淄博网站文章优化百度云搜索引擎官网入口
有一个查询接口,主业务表有几万多条数据,没超过十万,由于没有使用分页,所以每次查询都要返回大几万的数据,然后问题是前端页面查询数据显示数据要转很久。
压缩响应体大小
我发现查询的时间是1秒多,但是浏览器调式看到接口花的时间是3秒多。
发现是响应体太大了,响应体有21.97MB,下载花了两秒多。

查询资料得知,http请求需要下载响应体,如果响应体太大会导致Content Download时间过长,下载HTTP响应的时间(包含头部和响应体)。
优化措施:
1、通过条件Get请求,对比If-Modified-Since和Last-Modified时间,确定是否使用缓存中的组件,服务器会返回“304 Not Modified”状态码,减小响应的大小;
2、移除重复脚本,精简和压缩代码,如借助自动化构建工具grunt、gulp等;
3、压缩响应内容,服务器端启用gzip压缩,可以减少下载时间;
响应体太大,服务器开启响应压缩:
server:compression:# 开启压缩enabled: true# 压缩的响应内容mime-types:- application/json- application/xml- application/javascript- text/html- text/xml- text/plain- text/css- text/javascript# 响应体大小达到2048kb才压缩min-response-size: 2048开启后确实下载内容花的时间变短了很多:

响应下载的时间的打下来了,但是等待服务器响应的时间还是有点长,就是接口的问题了。先去看程序有没有问题,执行了一下发现窗口一直再打印查询条目,因为查询的条数很多,他会将每条查询出来的条目row打印出来,于是把mybatis的日志配置先注释了,结果真的快了很多。但还是不够快。程序上检查了一圈,感觉没的优化了,就去看查询的sql语句。
#MyBatis相关配置
mybatis:mapperLocations: classpath*:/mapper/*.xmltypeAliasesPackage: com.huishi.entityconfiguration:map-underscore-to-camel-case: false
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl改用:
logging:level:com.lin.mapper: debugSQL语句
这是这个接口的主要查询sql:
SELECTEC1.CLASS_CODE CLASSCODE1,EC2.CLASS_CODE CLASSCODE2,EC3.CLASS_CODE CLASSCODE3,EI.ID, EI. EQUIPMENT_CODE, EI. ISSUE_SERIES_CODE, EI. OLD_SELF_CODE, EI. EQUIP_NAME, EI. EQUIP_TYPE, EI. USE_DEPART, EI. SCOUT_SYSTEM, EI.CLASS_CODE, EI. "USAGE", EI. MISSION, EI. EQUIP_POS, EI. MANAGER, EI. FIX_DEPART, EI. EQUIP_NUM, EI. EQUIP_UNIT_PRICE, EI.EQUIP_SUM_PRICE, EI. EQUIP_STATUS, EI. USE_STATUS, EI. QUALITY_LEVEL, EI. GIVEN_DATE, EI. START_USE_DATE, EI. PRODUCE_DATE, EI. PRODUCE_FACTORY, EI.BATCH_CODE, EI. USE_DEPART_CODE, EI. SEQUENCE_CODE, EI. COMM_INFO, EI. EQUIP_CONF, EI. COUNT_FLAG, EI. MARK_FLAG, EI. EQUIP_SOURCE, EI. IP_ADDRESS, EI. UPDATE_TIME, EI. CABI_CODE, EI.IS_GENERAL, EI. IMAGE_PATH1, EI. IMAGE_PATH2, EI. FUNDS_SOURCE, EI. FORCE_SYSTEM, EI. SERVICE_LIFE, EI. UNIT_CODE, EI. DOC_IDFROM EQUIPMENT_INFO EILEFT JOIN DICT_EQUIPMENT_CLASS1 EC1 ON EC1.