怎样用vs做简单网站市场营销咨询
正则表达式(Regular Expression,简称 Regex)是一种强大的文本处理工具,广泛用于字符串的搜索、替换、分析等操作。它基于一种表达式语言,使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式不仅在各种编程和脚本语言中被广泛支持,还是很多文本编辑器和处理工具的重要功能。
当需要从一堆字符串中提取出(或者是替换掉)具有一定规则(规律)的子字符串,那么用正则表达式会非常简单。
语法介绍
特殊字符
特殊字符在正则表达式中的作用是非常重要的,可以定义一系列的匹配规则。
.
- 描述
匹配除换行符(\n)外的任意单个字符。
如果要匹配.字符,请用\.。
注意:
[.]内的.匹配的是.而不是任意单个字符(.)内的.匹配的是任意单个字符,而不是.
- 示例
a.c匹配的是abc、acc等,但无法匹配ac[a.c]匹配的是a、.、c,但无法匹配abc
*
- 描述
匹配前面子表达式任意多次(包含0次)。
如果要匹配*字符,请用\*。
注意:
- 子表达式的意思是可以单独拎出来作为正则表达式的字符串
- 在匹配时必须保证
*的前面有子表达式[*]内的*匹配的是*字符
- 示例
ab*c匹配的是ac、abc、abbbbc等。(这里的子表达式是b)[abc]*匹配的是a、b、c、ac、acb、abcc等。(这里的子表达式是[abc])(abc)*匹配的是abc、abcabc、abcabcabc等。(这里的子表达式是(abc))[a*c]匹配的是a、*、c。(这里不做量化字符)
^
- 描述
^字符的匹配规则有两种:
- 在方括号
[]内时,匹配不包含在方括号内的单个字符 - 不在方括号内时,匹配字符串中的起始位置(起始位置也可以匹配)
- 示例
^abc的匹配项有起始位置abc
比如输入字符串
abc is abcd中匹配的是最前面的abc,最后面的无法匹配。
[^abc]匹配的是除了a、b、c这三个字符外的所有其他单个字符
[ ]
- 描述
匹配方括号内包含的单个字符。
注意:
- 方括号内的
-字符如果是第一个或最后一个的字符,那么它就是匹配-字符- 方括号内的
-字符不是第一个也不是最后一个字符,那么它就是匹配一个范围- 如果方括号内的第一个字符是
]会把最前面的[]当做子表达式
- 示例
[abc]的匹配项有a、b、c。[a-z]的匹配项是a-z的范围,即匹配的是a-z的所有小写字母。[abcx-z]的匹配项有a、b、c以及x-z的范围。[-abc]的匹配项有-、a、b、c。[abc-]的匹配项有a、b、c、-。[]abc]的匹配项有[]空字符集、a、b、c、]。[]abc[]的匹配项有[]空字符集、a、b、c、[]空字符集。
$
- 描述
$字符的匹配规则有两种:
- 在方括号
[]内时,就是匹配$字符 - 不在方括号内时,匹配字符串的结束位置
- 示例
abc$的匹配项有abc结束位置
比如输入字符串
abcd is abc中匹配的是最后的abc(结束位置不可见)
[abc$]的匹配项有a、b、c、$
( )
- 描述
圆括号的主要作用是定义一个子表达式,并设置捕获组。
捕获组(分组捕获)的主要作用是匹配组内的子表达式,并将匹配上的内容记录下来。
这导致使用捕获组的正则表达式的效率降低。
如果要匹配(或)字符,请使用\(或\)。
后面章节详细介绍。
+
- 描述
匹配前面子表达式一次或零次。
如果要匹配+字符,请用\+。
注意:
- 子表达式的意思是可以单独拎出来作为正则表达式的字符串
- 在匹配时必须保证
+的前面有子表达式[+]内的+匹配的是+字符
- 示例
ab+c匹配的是abc、abbc、abbbc等,但不匹配ac。(这里的子表达式是b)[abc]+匹配的是a、b、c、ac、acb等,但不匹配[abc])(abc)+匹配的是abc、abcabc、abcabcabc等,但不匹配(abc))[a+c]匹配的是a、+、c。(这里不做量化字符)
?
