网站建设订单模板下载外贸seo公司
深度学习训练营之训练自己的数据集
- 原文链接
- 环境介绍
- 准备好数据集
- 划分数据集
- 运行voc_train.py
- 遇到问题
- 完整代码
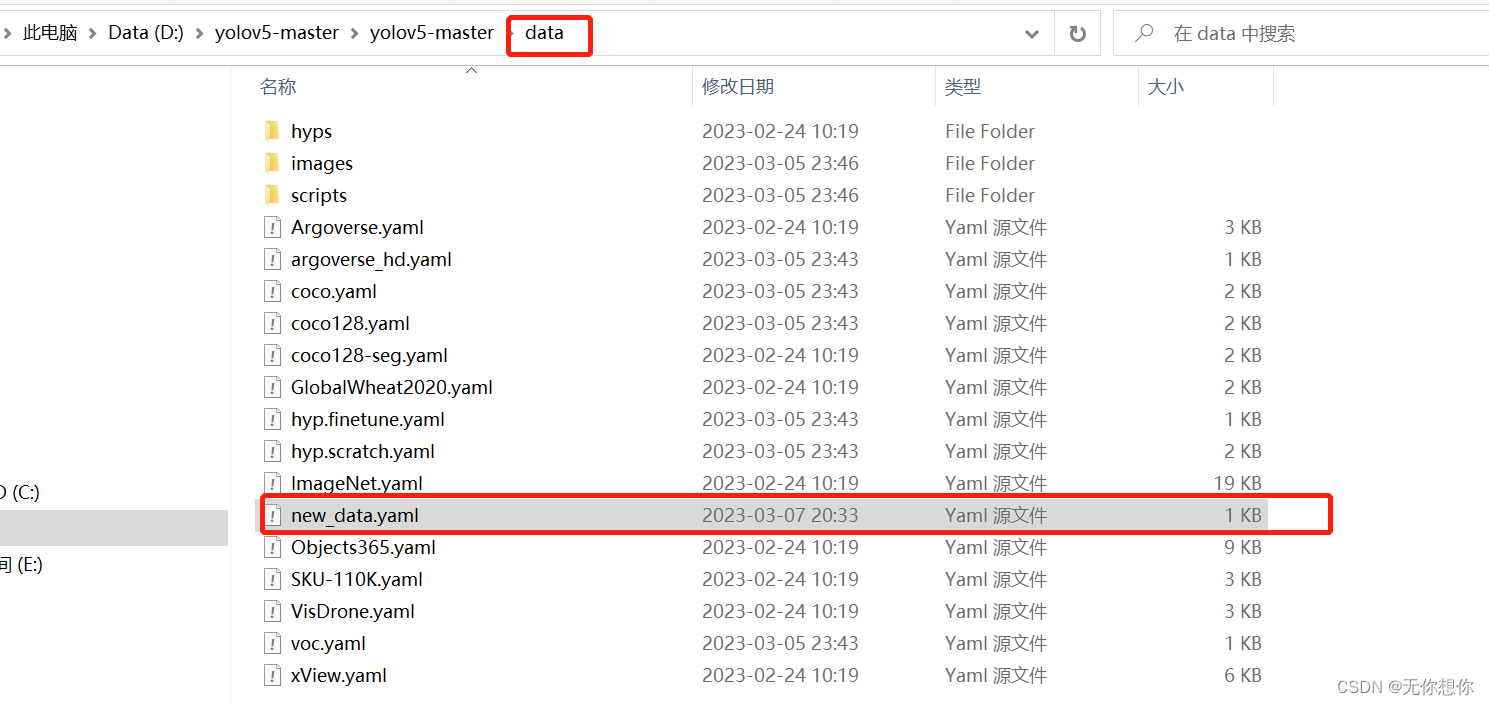
- 创建new_data.yaml文件
- 模型训练时遇到的报错
- 模型训练
- 结果可视化
- 参考链接
原文链接
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第Y2周:训练自己的数据集
- 🍖 原作者:K同学啊|接辅导、项目定制
环境介绍
- 语言环境:Python3.9.13
- 编译器:vscode
- 深度学习环境:torch
- 显卡:NVIDIA GeForce RTX 3070 Laptop GPU
准备好数据集
我这里采用的数据集是经典的目标检测算法当中的一个数据集,这里附上链接:
文件提取:链接:https://pan.baidu.com/s/1SuNxOTCgrQlqXWK_cRzCZQ
提取码:0909
文件夹下内容:

划分数据集
运行如下命令进行数据集的划分
python split_train_val.py --xml_path D:\yolov5-master\yolov5-master\my_data\Annotations --txt_path D:\yolov5-master\yolov5-master\my_data\ImageSets\Main
原始应该是这样
python split_train_val.py --xml_path xx --txt_path xx
其中xx的地方根据相应的路径进行更改,需要注意到的是运行的路径是函数python split_train_val.py所在的文件夹下进行运行,否则会报错

