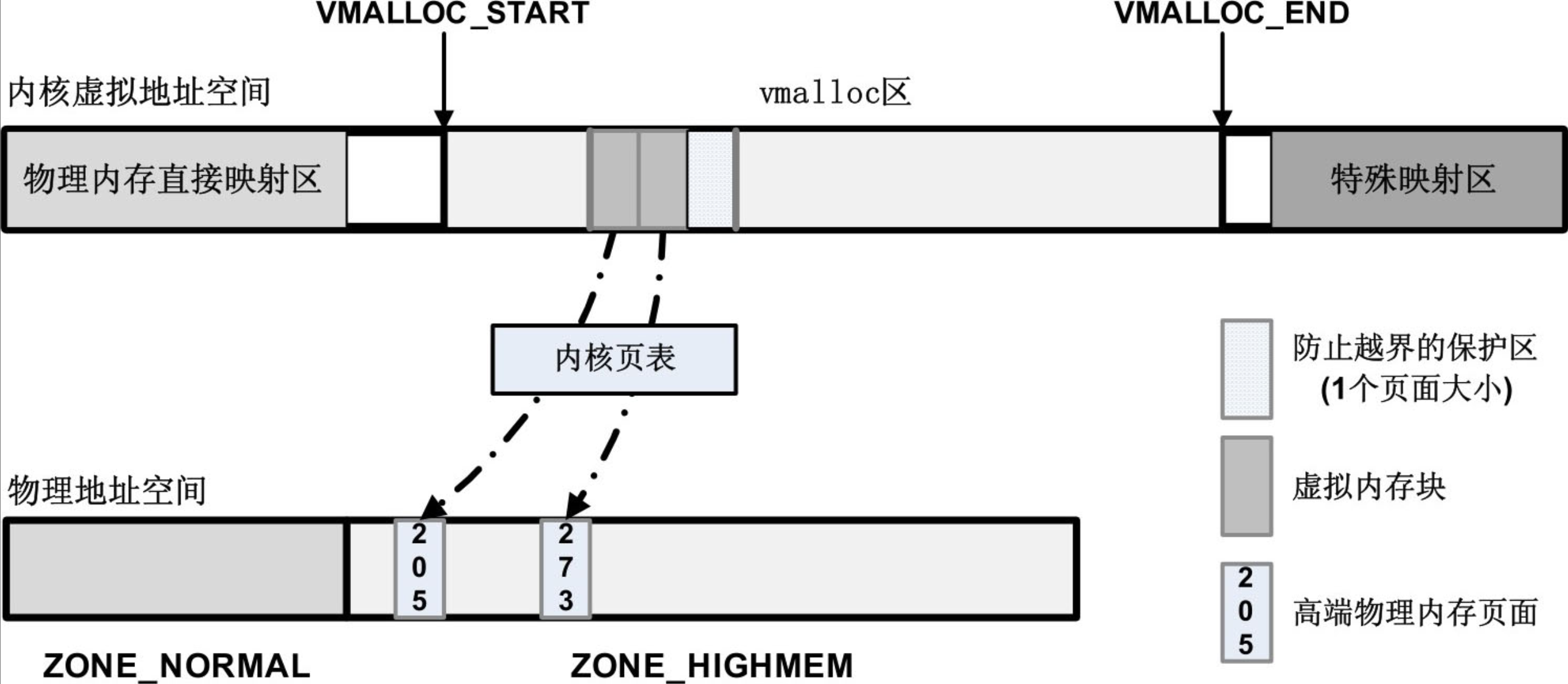
下图展示了用vmalloc函数分配内存的情形。图中在vmalloc区中分配出来的虚拟内存块通过内核页表的配置之后,被映射到了高端内存区中两个离散的物理页面205和273,虚拟内存块的最后一个页面没有映射到实际的物理页上,旨在对可能出现的越界访问起保护作用。
函数vfree用来释放vmalloc获得的虚拟地址块,它执行的是vmalloc的反操作:红黑树算法释放vmalloc生成的节点,清除内核页表中对应表项,调用伙伴系统一页一页地释放由vmalloc映射的物理页,kfree掉管理数据所占用的内存。vfree函数原型为:
void vfree(const void *addr)
ioremap
ioremap函数(宏)是体系架构相关的,其函数原型基本上等同于:
void __iomem * ioremap(unsigned long phys_addr, size_t size)
此处的__iomem的作用只是提醒调用者返回的是一io类型的地址,如同__user、__percpu一样,某些工具软件有可能会利用这些定义符作一些诸如代码质量等方面的检查。ioremap函数及其变种用来将vmalloc区的某段虚拟内存块映射到I/O空间,其实现原理与vmalloc函数基本上完全一样,都是通过在vmalloc区分配虚拟地址块,然后修改内核页表的方式将其映射到设备的内存区,也就是设备的I/O地址空间。与vmalloc函数不同的是, ioremap并不需要通过伙伴系统去分配物理页,因为ioremap要映射的目标地址是I/O空间,不是物理内存。
因为I/O空间在不同的体系架构上有不同的解释,比如IA32架构上有独立于内存访问指令之外的I/O指令,ARM的架构上则没有,所以在函数返回地址的使用上,有些要注意的地方。假设返回地址是pVaddr,对于有专门I/O指令的体系,比如IA32,不能直接用内存访问的方式来使用该地址,*pVaddr = 0x1234是错误的,应该使用readw(pVaddr),后者实际上使用了inw指令,这是IA32架构上专门的I/O指令;而在ARM处理器上,*pVaddr = 0x1234则是完全正确的。因此,为了简化不同的架构平台代码移植工作,对于ioremap返回的地址,应该统一使用readb/writeb、readw/writew这样的宏,这些宏在不同的平台上会展开成架构相关的代码。