- 描述
匹配前面子表达式0次或1次。
如果要匹配?字符,请用\?。
- 示例
ab?c匹配的是ac或abc。(这里的子表达式是b)[ab?c]匹配的是a、b、?、c。(这里不做量化字符)
\
- 描述
反斜杠主要起转义字符的作用,这里的转义是双向的(原义转特殊,特殊转原义)。
- 原义转特殊:
\t表示制表符(Tab)\r表示回车符\n表示换行符\f表示换页符,用于打印文档中的换页\s表示任何空白字符,比如空格、制表符、回车符、换行符、换页符等\S表示非空白字符- 特殊转原义:
所有量词(*、+、?、{})的前面加\后,转义称为普通字符。
|
- 描述
匹配|前面的子表达式或者|后面的子表达式(二选一,只要匹配上一个就算成功)。
- 示例
ab|c的匹配项是ab 或 c,能匹配上ab和c[ab]|c能匹配上a、b、c
{ }
- 描述
{ }也是一个量词,表示匹配前面的子表达式的次数(或次数范围)。{ }有三种规范:
{n}:表示匹配前面子表达式n次,n是一个非负整数(大于等于0的整数){n,}:表示至少匹配前面子表达式n次,它是一个范围(大于等于n的整数),这里的n是一个非负整数{n,m}:表示至少匹配前面子表达式n次,最多匹配m次,且n<=m,这里的n和m都是非负整数
- 示例
abc{0}的匹配项是ab,这里的子表达式是cabc{2}的匹配项是abcc,这里的子表达式是cabc{2,}的匹配项是abcc、abccc、abcccc等abc{2,4}的匹配项是abcc、abccc以及abcccc(abc){2}的匹配项是abcabc[abc]{2}的匹配项是aa、ab、ac、ba、bb、bc、ca、cb以及cc
量化字符(量词)
量化字符是用来指定子表达式连续出现多少次才能匹配上。包含*、+、?、{},具体细节看上面特殊字符章节。
定位字符
定位字符是匹配字符串中特殊的位置,比如字符串的首和尾。
定位字符包含:
^
上面已经介绍了,这里就不介绍了。
$
上面已经介绍了,这里就不介绍了。
\b
匹配一个单词的边界,就是字符和空格之间的位置。比如:a cat in cats字符串中,\bcat\b只能匹配到前面的cat,但后面的cats中的cat无法匹配。
\B
匹配非单词边界,比如:a cat in cats字符串中,\bcat\B只能匹配到后面的cats中的cat,但前面的cat无法匹配。
扩展语法
速记字符
\d
匹配单个数字字符。
\w
匹配单个“单词字符”(字母数字字符加下划线)。
用\w+可以匹配用户名。
\s
匹配空白字符,比如空格、制表符、回车符、换行符、换页符等。
反向引用
反向引用指的是通过\n(这里的n表示数字,一般支持1-9,有些标准也支持9以上)来引用对应捕获组所匹配到的内容。
比如t1_t2_t3_t3_t2_t1字符串是能够被(..)_(..)_(..)_\3_\2_\1这样的正则完全匹配的,它的引用流程如下图: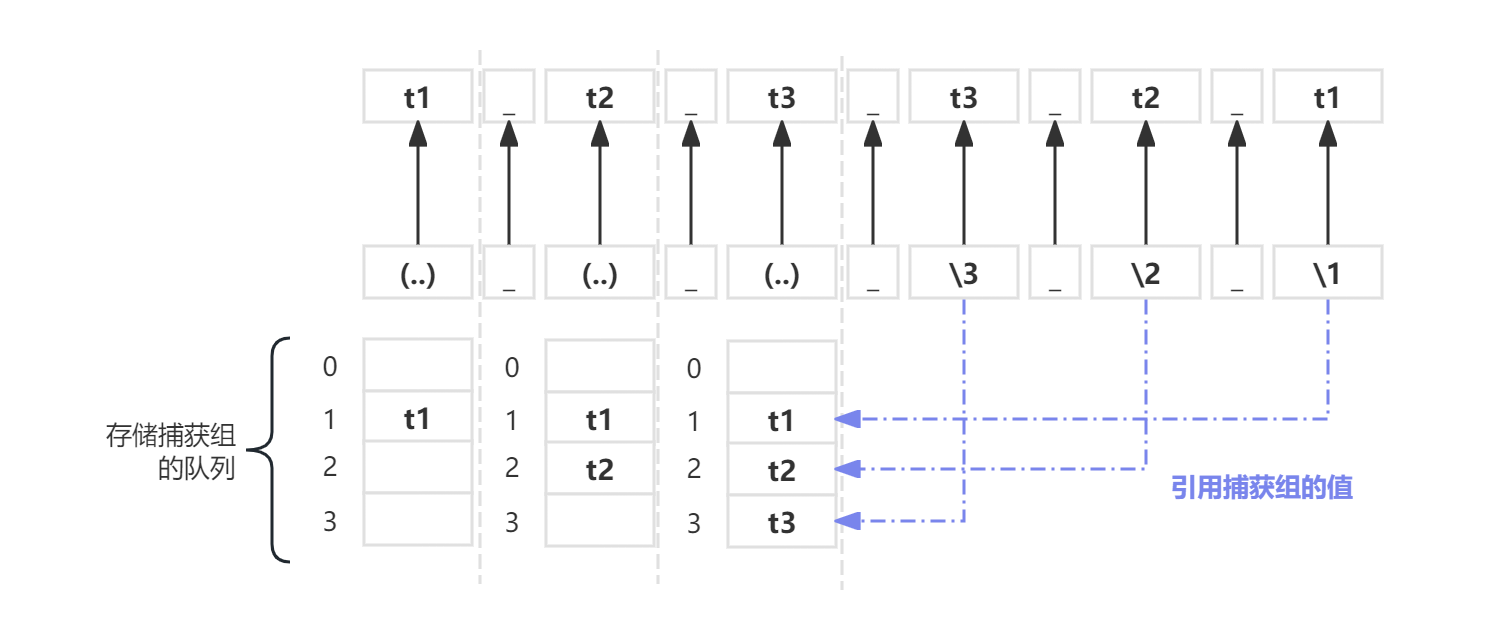
不同的语言底层实现的原理不一样。
存储捕获组的队列中下标0一般用来存储匹配成功的完整的字符串,示例中下标0位置存储的字符串应该是:
t1_t2_t3_t3_t2_t1
非捕获组
通过()实现的捕获组会影响性能,如果既要使用() 来进行分组,又不想作为捕获组被保存,所以需要使用非捕获组。
通过(?:..)可以实现非捕获组,示例如下:
还是用上面的示例:t1_t2_t3_t3_t2_t1字符串能够被(?:..)_(..)_(..)_\2_\1_t1完全匹配,其中(?:..)作为非捕获组匹配输入字符串的t1,不会被存储下来;然后后面在引用捕获组时,因为前面只有两个捕获组,所以引用计数最大是2。
