南充市住房和城乡建设厅网站seo站外推广有哪些
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多
一、保存为二进制文件(.npy/.npz)
(1)numpy.save(file, arr, allow_pickle=True, fix_imports=True)
file:文件名/文件路径
arr:要存储的数组
allow_pickle:布尔值,允许使用Python pickles保存对象数组(可选参数,默认即可)
fix_imports:为了方便Pyhton2中读取Python3保存的数据(可选参数,默认即可)
保存格式是.npy
示例:
- #生成数据
- >>> x=np.arange(10)
- >>> x =array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- #数据保存
- >>> np.save('save_x',x)
- #读取保存的数据
- >>> np.load('save_x.npy')
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(2)numpy.savez(file, *args, **kwds)
file:文件名/文件路径
*args:要存储的数组,可以写多个,如果没有给数组指定Key,Numpy将默认从'arr_0','arr_1'的方式命名
kwds:(可选参数,默认即可)
这个同样是保存数组到一个二进制的文件中,但是厉害的是,它可以保存多个数组到同一个文件中,保存格式是.npz,它其实就是多个前面np.save的保存的npy,再通过打包(未压缩)的方式把这些文件归到一个文件上
#生成数据
>>> x=np.arange(10)
>>> x =array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> y=np.sin(x)
>>> y=array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) #数据保存
>>> np.save('save_xy',x,y)
#读取保存的数据
>>> npzfile=np.load('save_xy.npz')
>>> npzfile #是一个对象,无法读取
<numpy.lib.npyio.NpzFile object at 0x7f63ce4c8860> #按照组数默认的key进行访问
>>> npzfile['arr_0']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> npzfile['arr_1']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) 可以不适用Numpy默认给数组的Key,而是自己给数组有意义的Key,这样就可以不用去猜测自己加载数据是否是自己需要的.#数据保存
>>> np.savez('newsave_xy',x=x,y=y) #读取保存的数据
>>> npzfile=np.load('newsave_xy.npz') #按照保存时设定组数key进行访问
>>> npzfile['x']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> npzfile['y']
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849]) 二、保存到文本文件
xuexi:Numpy中数据的常用的保存与读取方法 - 好奇不止,探索不息 - 博客园 (cnblogs.com)
保存数组到文本文件上,可以直接打开查看文件里面的内容.
(1)numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
fname:文件名/文件路径,如果文件后缀是.gz,文件将被自动保存为.gzip格式,np.loadtxt可以识别该格式
X:要存储的1D或2D数组
fmt:控制数据存储的格式
delimiter:数据列之间的分隔符
newline:数据行之间的分隔符
header:文件头步写入的字符串
footer:文件底部写入的字符串
comments:文件头部或者尾部字符串的开头字符,默认是'#'
encoding:使用默认参数
fmt参数:控制数据格式
如:
x = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
np.savetxt(r'test.txt', x)
参数都使用默认值,存数结果如下所示:
文件中的数据小数点后保留太多位,使得数据看起来很凌乱,可以使用格式控制参数‘fmt’进行控制,比如小数点后保留3位:
fmt='%.3e'
以浮点数存储,fmt=’%.3f’
也可以整数格式存储,fmt=’%d’

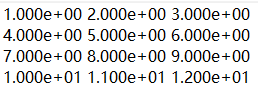
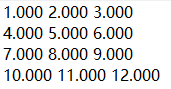
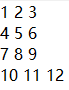
格式控制–数据对齐问题
可以看到上图中第4行的11和12与上一行的8和9发生错位,不够美观,通过设置数据长度进行调整。
np.savetxt(r'test.txt', x, fmt='%5d')
示例:
np.savetxt(r'test.txt', x, fmt='%5d', delimiter='|')
np.savetxt(r'test.txt', x, fmt='%05d', delimiter='|')



delimiter参数:每列数据之间的分割符号,默认为空格
newline参数:每行数据之间的分割符,默认换行
np.savetxt(r'test.txt', x, fmt='%d', newline='-|-')

fmt 其他写法:
学习:python - 在 numpy.savetxt 中设置 fmt 选项 - IT工具网 (coder.work)
- 当
fmt是单个格式化字符串时,它适用于 数组(一维或二维输入数组) - 当
fmt是一个格式化字符串序列时,它适用于二维输入数组的每一列 -
(1)添加字符以右对齐。
带空格:
np.savetxt('tmp.txt', a, fmt='% 4d')11 12 13 1421 22 23 2431 32 33 34带零:
np.savetxt('tmp.txt', a, fmt='%04d')0011 0012 0013 0014 0021 0022 0023 0024 0031 0032 0033 0034(3)向左对齐添加字符(使用“
-”)。带空格:
np.savetxt('tmp.txt', a, fmt='%-4d')11 12 13 14 21 22 23 24 31 32 33 34
当fmt为格式化字符串序列时,二维输入数组的每一行都按照fmt进行处理:
fmt 作为单个格式化字符串中的序列
fmt = '%1.1f + %1.1f / (%1.1f * %1.1f)'
np.savetxt('tmp.txt', a, fmt=fmt)11.0 + 12.0 / (13.0 * 14.0)
21.0 + 22.0 / (23.0 * 24.0)
31.0 + 32.0 / (33.0 * 34.0)
fmt 作为格式化字符串的迭代器:【fmt设置多个参数】
fmt = '%d', '%1.1f', '%1.9f', '%1.9f'
np.savetxt('tmp.txt', a, fmt=fmt)11 12.0 13.000000000 14.000000000
21 22.0 23.000000000 24.000000000
31 32.0 33.000000000 34.000000000(2)numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes')
fname:文件名/文件路径,如果文件后缀是.gz或.bz2,文件将被解压,然后再载入
dtype:要读取的数据类型
comments:文件头部或者尾部字符串的开头字符,用于识别头部,尾部字符串
delimiter:划分读取上来值的字符串
converters:数据行之间的分隔符
参考学习:
Numpy中数据的常用的保存与读取方法 - 好奇不止,探索不息 - 博客园 (cnblogs.com)
遇到相关问题再补充哦!