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, 1, INSTR(EI.CLASS_CODE, '/', 1, 1) - 1))LEFT JOIN DICT_EQUIPMENT_CLASS2 EC2 ON EC2.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, INSTR(EI.CLASS_CODE, '/', 1, 1) + 1, INSTR(EI.CLASS_CODE, '/', 1, 2) - INSTR(EI.CLASS_CODE, '/', 1, 1) - 1))LEFT JOIN DICT_EQUIPMENT_CLASS3 EC3 ON EC3.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, INSTR(EI.CLASS_CODE, '/', 1, 2) + 1))where EI.DEL_FLAG = '0' and EI.USE_STATUS != '已报废'索引方案
CREATE INDEX 索引名 ON 表名(列名);除了单列索引,还可以创建包含多个列的复合索引。
CREATE INDEX 索引名 ON 表名(列名1, 列名2, 列名3, ...);删除索引也非常简单。
DROP INDEX 索引名;查看某个表中的所有索引也同样简单。
SELECT * FROM ALL_INDEXES WHERE TABLE_NAME = '表名'还可以查看某个表中建立了索引的所有列。
SELECT * FROM ALL_IND_COLUMNS WHERE TABLE_NAME = '表名'常见的就是给自动添加索引了。
给经常在where后面的字段加了索引,查看sql的执行计划:
EXPLAIN PLAN FOR my_querySql;SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);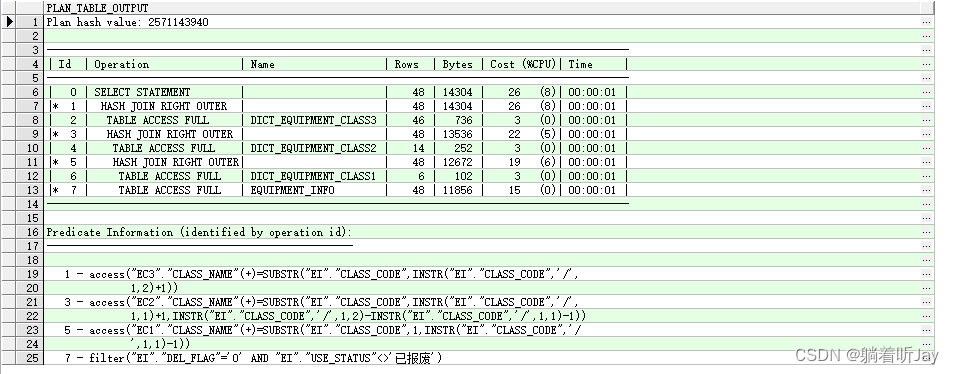
Plan hash value: 查询执行计划的哈希值,用于唯一标识这个执行计划。
Id: 操作的标识符,表示执行计划中每个操作的顺序。
Operation: 执行计划中的操作类型。这里包含了一些操作,如SELECT STATEMENT(选择语句)、HASH JOIN(哈希连接)和TABLE ACCESS FULL(全表扫描)等。
Name: 操作所涉及的表或索引的名称。
Rows: 操作返回的行数估计。
Bytes: 操作返回的数据字节数估计。
Cost (%CPU): 操作的成本估计和 CPU 使用百分比。这是一个估算值,表示执行这个操作的开销。
Time: 操作预计的执行时间。
Id 0-7是执行的序号,缩进最多的最先执行,缩进一样,上面的先执行。
cost越大的说明花费时间越久。
table access full说明还是全表扫描
但是查看sql的执行计划,发现还是全表扫描,那就是索引失效了。
`where EI.DEL_FLAG = '0' and EI.USE_STATUS != '已报废'` != 会导致USE_STATUS索引失效,于是我改成:where EI.DEL_FLAG = '0' and EI.USE_STATUS = '新品' or EI.USE_STATUS = '发料中' or EI.USE_STATUS = '送修中' or EI.USE_STATUS = '调拨中'or EI.USE_STATUS = '发料中' or EI.USE_STATUS = '库存中' or EI.USE_STATUS = '借料中' or EI.USE_STATUS = '故障' or EI.USE_STATUS = '在用'但是好像还是没走索引,查了一下,发现如果查询的数据量超过表数据的30%,索引就会失效,因为全表扫还更快 。这样看加索引这个方案好像不适合当前的业务需求,因为这个接口查询的数据量大,索引根本就没用啊!!!
分区表
查询到分区表也能加快查询速度。
如果 EQUIPMENT_INFO 表非常大,考虑将其分成多个分区表。分区可以减轻查询时需要扫描的数据量。
分区策略:包括按日期范围、按某个特定列的值范围、按地理区域等划分数据。
按使用状态分区:
创建分区表:
CREATE TABLE "EQUIPMENT_INFO_co"( "ID" NUMBER(20,0) NOT NULL ENABLE, ...."USE_STATUS" VARCHAR2(20) DEFAULT '在用', .....)