C++中的正则表达式
C++11正式引入了正则表达式。
C++相关类和接口介绍
std::regex
std::regex是用于表示正则表达式的类,管理正则表达式。
std::regex_match
std::regex_match是一个函数,用于检查整个字符串是否完全符合正则表达式的模式。
需要整个字符串完全符合正则表达式,否则匹配失败。
std::regex_search
std::regex_search是一个函数,用于在字符串中搜索与正则表达式匹配的部分。
std::regex_iterator
std::regex_iterator迭代器用于迭代所有符合正则表达式的匹配项。
std::regex_iterator是一个模板类,根据字符类型的区别衍生出以下:
cregex_iterator、wcregex_iterator、sregex_iterator、wsregex_iterator
示例:
// 对于 std::string
std::string s = "Example string";
std::regex re("E");
std::sregex_iterator it(s.begin(), s.end(), re), end;
for (; it != end; ++it) {std::cout << it->str() << std::endl;
}// 对于 std::wstring
std::wstring ws = L"Example wstring";
std::wregex wre(L"E");
std::wsregex_iterator wit(ws.begin(), ws.end(), wre), endw;
for (; wit != endw; ++wit) {std::wcout << wit->str() << std::endl;
}
std::regex_replace
std::regex_replace是一个函数,用于替换与正则表达式匹配的子串。
std::regex_token_iterator
std::regex_token_iterator迭代器用于分割字符串,基于正则表达式找到的匹配项或非匹配项。
std::regex_error
std::regex_error是一个异常处理类,用于报告正则表达式中的错误。
try {// 使用正则表达式
} catch (const std::regex_error& e) {// 处理正则表达式错误
}
实际应用场景代码
匹配文本
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example.";std::regex pattern("regular expression");if (std::regex_search(text, pattern)) {std::cout << "The pattern was found in the text." << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
查找文本位置
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example. ""Another example of regular expression.";std::regex pattern("example");std::smatch match;std::regex_search(text, match, pattern);if (match.size() > 0) {std::cout << "The first match was found at position " << match.position() << std::endl;std::cout << "The matched text is: " << match[0] << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
