在国外做h网站怎么样河南关键词排名顾问
说明
这部分应该是Multi-Armed Bandit的最后一部分了。
内容
1 On Line Ads
这个实验,最初的目的就是为了选出最佳的广告。首先,通过伯努利分布,模拟了某个广告的有效率。在真实场景里,我们是无法知道那个广告更好的。可能在train阶段,可以获得一些模糊的参考,但是使用强化学习的目的,就是让其随着现实返回进行自发调整。
可以把一个模型,或者一个版本视为一个bandit。强化框架的意义在于最大化的利用已有的一套bandit,在过程中,最优的bandit会自动浮现,从而解开最初建模阶段的一些迷惑。
class BernoulliBandit(object):def __init__(self, p):self.p = pdef display_ad(self):reward = np.random.binomial(n=1, p=self.p)return rewardadA = BernoulliBandit(0.004)
adB = BernoulliBandit(0.016)
adC = BernoulliBandit(0.02)
adD = BernoulliBandit(0.028)
adE = BernoulliBandit(0.031)ads = [adA, adB, adC, adD, adE]
2 强化学习
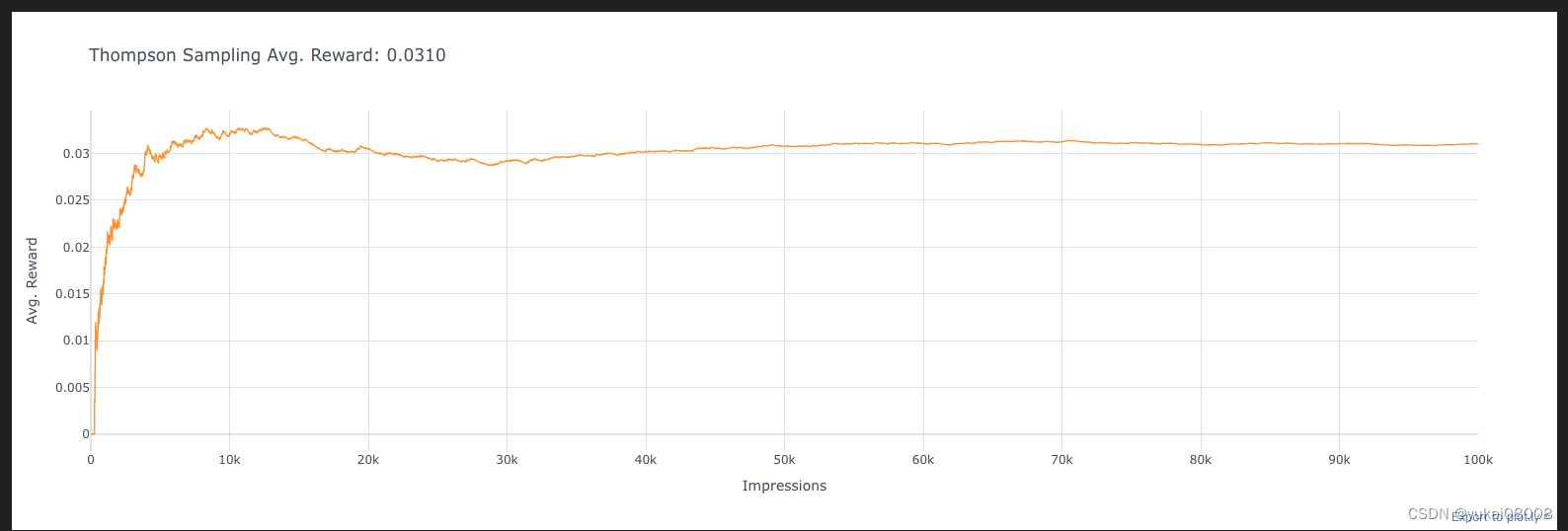
在之前的样例中,我们已经尝试了A/B/n test 、eps greedy、UCB等三个方法,现在是最后一种方法Thompson Sampling
初始化过程 :
这段代码看起来像是为Multi-Armed Bandit Proble 中的 Thompson Sampling 算法做准备。Thompson Sampling 是一种用于解决探索-利用困境的随机化算法,它基于贝叶斯方法,在每个时间步骤根据先验分布和观察到的奖励来更新每个臂的概率分布。
在 Thompson Sampling 中,每个臂都有一个 Beta 分布,其中 α 参数表示已经获得的奖励次数,β 参数表示已经尝试的次数减去获得奖励的次数。在每个时间步骤,根据每个臂的 Beta 分布随机抽样,选择具有最大样本值的臂作为当前时间步的动作。
n_prod = 100000
n_ads = len(ads)
alphas = np.ones(n_ads)
betas = np.ones(n_ads)
total_reward = 0
avg_rewards = []for i in range(n_prod):theta_samples = [np.random.beta(alphas[k], betas[k]) for k in range(n_ads)]ad_chosen = np.argmax(theta_samples)R = ads[ad_chosen].display_ad()alphas[ad_chosen] += Rbetas[ad_chosen] += 1 - Rtotal_reward += Ravg_reward_so_far = total_reward / (i + 1)avg_rewards.append(avg_reward_so_far)
df_reward_comparison['Thompson Sampling'] = avg_rewards
这段代码做了以下几件事情:
对于每个时间步骤 i,从每个臂的 Beta 分布中采样一个值 theta_samples。
选择具有最大 theta_samples 的臂作为当前时间步骤的动作 ad_chosen。
显示所选择广告,并获取奖励 R。
根据获得的奖励更新所选臂的 Alpha 和 Beta 参数。
计算当前总奖励 total_reward 和平均奖励 avg_reward_so_far。
将平均奖励添加到 avg_rewards 列表中。
将 avg_rewards 列表添加到 DataFrame 中,命名为 ‘Thompson Sampling’。
3 UCB
这个漏掉了,补一下
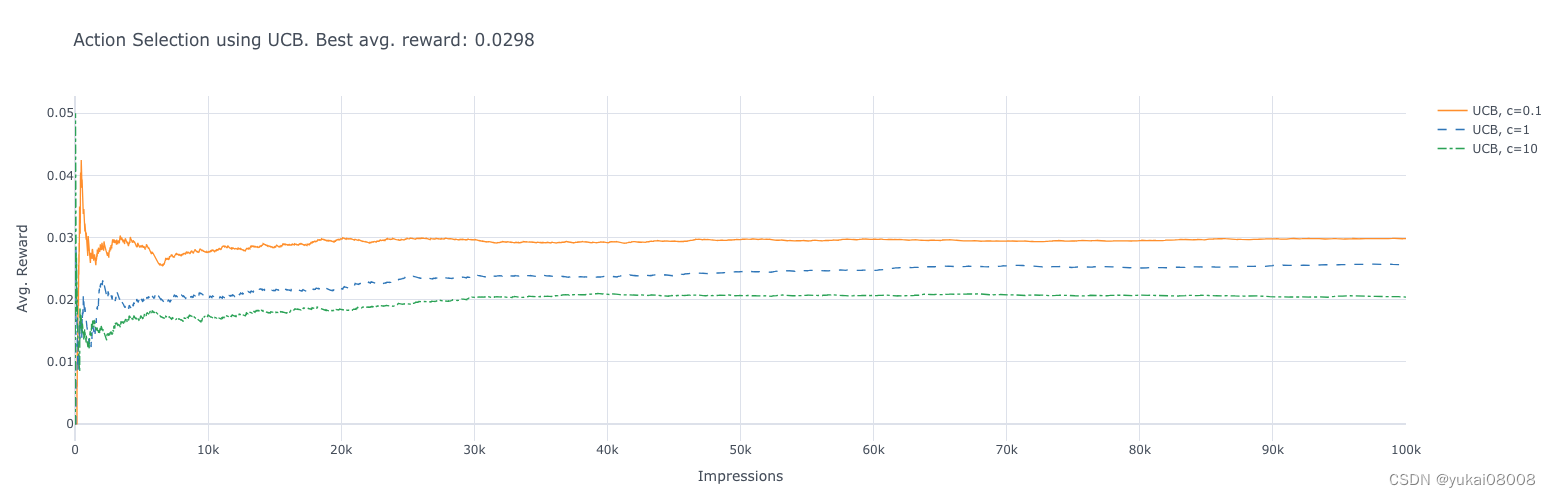
分别使用3个参数分别跑
# c = 0.1
# c = 1
c =10
n_prod = 100000
n_ads = len(ads)
ad_indices = np.array(range(n_ads))
Q = np.zeros(n_ads)
N = np.zeros(n_ads)
total_reward = 0
avg_rewards = []for t in range(1, n_prod + 1):if any(N==0):ad_chosen = np.random.choice(ad_indices[N==0])else:uncertainty = np.sqrt(np.log(t) / N)ad_chosen = np.argmax(Q + c * uncertainty)R = ads[ad_chosen].display_ad()N[ad_chosen] += 1Q[ad_chosen] += (1 / N[ad_chosen]) * (R - Q[ad_chosen])total_reward += Ravg_reward_so_far = total_reward / tavg_rewards.append(avg_reward_so_far)df_reward_comparison['UCB, c={}'.format(c)] = avg_rewards
这段代码实现了上限置信区间(Upper Confidence Bound, UCB)算法。UCB算法通过平衡探索(Exploration)和利用(Exploitation)来选择动作。其中,参数c用于调整探索与利用之间的权衡。
这段代码中,c 参数用于控制探索的程度。较大的 c 值将会更加强调探索,而较小的 c 值则更加强调利用。
这段代码的逻辑如下:
如果有至少一个广告的点击次数为零,则在这些广告中随机选择一个。
否则,计算每个广告的置信区间上界,并选择置信区间上界最大的广告。
显示所选择的广告,并获取奖励。
更新所选广告的点击次数和平均奖励。
计算当前总奖励和平均奖励,将平均奖励添加到列表中。
将平均奖励列表添加到 DataFrame 中,命名为 ‘UCB, c={}’。
4 Next
Review一下这一章,然后找一个具体的实用样例来进行实测,最后发布为前后端微服务。