PARTITION BY LIST ("USE_STATUS")
(PARTITION new_items VALUES ('新品'),PARTITION pending_scrapped VALUES ('待报废'),PARTITION in_repair VALUES ('送修中'),PARTITION in_transfer VALUES ('调拨中'),PARTITION in_issue VALUES ('发料中'),PARTITION in_stock VALUES ('库存中'),PARTITION on_loan VALUES ('借料中'),PARTITION faulty VALUES ('故障'),PARTITION in_use VALUES ('在用'),PARTITION scrapped VALUES ('已报废')
);--查看分区数据,查看use_status是新品的
SELECT * FROM EQUIPMENT_INFO_co PARTITION (new_items);--修改分区表
ALTER TABLE EQUIPMENT_INFO
MODIFY PARTITION BY LIST (USE_STATUS)
(PARTITION new_items VALUES ('新品'),PARTITION pending_scrapped VALUES ('待报废'),PARTITION in_repair VALUES ('送修中'),PARTITION in_transfer VALUES ('调拨中'),PARTITION in_issue VALUES ('发料中'),PARTITION in_stock VALUES ('库存中'),PARTITION on_loan VALUES ('借料中'),PARTITION faulty VALUES ('故障'),PARTITION in_use VALUES ('在用'),PARTITION scrapped VALUES ('已报废')
);--修改分区表,并指定表空间
ALTER TABLE EQUIPMENT_INFO
MODIFY PARTITION BY LIST (USE_STATUS)
(PARTITION new_items VALUES ('新品') TABLESPACE PARTITION1,PARTITION pending_scrapped VALUES ('待报废') TABLESPACE PARTITION1,PARTITION in_repair VALUES ('送修中') TABLESPACE PARTITION1,PARTITION in_transfer VALUES ('调拨中') TABLESPACE PARTITION1,PARTITION in_issue VALUES ('发料中') TABLESPACE PARTITION1,PARTITION in_stock VALUES ('库存中') TABLESPACE PARTITION1,PARTITION on_loan VALUES ('借料中') TABLESPACE PARTITION1,PARTITION faulty VALUES ('故障') TABLESPACE PARTITION1,PARTITION in_use VALUES ('在用') TABLESPACE PARTITION1,PARTITION scrapped VALUES ('已报废') TABLESPACE PARTITION1
);这个分区表搞半天感觉没啥用,
缓存数据
有一些常用的数据可以在项目启动的时候放到redis中,来提高数据查询的响应速度。
因为这个查询接口的数据是读多写少的场景,所以我打算把这个查询的数据在项目启动的时候就放到缓存中,然后在监测这张表,当数据发生变更的时候,更新缓存中的数据。
/*** 项目启动时,会执行PostConstruct注释的方法。将查询的数据缓存到redis中。*/@PostConstructpublic void init(){System.out.println("初始化数据==============");redisCache.setCacheMap(Constants.EQUIPMENT_TYPE_NUM_CACHE_KEY,equipTypeMapNum);}将查询的数据放到缓存后,这个查询的数据直接到redis中取就好,这样查询的速度的确快了挺多。
然后数据库写个触发器,当那张表的数据发生变更使用UTL_HTTP向程序发送http请求接口,接口就会更新redis中的数据。
创建用于发送http请求的存储过程:
CREATE OR REPLACE PROCEDURE send_http_get_request (p_url IN VARCHAR2
) ASreq utl_http.req;res utl_http.resp;
BEGIN-- 打开HTTP请求req := utl_http.begin_request(p_url, 'GET', 'HTTP/1.1');-- 设置请求头utl_http.set_header(req, 'Content-Type', 'application/json');-- 执行HTTP请求res := utl_http.get_response(req);-- 处理HTTP响应,例如提取响应内容-- res.status_code, res.reason_phrase, utl_http.get_response_text(res)-- 关闭HTTP请求utl_http.end_response(res);
EXCEPTIONWHEN OTHERS THEN-- 处理异常NULL;
END;-- 创建触发器,当EQUIPMENT_INFO表发生insert update delete变更时触发
CREATE OR REPLACE TRIGGER equipment_info_change_trigger2
AFTER INSERT OR UPDATE OR DELETE ON EQUIPMENT_INFO
FOR EACH ROW
BEGIN--发送http请求通知程序表变更-- 调用发送HTTP请求的存储过程send_http_get_request('http://127.0.0.1:8082/dataChange?tableName=equipment_info');
END;但是这样还有个问题。如果你数据经常变更就不要这样做,或者你一次变更变更好几条也不要,因为数据变更一条就发送一个http请求,程序更新一次。这样就会导致http请求接口变的非常慢,因为会有很多个请求同时过来,因为这个更新数据的接口本来就执行的慢(要查询数据,更新redis中的数据),你如果很多变更,会卡死程序,别我我为啥呜呜呜。
这边Oracle发送http请求会有个问题
创建或更新访问控制列表(ACL): 在Oracle数据库中,需要配置访问控制列表 (ACL),以允许数据库用户或角色访问外部网络资源。在这里,我们将创建一个新的 ACL。
BEGINDBMS_NETWORK_ACL_ADMIN.create_acl (acl => 'your_acl_name.xml',description => 'ACL for UTL_HTTP',principal => 'YOUR_DATABASE_USER', -- 替换为实际的数据库用户is_grant => TRUE,privilege => 'connect',start_date => NULL,end_date => NULL);DBMS_NETWORK_ACL_ADMIN.assign_acl (acl => 'your_acl_name.xml',host => '127.0.0.1', -- 替换为实际的目标主机lower_port => NULL,upper_port => NULL);COMMIT;
END;授权访问: 确保你的数据库用户拥有执行 UTL_HTTP 包中的过程和函数的权限。你可以使用以下命令为用户授权:
GRANT EXECUTE ON UTL_HTTP TO YOUR_DATABASE_USER; -- 替换为实际的数据库用户批量请求返回数据
最终方案
以上的做法虽然都是方案,但是都有一定缺点,而且是影响挺大的。后面想了想,既然一次性返回这么多数据会慢,那就批量返回。
让前端第一次发送这个查询接口的时候,请求1000条数据回去先展示后,接着马上又发请求请求10000条数据,如果返回的数据条数少于10000,就不要继续发了,反之继续发。这样用户就不会感受到慢,1000先给他看,后面的数据继续发。这样客户就是无感的,不会感受到慢。其实就是隐式分页。
有哪位看到这给指点,看有没有更好的方案。