在弹出的对话框中进行运行

可以看到已经成功生成了
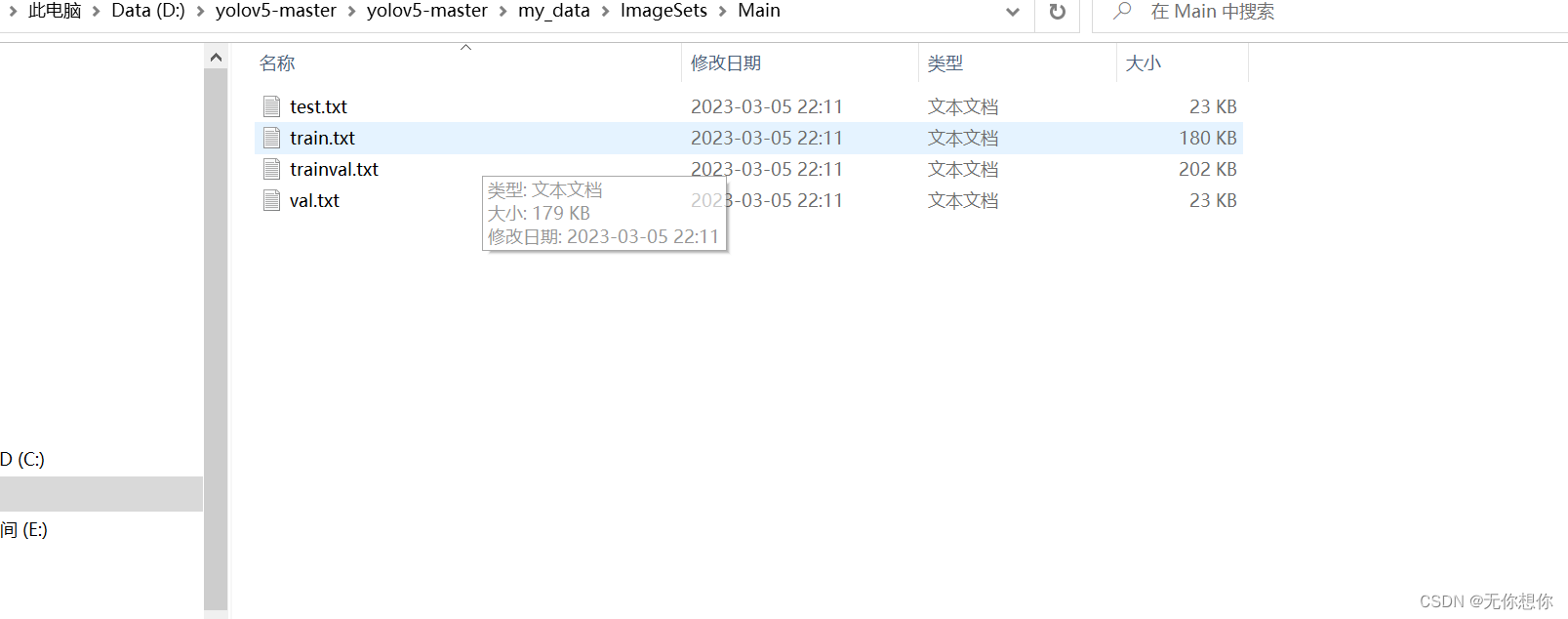
运行voc_train.py
遇到问题
遇到如下报错unsupported operand type(s) for +: 'builtin_function_or_method' and 'str'
这里所说的意思应该是指不能将type(s)类型的字符加上一个函数或者方法,我简单查看了一些,是我在定义abs_path的时候漏加括号,导致abs_path的字符类型出现错误

完整代码
经过调试和更改路径之后得到的代码如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train','val','test']# 20类
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog","horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
abs_path=os.getcwd()
print(abs_path)
# size w,h
# box x-min,x-max,y-min,y-max
def convert(size, box):dw = 1./size[0]dh = 1./size[1]x = (box[0] + box[1])/2.0 -1# 中心点位置y = (box[2] + box[3])/2.0 -1w = box[1] - box[0]h = box[3] - box[2]x = x *dww = w *dwy = y *dhh = h *dh # 全部转化为相对坐标return (x, y, w, h)def convert_annotation(image_id):# 找到2个同样的文件in_file = open('Annotations/%s.xml' % (image_id),encoding='UTF-8')out_file = open('labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1: #difficult ==1 的不要了continuecls_id = classes.index(cls) # 排在第几位xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))# 传入的是w,h 与框框的周边b1,b2,b3,b4=bif b2>w:b2=wif b4>h:b4=hb=(b1,b2,b3,b4)bb = convert((w, h), b)out_file.write(str(cls_id) +" "+" ".join([str(a) for a in bb]) + '\n')wd = getcwd()for image_set in sets:# ('2012', 'train') 循环5次# 创建目录 一次性if not os.path.exists('labels/' ):os.makedirs('labels/')# 图片的id数据image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()# 结果写入这个文件list_file = open('%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path+'/JPEGImages/%s.jpg\n' % (image_id)) # 补全路径convert_annotation(image_id)list_file.close()
(记录一下:一开始这个最后的JPEGImages没加斜杠,导致后续报错,这里是添加过后的)
运行val_voc.py可以得到三个txt的文件,其内容如下:
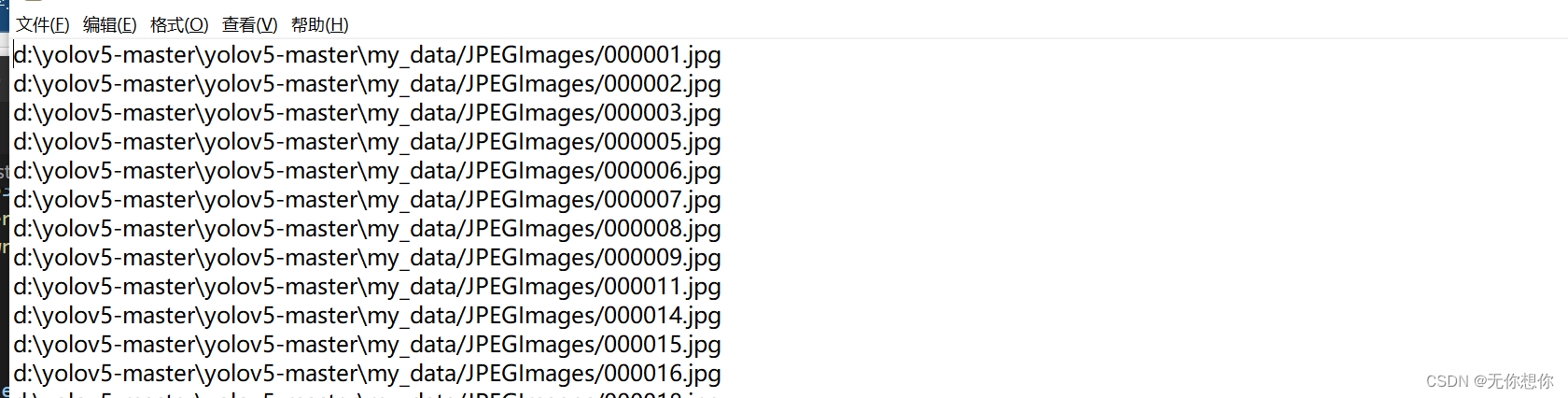
创建new_data.yaml文件
这个文件的名称new_data.yaml是我自己随便起的一个名字,大家可以自行更改
模型训练时遇到的报错
expected '<document start>', but found '<scalar>'
这里主要的原因是在定义变量的时候我使用的是=,但是应该用:
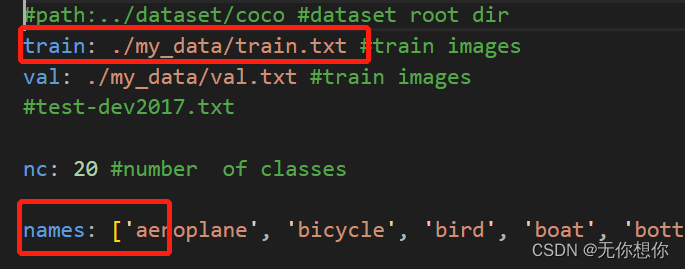
错误图片:(这里突然发现这个mydata当中trian和val的名字不一样,导致后面一系列的错误,我后面改完之后就行)
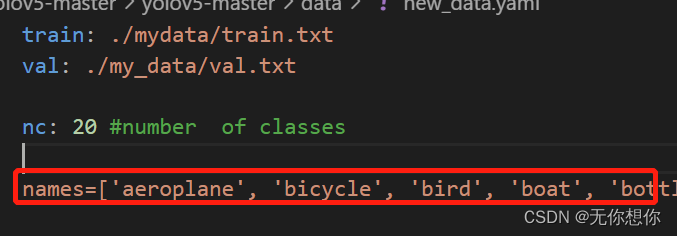
更正以后:
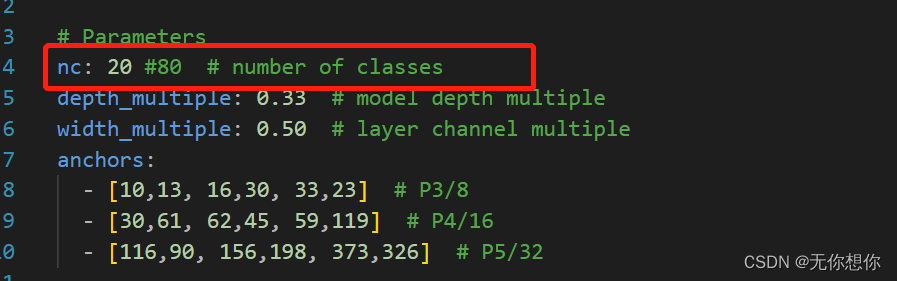
models文件夹下的用于训练的yolov5s.yaml
把这个原本的分类从80改成20(20是我的数据集的类型)
模型训练
运行如下命令,开始训练
python train.py --img 928 --batch 2 --epoch 10 --data data/new_data.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt
出现以下报错(没有出现就是成功训练啦)
No labels found in D:\yolov5-master\yolov5-master\my_data\train.cache.
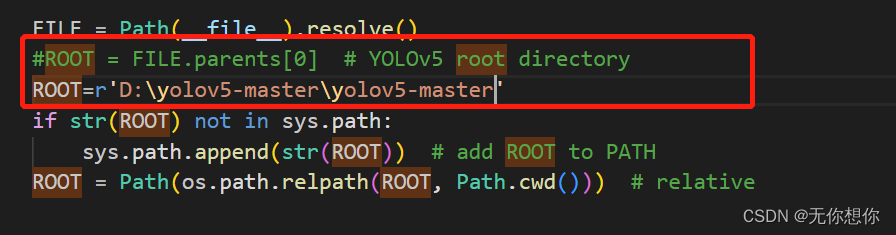
在train.py当中更改成绝对路径
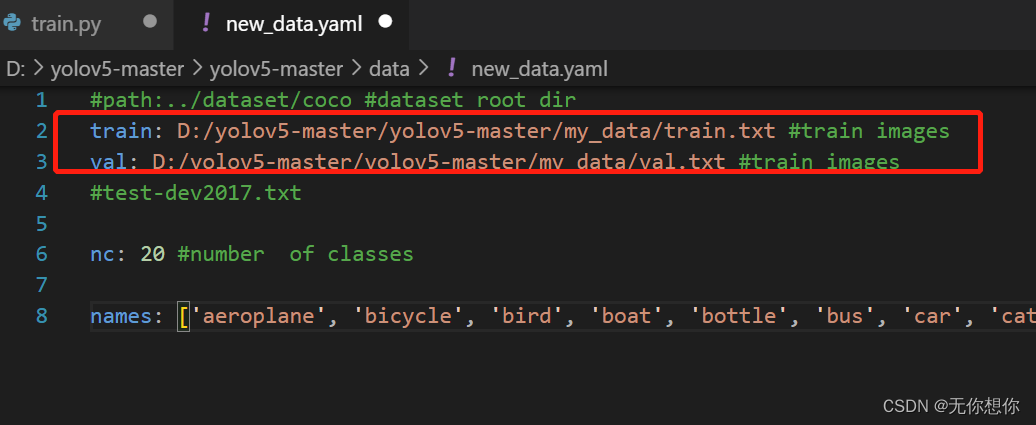
new_data.yaml也进行修改
更改D:\yolov5-master\yolov5-master\utils当中的sa,sb的路径
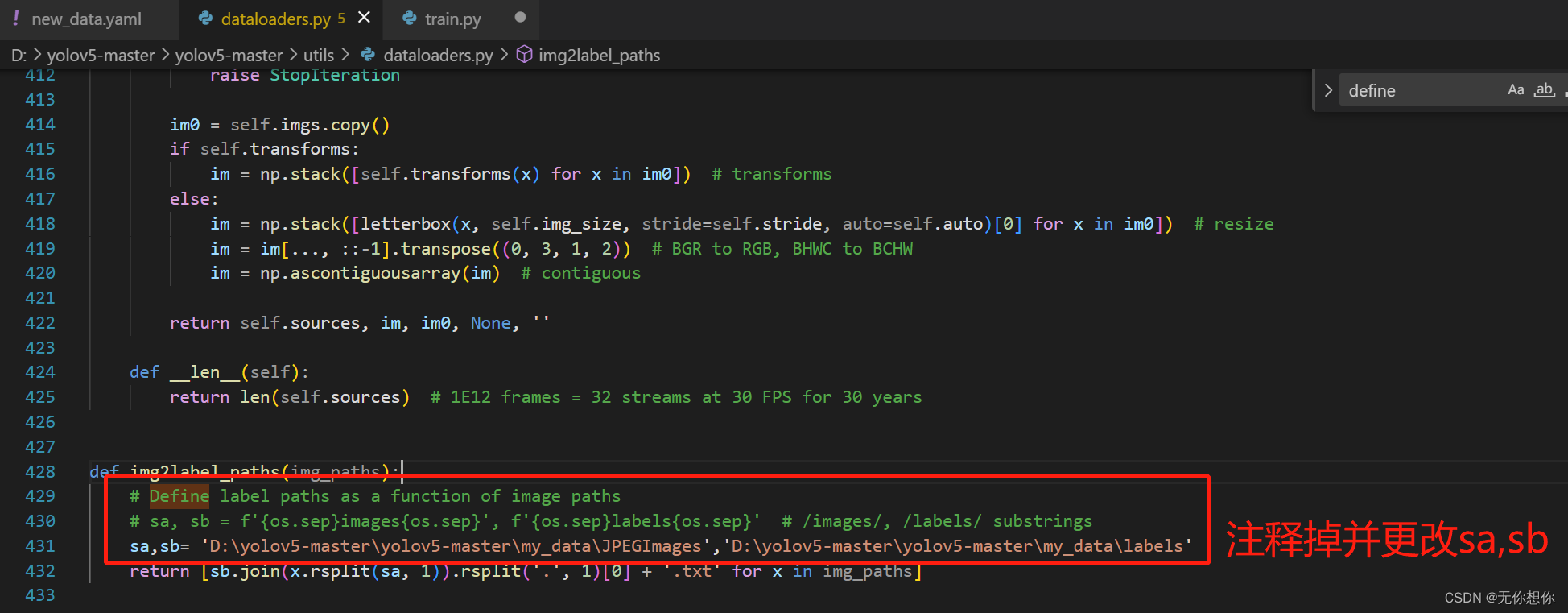
开始运行…
结果可视化
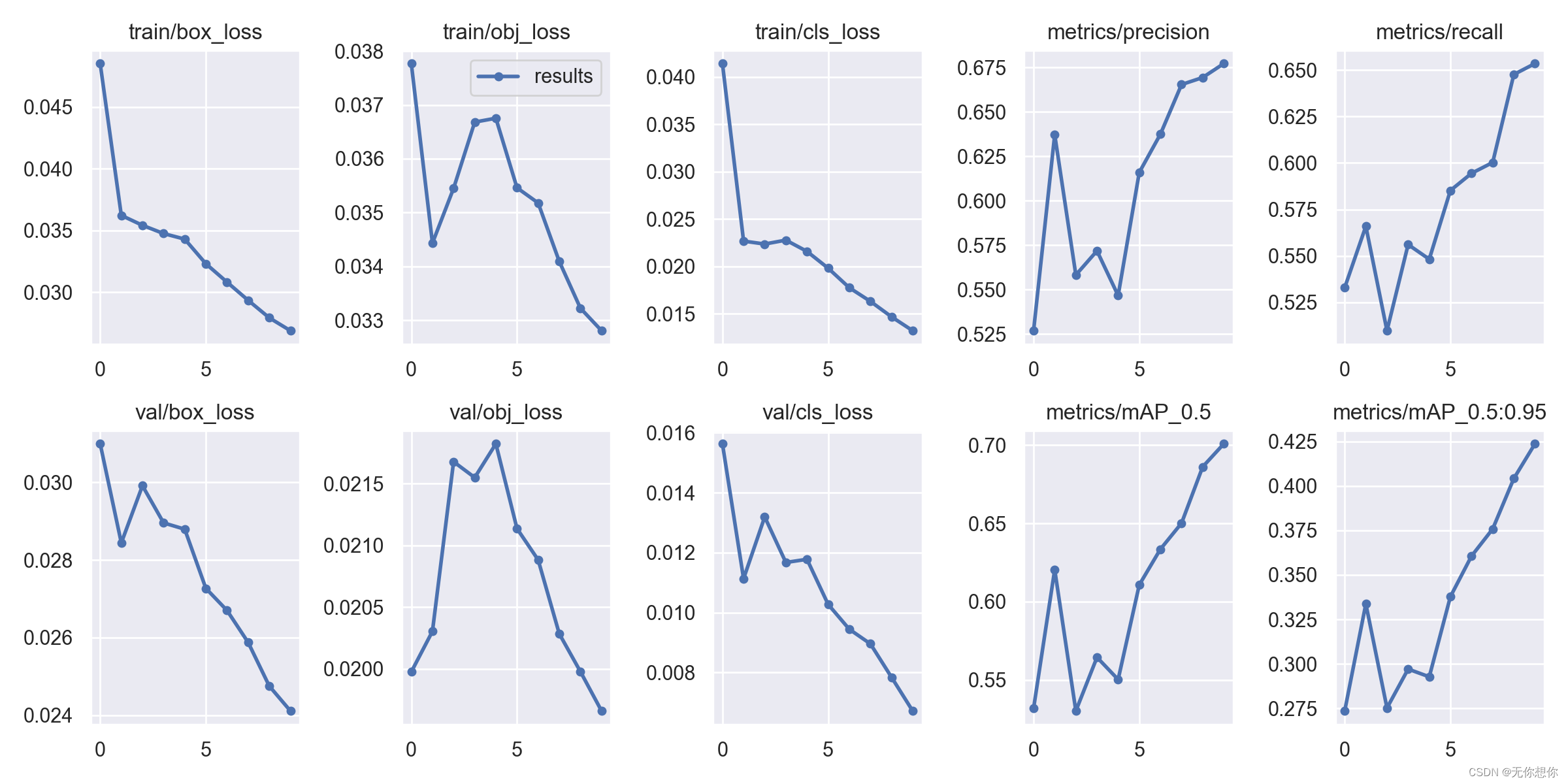
运行结果如下
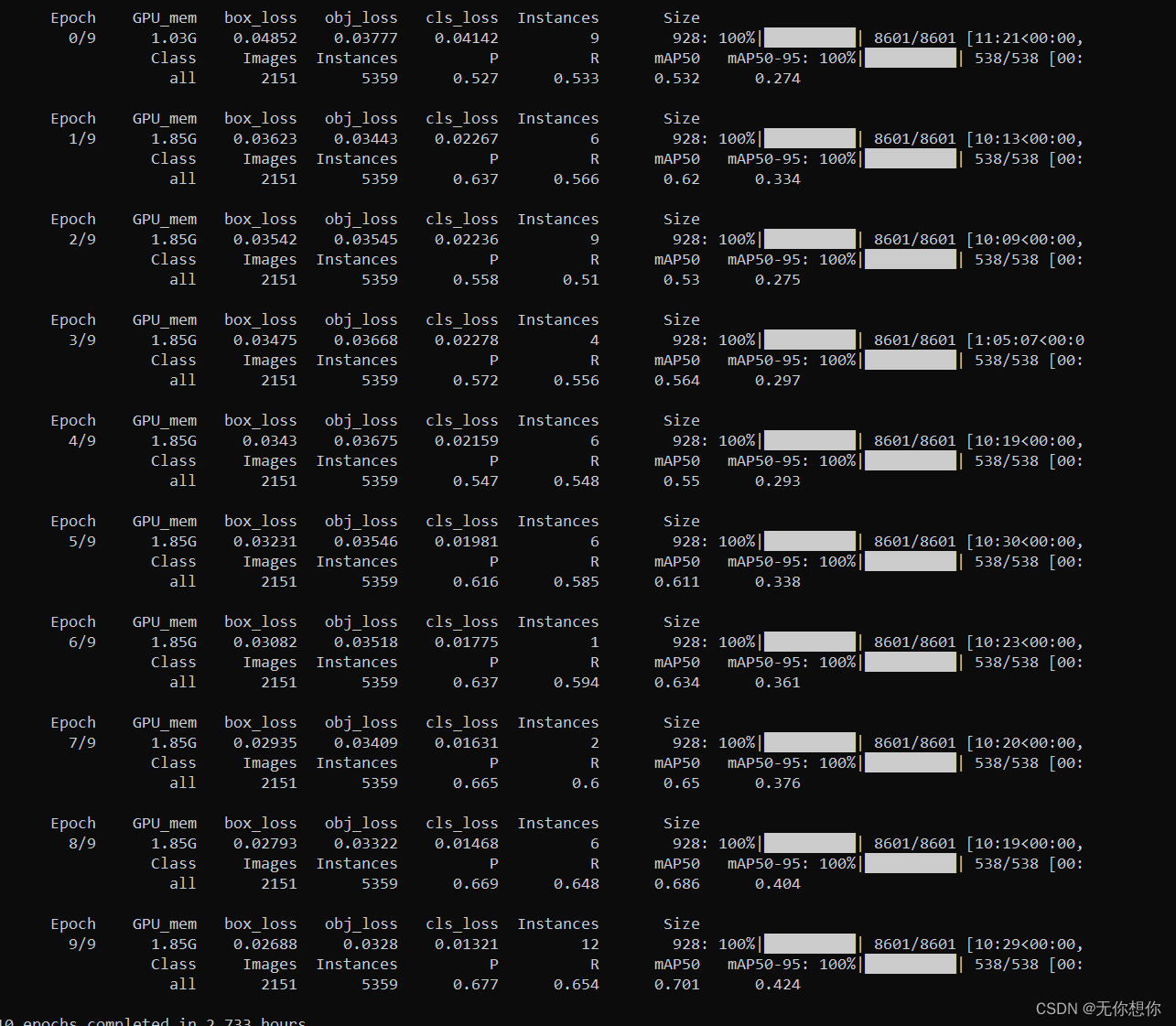
使用wandb可以看到我们的运行结果的一些可视化
参考链接
- yolov5数据读取报错:train: No labels found in /root/yolov5-master/VOCData/dataSet_path/train.cache
- Python编译报错的自我记录