替换文本
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example. ""It contains some outdated terms.";std::regex pattern("outdated");std::string replaced_text = std::regex_replace(text, pattern, "modern");std::cout << "The replaced text is: " << replaced_text << std::endl;return 0;
}
分组匹配
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example (123) 456-7890";std::regex pattern("(([^ ]+) (\\d{3})-(\\d{4}))$");std::smatch match;std::regex_search(text, match, pattern);if (match.size() > 0) {std::cout << "The first match was found at position " << match.position() << std::endl;std::cout << "Group 1: " << match[1] << std::endl;std::cout << "Group 2: " << match[2] << std::endl;std::cout << "Group 3: " << match[3] << std::endl;std::cout << "Group 4: " << match[4] << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
#include <regex>
#include <iostream>int main() {std::string text = "(123) 456-7890";std::regex pattern("(([^ ]+) (\\d{3})-(\\d{4}))$");std::smatch match;if (std::regex_match(s, match, r)) {std::cout << "Group 1: " << match[1] << std::endl;std::cout << "Group 2: " << match[2] << std::endl;std::cout << "Group 3: " << match[3] << std::endl;std::cout << "Group 4: " << match[4] << std::endl;}return 0;
}
资料
推荐两个学习使用正则表达式的网站:
- https://regexper.com/
可以直观地理解正则表达式的逻辑:
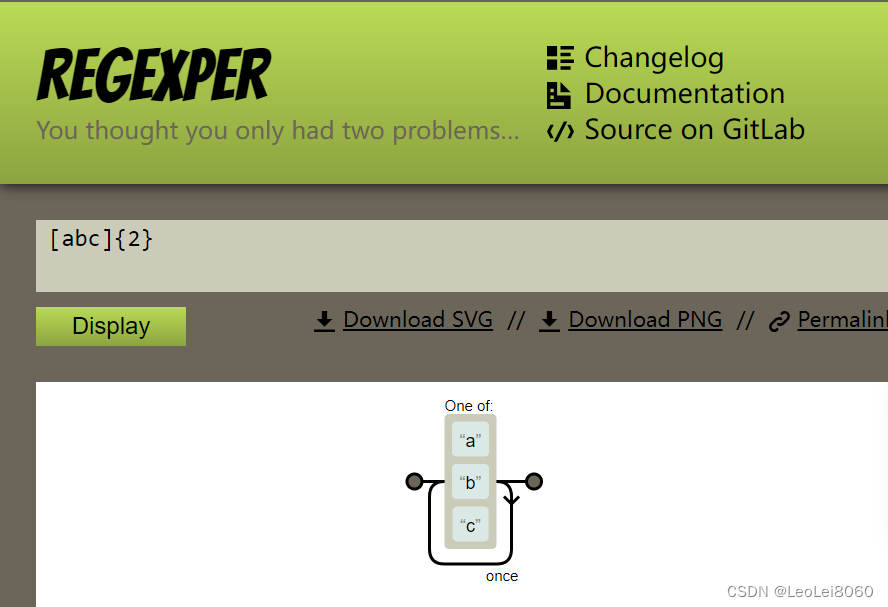
- https://regexr.com
通过该网站可以测试正则表达式的效果,并直观地看到匹配项: