惠州网站建设web91seo流量是什么
文章目录
- 关联式容器
- 树形结构的关联式容器
- set
- insert增减
- erase删除
- multiset
- 修改
- map
- pair<key,value>
- insert
- operator[] 的引入
- insert和operator[]的区别
- multimap
- 小结
- map的使用
- 统计最喜欢吃的前几种水果
- 前K个高频单词,返回单词的频率由高到低,频率相同时,字典序排列
关联式容器
-
序列式容器: vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身,元素之间无关系,可以随意的插入.
-
关联式容器:map/set… 存储加查找数据,数据之间不能随便插入和删除,有强烈的关联关系.关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
-
键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义.
-
树形结构的关联式容器
set
底层是之前实现过的搜索树的K模型
insert增减
搜索树走得是中序遍历,BS搜索树是底层,自身带有排序+去重的功能。
如果有相同的值就不会进行再次插入的了。
所以有去重的需要可以用set,默认是升序.
erase删除
删除某一个元素,要先进行查找,就是find()
- 删除一个位置和删除一个值的区别:
位置要确保位置的有效,而删除值有就删除没有就没有反馈。
- erase的返回值是已经删除的指定元素的个数
void test_set()
{set<int> st;st.insert(3);st.insert(5);st.insert(4);st.insert(2);st.insert(8);st.insert(9);st.insert(9);//迭代器set<int>::iterator it = st.begin();while (it != st.end()){cout << *it << " ";it++;}cout << endl;//2 3 4 5 8 9set<int>::iterator pos = st.find(3);if (pos != st.end()){st.erase(pos);}//有序说明搜索树走得是中序-排序//去重效果:相同数据插入失败
//范围forfor (auto e : st){cout << e << " ";}cout << endl;
}
multiset
如果只想排序,不想要去重就用:multiset (多样的)
当删除的值有多个的时候,删除的值是哪一个位置的呢?
- find查找到的是中序的第一个,也就是最左节点.
void test_multi_set()
{multiset<int>st;st.insert(3);st.insert(5);st.insert(4);st.insert(2);st.insert(8);st.insert(9);st.insert(9);st.insert(9);st.insert(9);st.insert(9);st.insert(1);multiset<int>::iterator it = st.begin();while (it != st.end()){cout << *it << " ";it++;}cout << endl;auto pos = st.find(9);while (pos != st.end()){cout << *pos << " ";++pos;}//如何将所有重复元素删除//auto pos1 = st.find(9);//while (pos1 != st.end() && *pos1 == 9)//{// st.erase(pos1);// //节点指针被干掉之后是野指针无法++,所以会崩溃// ++pos1;//}cout << st.erase(9) << endl;//把所有9都删了,还返回了删了几个for (auto e : st){cout << e << " ";}cout << endl;
}
修改
运用迭代器进行修改的时候是不允许的,因为改动某一个节点的值之后就可能不是搜索树,因为节点之间存在大小关系.

map
底层是搜索树对应的key-val模型

pair<key,value>

-
pair<>提供构造函数

-
pair<>匿名对象
-
make_pair()函数模板,对匿名对象的一层封装.虽然看起来多一层函数调用,其实可以设置为内联函数直接打开.

pair是一个结构体,两个值都是公有的.
pair并没有重载流插入和流提取运算符,遍历的时候可以通过first和second进行访问.
void test_map()
{map<string,string>m;//pair的构造函数pair<string, string> kv1("sort", "排序");m.insert(kv1);//pair的匿名对象m.insert(pair<string,string>("string","字符串"));//make_pair自动推导类型,简洁m.insert(make_pair("test","测试"));map<string, string>::iterator it = m.begin();while (it != m.end()){//cout << *it << endl;//pair不支持流插入和流提取cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;//最好加上&,因为每一次pair中的string都得拷贝给efor (auto& e : m){cout << e.first << ":" << e.second << endl;}cout << endl;
}
map的key不支持修改,但是val是支持修改的.因为搜索树的关系是靠key来维护的.
insert
插入的时候涉及到去重需要先进行查找,由于是搜索树插入的时候为了更合适的位置又进行了一遍查找
为了进行优化,引进了pair(iterator,bool) insert();实现用iterator和bool两个标志来完成对于上面的优化。

void test_map2()
{//了解insert返回值之前string arr[] = {"苹果","苹果", "苹果", "苹果", "苹果", "香蕉","西红柿"};map<string, int> countMap;for (auto& str : arr){auto ret = countMap.find(str);if (ret == countMap.end())countMap.insert(make_pair(str, 1));elseret->second++;}//了解insert返回值之后for (auto& str:arr){auto kv = countMap.insert(make_pair(str,1));if (kv.second == false){kv.first->second++;//返回值的第一个是相同节点的指针}}//[]的引入for (auto& str : arr){countMap[str]++;}for (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;
}
operator[] 的引入

迭代器要么指向新插入的节点要么指向相同值的节点.
//map中[]的文档注释
mapped_type& operator[](const key_type& k)
{return *(this->insert(make_pair(k,mapped_type())).first).second;
}
//帮助理解版本
mapped_type&operator[](const key_type& k)
{pair<iterator,bool> ret=insert(make_pair(k,mapped_type()));return ret->first.second;
}