实际代码中ioremap还有一些相关的变体,包括ioremap_nocache、ioremap_cached等,这些变体的主要功能是通过加入一些映射标志位来影响相关内核页表项的设置,比如设备驱动程序中最常用的ioremap_nocache,就是通过清除页表项中的C(ache)标志[插图],使得处理器在访问这段地址时不会被cache,这对外设空间的地址是非常重要的。如果被映射的I/O空间不再使用,应该使用iounmap函数来做相关的清除工作,iounmap函数要完成的工作包括将vmalloc区中分配的虚拟内存块返还给vmalloc区,清除对应的页表页目录项等。
per-CPU变量
per-CPU变量是Linux内核中一个非常有趣的特性,它为系统中的每个处理器都分配了该变量的一个副本。这样做的好处是,在多处理器系统中,当处理器操作属于它的变量副本时,不需要考虑与其他处理器竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓存以提高访问速度。然而不是只要使用的是per-CPU变量,在并发访问方面就一定是安全的。基于per-CPU变量的以上特性,其最典型的应用场合是在统计计数方面(为此内核源码中专门提供了基于per-CPU的一个计数器实现,感兴趣的读者可参考lib/percpu_counter.c)。例如在网络系统中,内核需要跟踪已接收到的各类数据包的数量,而这些数量在系统中更新的频率极快,每秒可能成千上万次。此时就可以使用per-CPU变量,让系统中每个处理器都使用独属于自己的该变量的副本,这样在变量更新时就无须考虑多处理器的锁定问题,可以提高性能。如果需要统计出系统接收数据包的总量,只要将各处理器副本中的值相加即可。per-CPU变量按照存储变量的空间来源可以分为静态per-CPU变量和动态per-CPU变量:前者的存储空间是在代码编译时静态分配的;后者的存储空间则是在代码的执行期间动态分配的。先讨论静态per-CPU变量。总体上说,要使一个静态per-CPU变量能够工作,除了特别的per-CPU变量声明,还必须有链接脚本和相关内核源码的配合。