最新新闻热点事件2023摘抄宁波核心关键词seo收费
XPath数据提取与贴吧爬虫应用示例
- Xpath
- Xpath概述
- Xpath Helper插件
- XPath语法
- 基本语法
- 查找特定节点
- 选取未知节点
- 选取若干路径
- lxml模块
- 使用说明
- 使用示例
- 百度贴吧爬虫
Xpath
Xpath概述
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。它提供了一种简洁的方式来遍历和提取XML文档中的数据。
XPath使用路径表达式来选取XML文档中的节点或者节点集。
简言之,Xpath是通过一定的语法规则从HTML、XML文件中提取需要的数据。
Xpath Helper插件
XPath Helper是一款浏览器插件,可用于在浏览器中轻松测试和调试XPath表达式。它提供了一个用户友好的界面,能够直接在浏览器中输入XPath表达式,并立即查看匹配的结果。
通过XPath Helper插件,可以快速验证和调试XPath表达式,以确保它们能够准确地选择所需的节点。
使用XPath Helper插件的步骤:
安装XPath Helper插件:在谷歌浏览器的插件商店中搜索XPath Helper,并按照指示进行安装。打开要调试的网页:在浏览器中打开包含XML或HTML文档的网页。启动XPath Helper插件:在浏览器工具栏中找到XPath Helper插件的图标,并点击它以打开插件界面。输入XPath表达式:在XPath Helper插件界面的输入框中输入XPath表达式。查看结果:XPath Helper插件将立即在页面上显示与XPath表达式匹配的节点。
进入chrome应用商店,搜索XPath Helper进行下载。
下载链接:XPath Helper
XPath语法
基本语法
提取属性或文本内容
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素 |
| / | 从根节点选取、或者是元素和元素间的过渡 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
示例
| 路径表达式 | 说明 |
|---|---|
| //h1/text() | 选择所有的h1下的文本 |
| //a/@href | 获取所有的a标签的href属性 |
| /html/head/title/text() | 获取html下的head下的title的文本 |
| //div/h2 | 选取属于div的子元素的所有h2标签 |
查找特定节点
可以根据标签的属性值、下标等来获取特定的节点
在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=“en”] | 选择lang属性值为en的所有title元素 |
| /people/user[1] | 选择属于 people 子元素的第一个 user元素 |
| /people/user[last()] | 选择属于people子元素的最后一个 user元素 |
| /people/user[last()-1] | 选择属于 people子元素的倒数第二个 user元素 |
| /people/user[position()>1] | 选择people下面的user元素,从第二个开始选择 |
| //user/title[text()=‘Java’] | 选择所有user下的title元素,仅选择文本为Java的title元素 |
| //user/title[contains(text(),‘Java’)] | 选择所有user下的title元素,仅选择文本包含Java的title元素 |
| //user/title[starts-with(text(),‘Java’)] | 选择所有user下的title元素,仅选择文本 以Java开头的title元素 |
| /people/user[age>20]/title | 选择people元素中的 user元素的所有 title 元素,且其中的 age元素的值须大于20 |
选取未知节点
通过通配符来选取未知的html、xml的元素
| 通配符 | 描述 |
|---|---|
* | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
示例
| 路径表达式 | 说明 |
|---|---|
| /people/* | 选取people元素的所有子元素 |
| //* | 选取文档中的所有元素 |
| //title[@*] | 选取所有带有属性的 title 元素 |
| //node() | 匹配任何类型的节点 |
选取若干路径
通过在路径表达式中使用“|”运算符,可以选取若干个路径
| 路径表达式 | 结果 |
|---|---|
| //user/name丨 //user/age | 选取user元素的所有 name和age元素 |
| //name丨 //age | 选取文档中的所有name和age元素 |
| /people/user/name丨 //age | 选取属于people元素的user元素的所有name元素,以及文档中所有的age元素 |
lxml模块
在Python中,可以使用第三方库lxml来解析和处理XML文档,并使用lxml库提供的XPath函数来执行XPath查询。
安装
pip install lxml
使用说明
导入lxml的etree库
from lxml import etree
可以将bytes类型和str类型的数据转化为Element对象,该对象具有xpath的方法,返回结果列表
# 可以自动补全标签
html = etree.HTML(data) list = html.xpath("xpath表达式")
返回列表存在三种情况
返回空列表:根据xpath语法规则字符串,没有定位到任何元素返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
Element对象转化为字符串,返回bytes类型结果
etree.tostring(element)
使用示例
创建test.html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<div><ul><li class="class01"><span index="1">H1</span></li><li class="class02"><span index="2" class="span2">H2</span></li><li class="class03"><span index="3">H3</span></li></ul></div>
</body>
</html>
使用lxml模块提取test.html文件数据
# 导入lxml的etree库
from lxml import etreedata = None
with open("test.html", 'r', encoding='UTF-8') as f:data = f.read()f.close()# 将字符串转化为Element对象。能够接受bytes类型和str类型的数据
html = etree.HTML(data)
# Element对象具有xpath的方法,返回结果列表
print("获取所有li标签: ", html.xpath('//li'))
print("获取所有span标签的内容: ", html.xpath('//span/text()'))
print("获取li标签的所有class属性: ", html.xpath('//li/@class'))
print("获取li标签下index属性=2为的span标签: ", html.xpath('//li/span[@index="2"]'))
print("获取li标签下的span标签里的有class的标签: ", html.xpath('//li/span/@class'))
print("获取最后一个li标签的span标签的index属性值: ", html.xpath('///li[last()]/span/@index'))
print("获取倒数第二个li元素的内容: ", html.xpath('//li[last()-1]//text()'))
提取结果
获取所有li标签: [<Element li at 0x247cb1ea880>, <Element li at 0x247cb1ea8c0>, <Element li at 0x247cb1ea900>]
获取所有span标签的内容: ['H1', 'H2', 'H3']
获取li标签的所有class属性: ['class01', 'class02', 'class03']
获取li标签下index属性=2为的span标签: [<Element span at 0x247cb1eaa40>]
获取li标签下的span标签里的有class的标签: ['span2']
获取最后一个li标签的span标签的index属性值: ['3']
获取倒数第二个li元素的内容: ['H2']
百度贴吧爬虫
百度贴吧:https://tieba.baidu.com/f?kw=王者荣耀&ie=utf-8&pn=50
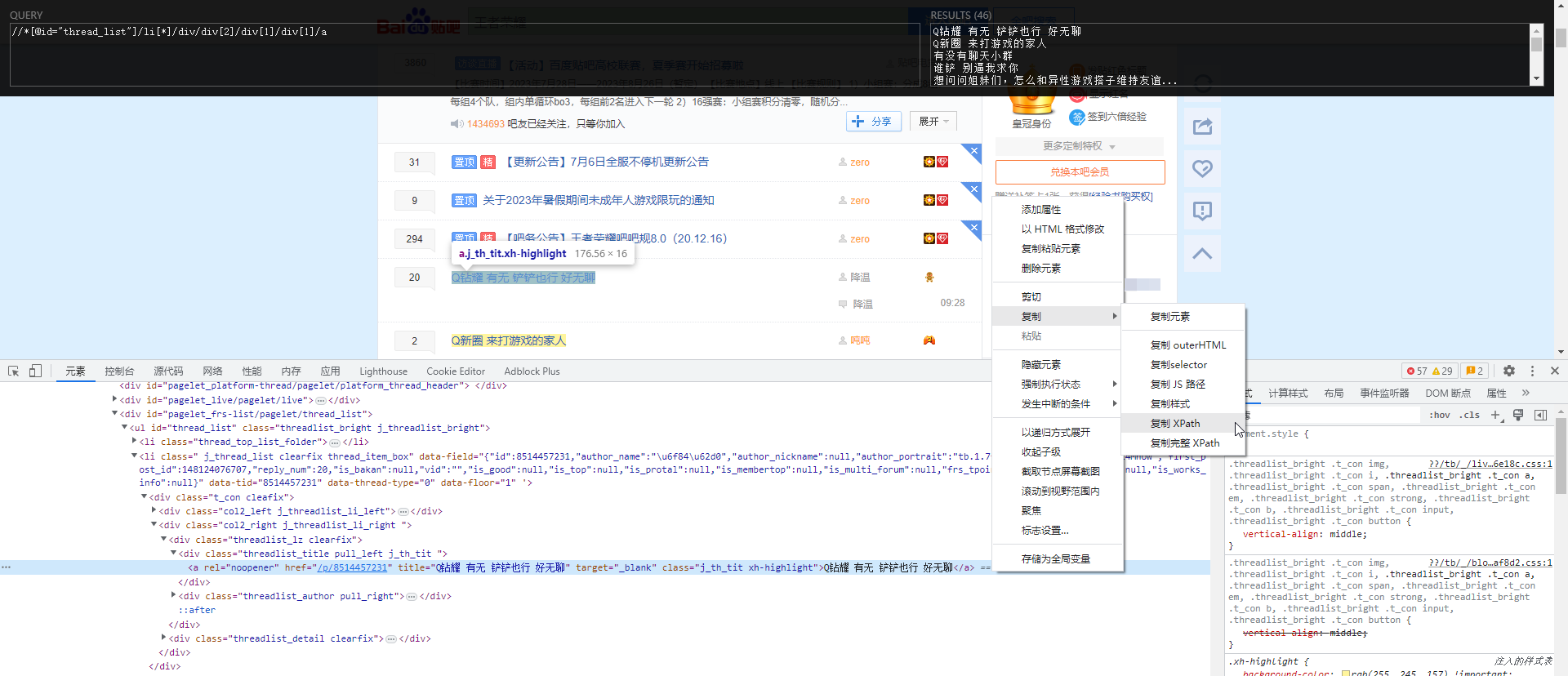
浏览器进行元素选择,复制XPath路径表达式,打开Xpath Helper插件进行调试,辅助进行数据提取。
Xpath Helper插件使用示例:
import datetime
import json
from time import sleepimport requests
from lxml import etreeclass TiebaSpider():def __init__(self, kw, max_pn, fileName):self.base_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}"self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"}self.kw = kwself.max_pn = max_pnself.fileName = fileNamepassdef get_url_list(self):'''return [self.base_url.format(self.kw,pn) for pn in range(0,self.max_pn + 1,50)]'''url_list = []for pn in range(0, self.max_pn + 1, 50):url = self.base_url.format(self.kw, pn)url_list.append(url)return url_listdef get_content(self, url):response = requests.get(url=url,headers=self.headers)return response.contentdef get_items(self, content, idx):# 注意:响应页面需要抓取数据是被注释了的。处理方式2种:1.替换注释 2.使用低版本浏览器的响应头html = content.decode('utf-8').replace("<!--", "").replace("-->", "")eroot = etree.HTML(html)# 提取行数据li_list = eroot.