水果第一次出现,插入+修改,insert时考虑的只有key.
水果不是第一次出现,查找+修改,因为&的存在,作用在相同值节点的second上.
insert和operator[]的区别
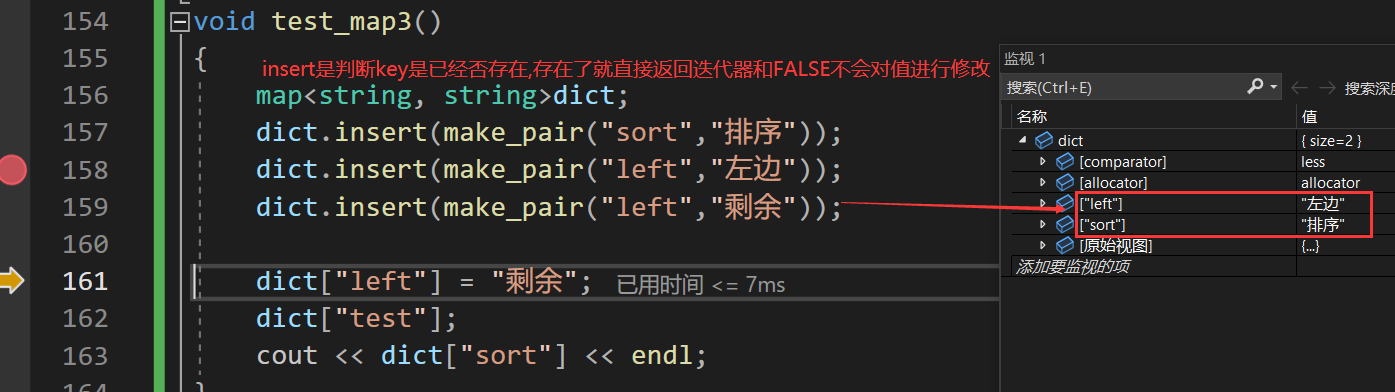

multimap
-
允许key冗余,multimap 类型。无论是否相同都会进行插入.
-
不支持[]的出现根据底层理解,应该返回哪个节点的value值呢?
-
cout<<dict.count(“left”);返回key出现的次数.
小结
前面对map/multimap/set/multiset进行了简单的介绍,在介绍中发现,这几个容器有个共同点是:其底层都是按照二叉搜索树来实现的,但是二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索树就会退化成单支树,时间复杂度会退化成O(N),因此map、set等关联式容器的底层结构是对二叉树进行了平衡处理,即采用平衡树来实现。
map的使用
统计最喜欢吃的前几种水果
# include<algrithm>struct CountVal
{bool operator()(const pair<string ,int>&l,const pair<string,int>&r){//return l.second >r.second;return l.second < r.second;//堆,优先级队列中使用的}
}
struct CountIterator
{bool operator()(const map<string,int>::iterator& l,const map<string,int>::iterator&r){//return l->second>r->second;return l->second< r->second;//优先级队列中使用的,想要建立的是一个大堆}
}
void GetfavoriteFruit(const vector<string>&fruits,size_t k)
{map<string,int>countmap;for(auto &e:countmap){countmap[e]++;}//数据量不大的排序//sort,为了便于进行以次数为依据的排序,需要先将数制拷贝到数组中进行排序。//1. 第一种写法:有很多次对于pair类型的深拷贝放到vector中,如果string很长就是浪费空间vector<pair<string,int>> sortV;for(auto &kv: countmap){sortV.push_back(kv);}sort(sortV.begin(),sortV.end(),CountVal());for(int i=0;i<k;i++){cout<<sortV[i].first<<":"sortV.second<<endl;}cout<<endl;//2. 第二种写法,vector的迭代器支持排序,而map的不支持
//那么就将pair的迭代器拷贝进vector中vector<map<string,int>::iterator> sortV;auto it = countmap.begin();while(it!=countmap.end()){sortV.push_back(it);++it;}sort(sortV.begin(),sortV.end(),CountIterator());for(int i=0;i<k;i++){cout<<sortV[i]->first<<":"<<sortV[i]->second<<endl;//容器当中都是迭代器}cout<<endl;
//3. 使用multimap<>操作
//仿函数默认是升序less,将他设置为greater就改成了降序
//头文件
#include<functional>multimap<int ,string,greater<int>> sortmap;for(auto &kv:countmap){sortmap.insert(make_pair(kv.second,kv.first));//根据value排序}
//4.1 用优先级队列,用的是堆
//#include<queue>priority_queue<pair<string,int>,vector<pair<string,int>>,CountVal> pq;//pq这里类模板传类型CountVal,前两种仿函数是函数模板传对象CountVal()for(auto&kv;countmap){pq.push(kv);}while(k--){cout<<pq.top().first<<" :"<<pq.top().second<<endl;pq.pop();}cout<<endl;//4.2 没有必要将数据也拷贝出来,拷贝迭代器出来就可以找到相应的数据priority_queue<map<string,int>::iterator,vector<map<string,int>::iterator>,CountIterator> pq;auto it=countmap.begin();while(it!=countmap.end()){pq.push(it);++it;}while(k--){cout<<pq.top()->first<<" :"<<pq.top()->second<<endl;pq.pop();}cout<<endl;
}
//pair 是支持比较大小的。- 注意参数(类型,承装类型的容器,仿函数)
- 优先级队列,小于建的是大堆

前K个高频单词,返回单词的频率由高到低,频率相同时,字典序排列
sort的底层是快排,是不稳定的排序。只有稳定的排序才能保证字典序i在L的前面.稳定的排序:stable_sort()
//使用map的特性
vector<string>topKFrequency(vector<int>&words,int k)
{map<string,int> countmap;for(auto& kv : words){countmap[kv]++;}multimap<int ,string,greater<int>> sortMap;for(auto & kv: countmap){sortMap.insert(make_pair(kv.second,kv.first));}vector<string>v;auto it=sortMap.begin();while(k--){v.push_back(it->second);++it;}return v;
}