网页制作与网站建设实战大全网络平台有哪些?
一、checkpoint概述
checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而且,整个任务运行的时间也特别长,比如通常要运行1~2个小时。在这种情况下,就比较适合使用checkpoint功能了。因为对于特别复杂的Spark任务,有很高的风险会出现某个要反复使用的RDD因为节点的故障导致丢失,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation算子,又要使用到该RDD时,就会发现数据丢失了,此时如果没有进行容错处理的话,那么就需要再重新计算一次数据了。所以针对这种Spark Job,如果我们担心某些关键的,在后面会反复使用的RDD,因为节点故障导致数据
丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
如何使用checkpoint?
(1)首先要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如HDFS;然后,对RDD调用checkpoint()方法。
(2)最后,在RDD所在的job运行结束之后,会启动一个单独的job,将checkpoint设置过的RDD的数据写入之
前设置的文件系统中。
二、RDD的checkpoint流程
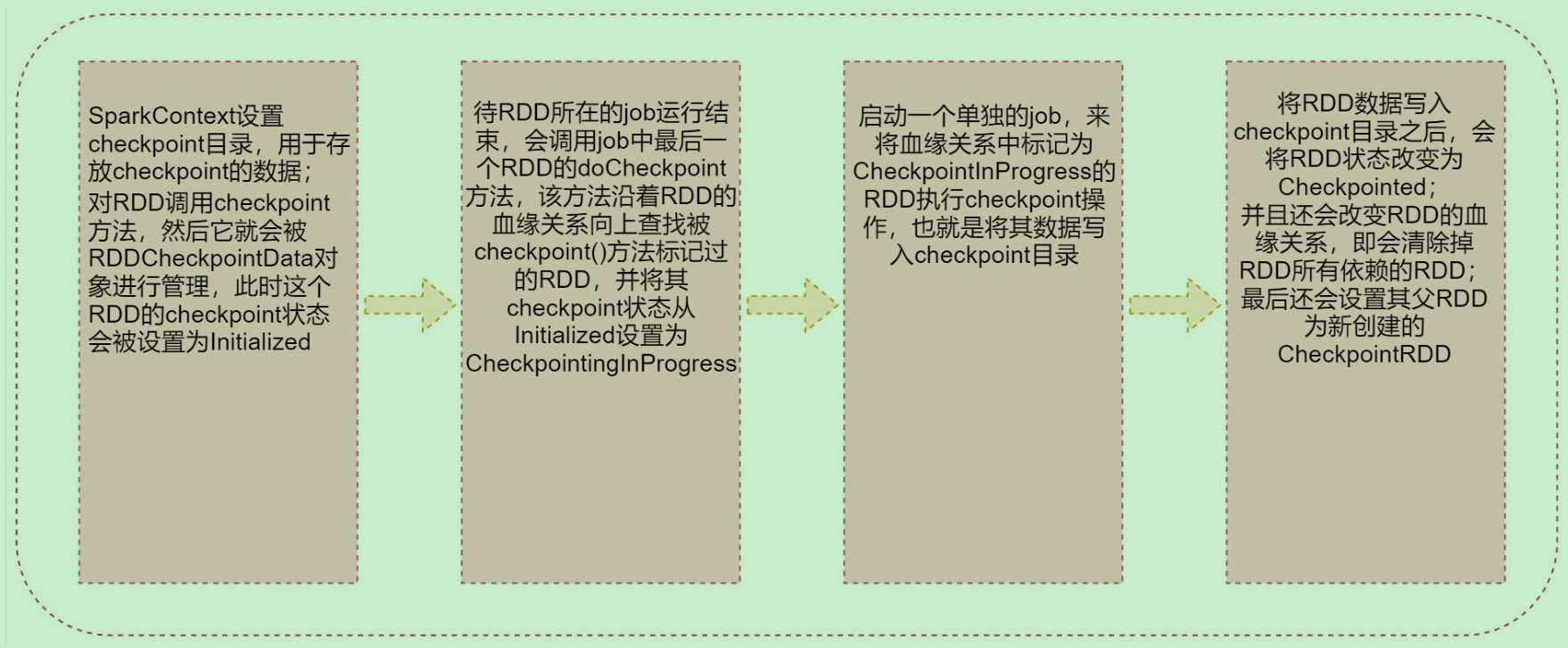
1:SparkContext设置checkpoint目录,用于存放checkpoint的数据;对RDD调用checkpoint方法,然后它就会被RDDCheckpointData对象进行管理,此时这个RDD的checkpoint状态会被设置为Initialized。
2:待RDD所在的job运行结束,会调用job中最后一个RDD的doCheckpoint方法,该方法沿着RDD的血缘关系向上查找被checkpoint()方法标记过的RDD,并将其checkpoint状态从Initialized设置为
CheckpointingInProgress
3:启动一个单独的job,来将血缘关系中标记为CheckpointInProgress的RDD执行checkpoint操作,也就是将其数据写入checkpoint目录
4:将RDD数据写入checkpoint目录之后,会将RDD状态改变为Checkpointed;并且还会改变RDD的血缘关系,即会清除掉RDD所有依赖的RDD;最后还会设置其父RDD为新创建的CheckpointRDD
三、checkpoint与持久化的区别
(1)lineage是否发生改变。
lineage(血缘关系)说的就是RDD之间的依赖关系,持久化只是将数据保存在内存中或者本地磁盘文件中,RDD的lineage(血缘关系)是不变的;Checkpoint执行之后,RDD就没有依赖的RDD了,也就是它的lineage改变了。
(2)丢失数据的可能性。
持久化的数据丢失的可能性较大,如果采用 persist 把数据存在内存中的话,虽然速度最快但是也是最不可靠的,就算放在磁盘上也不是完全可靠的,因为磁盘也会损坏。Checkpoint的数据通常是保存在高可用文件系统中(HDFS),丢失的可能性很低
建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)
为什么呢因为默认情况下,如果某个RDD没有持久化,但是设置了checkpoint,那么这个时候,本来Spark任务已经执行结束了,但是由于中间的RDD没有持久化,在进行checkpoint的时候想要将这个RDD的数据写入外部存储系统的话,就需要重新计算这个RDD的数据,再将其checkpoint到外部存储系统中。如果对需要checkpoint的rdd进行了基于磁盘的持久化,那么后面进行checkpoint操作时,就会直接从磁盘上读取rdd的数据了,就不需要重新再计算一次了,这样效率就高了。那在这能不能使用基于内存的持久化呢?当然是可以的,不过没那个必要。
四、checkpoint的使用
1. scala代码
package com.sanqian.scalaimport org.apache.spark.api.java.StorageLevels
import org.apache.spark.{SparkConf, SparkContext}object CheckPointScala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("CheckPointScala")val sc = new SparkContext(conf)if (args.length == 0) {System.exit(100)}val outoutPath = args(0)// 1.设置checkpoint目录\sc.setCheckpointDir("hdfs://bigdata01:9000/chk001")val dataRDD = sc.textFile("hdfs://bigdata01:9000/hadoop")dataRDD.persist(StorageLevels.DISK_ONLY)// 2.对RDD执行checkpoint操作dataRDD.checkpoint()dataRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(outoutPath)sc.stop()}
}
2. Java代码
package com.sanqian.java;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.Arrays;
import java.util.Iterator;public class CheckPointJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setAppName("CheckPointJava");JavaSparkContext sc = new JavaSparkContext(conf);if (args.length == 0){System.exit(100);}String outputPath = args[0];// 1.设置checkpoint目录sc.setCheckpointDir("hdfs://bigdata01:9000/chk001");JavaRDD<String> rdd = sc.textFile("hdfs://bigdata01:9000/hadoop");// 2.对RDD执行checkpoint操作rdd.checkpoint();rdd.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).iterator();}}).mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<String, Integer>(word, 1);}}).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}}).saveAsTextFile(outputPath);sc.stop();}
}
3. 打包代码
(1)将pom.xml中的spark-core的依赖设置为provided,然后编译打包
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.3</version><scope>provided</scope></dependency>(2)D:\ProgramData\IdeaProjects\db_spark>mvn clean package -DskipTests
(3)将打包的jar包上传到bigdata04的/data/soft/sparkjars目录,创建一个新的spark-submit脚本
spark-submit \
--class $1 \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 1 \
db_spark-1.0-SNAPSHOT.jar \
$2(4)提交任务:
sh lwx_run.sh com.sanqian.scala.CheckPointScala /out-chk003执行成功之后可以到 setCheckpointDir 指定的目录中查看一下,可以看到目录中会生成对应的文件保存rdd中的数据,只不过生成的文件不是普通文本文件,直接查看文件中的内容显示为乱码。