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')data = []for li in li_list:item = {}item["title"] = li.xpath('./text()')[0]item["link"] = 'https://tieba.baidu.com' + li.xpath('./@href')[0]data.append(item)# next_url = 'https:' + eroot.xpath('//*[@id="frs_list_pager"]/a/@href')return datadef save_items(self, items, fileName):for data in items:print(data)# 将字典转换为字符串,将字符串编码为UTF-8字节流data_str = json.dumps(data).encode("utf-8")self.write(data_str, fileName)def write(self, item, fileName):# 打开文件进行追加写入with open(fileName, "a") as file:# 写入数据 将字节流解码为字符串file.write(item.decode("utf-8"))file.write("\n")def run(self):# 获取url列表url_list = self.get_url_list()fileName = self.fileNamefor url in url_list:print("*" * 100)# 发送请求获取响应content = self.get_content(url)sleep(5)# 从响应中提取数据items = self.get_items(content, url_list.index(url) + 1)# 保存数据self.save_items(items, fileName)passif __name__ == '__main__':user_input = input("请输入贴吧名称: ")# 获取当前日期和时间current_datetime = datetime.datetime.now()# 构建文件名,精确到小时和分钟fileName = current_datetime.strftime("%Y-%m-%d-%H-%M.txt")# kw:贴吧关键字 max_pn:最大贴吧条数spider = TiebaSpider(kw=user_input, max_pn=150, fileName=fileName)spider.run()
控制台
请输入贴吧名称: 王者荣耀
****************************************************************************************************
{'title': '赛季上分答案①-上官婉儿教学', 'link': 'https://tieba.baidu.com/p/8509192314'}
{'title': 'Q钻耀 有无 铲铲也行 好无聊', 'link': 'https://tieba.baidu.com/p/8514457231'}
{'title': '好奇很久了,,你们说的一杯奶茶钱一般指多少。', 'link': 'https://tieba.baidu.com/p/8512445812'}
{'title': '有没有人处或者好朋友', 'link': 'https://tieba.baidu.com/p/8514390098'}
{'title': 'qy vy聊天打游戏', 'link': 'https://tieba.baidu.com/p/8512823062'}
{'title': '接p钻耀5r', 'link': 'https://tieba.baidu.com/p/8514461207'}
{'title': '已到工位 来点vy', 'link': 'https://tieba.baidu.com/p/8514458179'}
{'title': '恋爱dd 要巨粘人的 游戏厉害一点声音好听一点稍微涩一点。', 'link': 'https://tieba.baidu.com/p/8514452627'}
{'title': '收个闲鱼自己用', 'link': 'https://tieba.baidu.com/p/8514428795'}
{'title': 'qy 固聊 我很无聊', 'link': 'https://tieba.baidu.com/p/8514440871'}
{'title': '死学不会什么叫意识和操作,家人们谁懂吖。', 'link': 'https://tieba.baidu.com/p/8514341952'}
{'title': 'QQ区钻耀来个瑶。', 'link': 'https://tieba.baidu.com/p/8514459651'}
{'title': '玩走地鸡的长这样', 'link': 'https://tieba.baidu.com/p/8514390800'}
{'title': 'V小群+++', 'link': 'https://tieba.baidu.com/p/8514449634'}
{'title': '求求别口嗨了,v区钻耀开个打游戏的,评论的每一个来的', 'link': 'https://tieba.baidu.com/p/8514453252'}
{'title': '有没有人处对象', 'link': 'https://tieba.baidu.com/p/8514271361'}
{'title': '有没有一起玩的 q区星耀', 'link': 'https://tieba.baidu.com/p/8514459727'}
{'title': 'q钻石有无一起玩的', 'link': 'https://tieba.baidu.com/p/8514425372'}