最早做网站的那批人关键词搜索排名
本文主要目标是尝试去除水印,但是为了准备测试数据,我们需要先准备好有水印的pdf测试文件。
注意:本文的去水印只针对文字悬浮图片悬浮两种特殊情况,即使是这两种情况也不代表一定都可以去除水印。
文章目录
- 批量添加透明图片水印
- 批量去除悬浮图片水印
- 批量添加文字水印
- 批量去除文字水印
- 总结
批量添加透明图片水印
首先按照之前文章《Office三件套批量转PDF以及PDF书签读写与加水印》提供的方法,生成带水印的PDF,完整代码如下:
import PyPDF2
import math
from PIL import Image, ImageFont, ImageDraw, ImageEnhance, ImageChopsdef crop_image(im):'''裁剪图片边缘空白'''bg = Image.new(mode='RGBA', size=im.size)bbox = ImageChops.difference(im, bg).getbbox()if bbox:return im.crop(bbox)return imdef set_opacity(im, opacity):'''设置水印透明度'''assert 0 <= opacity <= 1alpha = im.split()[3]alpha = ImageEnhance.Brightness(alpha).enhance(opacity)im.putalpha(alpha)return imdef get_mark_img(text, color="#8B8B1B", size=30, opacity=0.15):width = len(text) * sizemark = Image.new(mode='RGBA', size=(width, size + 20))ImageDraw.Draw(im=mark) \.text(xy=(0, 0),text=text,fill=color,font=ImageFont.truetype('msyhbd.ttc', size=size))mark = crop_image(mark)set_opacity(mark, opacity)return markdef create_watermark_pdf(text, filename="watermark.pdf", page_size=(595, 842), color="#8B8B1B", size=30, opacity=0.3,space=75, angle=30, dpi=100):mark = get_mark_img(text, color, size, opacity)img_size = tuple(map(lambda s: int(s*dpi//72), page_size))im = Image.new(mode='RGBA', size=img_size)w, h = img_sizec = int(math.sqrt(w ** 2 + h ** 2))mark2 = Image.new(mode='RGBA', size=(c, c))y, idx = 0, 0mark_w, mark_h = mark.sizewhile y < c:x = -int((mark_w + space) * 0.5 * idx)idx = (idx + 1) % 2while x < c:mark2.paste(mark, (x, y))x = x + mark_w + spacey = y + mark_h + spacemark2 = mark2.rotate(angle)im.paste(mark2, (int((w - c) / 2), int((h - c) / 2)), # 坐标mask=mark2.split()[3])im.save(filename, "PDF", resolution=dpi, save_all=True)def pdf_add_watermark(filename, save_filepath, watermark='watermark.pdf'):watermark = PyPDF2.PdfReader(watermark).pages[0]pdf_reader = PyPDF2.PdfReader(filename)pdf_writer = PyPDF2.PdfWriter()for page in pdf_reader.pages:page.merge_page(watermark)page.compress_content_streams()pdf_writer.add_page(page)with open(save_filepath, "wb") as out:pdf_writer.write(out)if __name__ == '__main__':watermark = 'watermark.pdf'create_watermark_pdf("小小明的CSDN:https://blog.csdn.net/as604049322", watermark, opacity=0.4)pdf_add_watermark('mysql.pdf', 'mysql【带水印】.pdf', watermark=watermark)
然后就可以得到一个全部是水印的PDF文件:

批量去除悬浮图片水印
对于这类水印,去除起来并不难,只需要批量删除最后一个图像图层即可。
import PyPDF2writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader('mysql【带水印】.pdf')
for page in reader.pages:obj = page.get("/Resources").get("/XObject")obj.pop(list(obj)[-1])page[PyPDF2.generic.NameObject("/Resources")][PyPDF2.generic.NameObject("/XObject")] = objwriter.add_page(page)output_path = "mysql【去水印】.pdf"
with open(output_path, "wb") as output_file:writer.write(output_file)
对于上面方法生成的水印,已经迅速一键去除。
当然水印图床可能实际并不在最后一层,这就需要调试测试,找到水印对应的层进行删除。
例如我需要查看第5页每个图片对象,可以使用jupyter执行如下代码:
from PIL import Image
import ioreader = PyPDF2.PdfReader('mysql【带水印】.pdf')
page = reader.pages[5]
print(page.get("/Resources").get("/XObject"))
for i, img in enumerate(page.images):img_data = Image.open(io.BytesIO(img.data))print(i, img)display(img_data)
对于一些特殊的PDF有助于找到水印图层的规律,进而批量删除水印。
一般情况下,水印都是最后添加的,所以上面的代码直接删除最后一个图层没啥问题。有时我们会遇到一些特殊的多图层pdf,PyPDF2并不能良好的支持,即使原封不动复制,也会报错。
我们需要改造一下处理函数:
import PyPDF2def remove_image_watermark(input_pdf, output_path):writer = PyPDF2.PdfWriter()reader = PyPDF2.PdfReader(input_pdf)for page in reader.pages:obj = page.get("/Resources").get("/XObject")new_obj = PyPDF2.generic.DictionaryObject()obj.pop(list(obj)[-1])for k in obj:value = obj[PyPDF2.generic.NameObject(k)]if value is None:continuenew_obj[PyPDF2.generic.NameObject(k)] = valuepage[PyPDF2.generic.NameObject("/Resources")][PyPDF2.generic.NameObject("/XObject")] = new_objwriter.add_page(page)with open(output_path, "wb") as output_file:writer.write(output_file)input_pdf = "example2.pdf"
output_path = "example2【去水印】.pdf"
remove_image_watermark(input_pdf, output_path)
但这样也会不断出现异常日志,例如:Object 2763 0 not defined.,而且读取速度非常慢,一个100多页的PDF4分钟才处理完成。
这时,我们可以修改PyPDF2库的源码,修改库根目标的_reader.py文件的get_object函数:

表示在两个条件都不满足时,直接返回None,不再执行后面的读取和正则查找。因为对于本身不存在的对象,执行这样复杂的读取查找只是纯粹浪费时间。
经过上述修改后,再次执行代码,在1秒内处理完毕。
批量添加文字水印
不管是添加文字水印还是图片水印,我们都需要相应的水印PDF与需要添加水印的pdf进行图层合并。
首先我们需要生成文字水印PDF:
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import mathpagesize = (595, 842)
watermark = 'watermark.pdf'
space = 120
angle = 30pdfmetrics.registerFont(TTFont('msyhbd', 'msyhbd.ttc'))
mark = canvas.Canvas(watermark, pagesize=pagesize)
w, h = pagesize
c = int(math.sqrt(w**2+h**2))
mark.rotate(angle)
mark.setFont('msyhbd', 20)
mark.setFillColor("#8B8B1B")
mark.setFillAlpha(0.4)
for i, y in enumerate(range(-int(math.sin(math.radians(angle))*w-40), int(math.cos(math.radians(angle))*h-40), space)):mark.drawString(20+y*w/c+(w/2 if i%2==1 else 0), y, '小小明的CSDN:https://blog.csdn.net/as604049322')
mark.save()
注意:若缺少reportlab库,可以通过
pip install reportlab安装。
然后整理一下代码,生成带有文字水印的PDF,最终完整代码为:
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import PyPDF2
import mathdef create_text_watermark_pdf(text, watermark, pagesize=(595, 842), color="#8B8B1B", font_size=20,opacity=0.3, space=150, angle=30, font='msyhbd.ttc'):pdfmetrics.registerFont(TTFont('font', font))mark = canvas.Canvas(watermark, pagesize=pagesize)w, h = pagesizec = int(math.sqrt(w**2+h**2))mark.rotate(angle)mark.setFont('font', font_size)mark.setFillColor(color)mark.setFillAlpha(opacity)for i, y in enumerate(range(-int(math.sin(math.radians(angle))*w-40), int(math.cos(math.radians(angle))*h-40), space)):mark.drawString(20+y*w/c+(w/2 if i % 2 == 1 else 0), y, text)mark.save()def pdf_add_watermark(filename, save_filepath, watermark='watermark.pdf'):watermark = PyPDF2.PdfReader(watermark).pages[0]pdf_reader = PyPDF2.PdfReader(filename)pdf_writer = PyPDF2.PdfWriter()for page in pdf_reader.pages:page.merge_page(watermark)page.compress_content_streams()pdf_writer.add_page(page)with open(save_filepath, "wb") as out:pdf_writer.write(out)if __name__ == '__main__':watermark = 'watermark.pdf'create_text_watermark_pdf("小小明的CSDN:https://blog.csdn.net/as604049322", watermark, opacity=0.3, angle=30)filename = 'mysql.pdf'save_filepath = 'mysql【带水印】.pdf'pdf_add_watermark(filename, save_filepath, watermark=watermark)

可以很清楚的看到文字水印相对图片文字的好处在于,文字链接可以直接点击访问。
批量去除文字水印
问题来了,对于这种悬浮的文字水印,能否批量去除呢?
首先我们观察一下添加水印前后,page对象的主要变化:
import PyPDF2print(PyPDF2.PdfReader("mysql.pdf").pages[0])
print(PyPDF2.PdfReader("mysql【带水印】.pdf").pages[0])
结果示例:
{'/Type': '/Page', '/Parent': IndirectObject(2, 0, 2016175275936), '/Resources': {'/Font': {'/F1': IndirectObject(5, 0, 2016175275936), '/F2': IndirectObject(9, 0, 2016175275936), '/F3': IndirectObject(11, 0, 2016175275936), '/F4': IndirectObject(16, 0, 2016175275936), '/F5': IndirectObject(21, 0, 2016175275936), '/F6': IndirectObject(26, 0, 2016175275936), '/F7': IndirectObject(28, 0, 2016175275936)}, '/ExtGState': {'/GS7': IndirectObject(7, 0, 2016175275936), '/GS8': IndirectObject(8, 0, 2016175275936)}, '/ProcSet': ['/PDF', '/Text', '/ImageB', '/ImageC', '/ImageI']}, '/MediaBox': [0, 0, 595.32, 841.92], '/Contents': IndirectObject(4, 0, 2016175275936), '/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'}, '/Tabs': '/S', '/StructParents': 0}
{'/Type': '/Page', '/Resources': {'/ExtGState': {'/GS7': IndirectObject(5, 0, 2016175272768), '/GS8': IndirectObject(6, 0, 2016175272768), '/gRLs0': {'/ca': 0.3}}, '/Font': {'/F1': IndirectObject(7, 0, 2016175272768), '/F2': IndirectObject(11, 0, 2016175272768), '/F3': IndirectObject(14, 0, 2016175272768), '/F4': IndirectObject(22, 0, 2016175272768), '/F5': IndirectObject(30, 0, 2016175272768), '/F6': IndirectObject(38, 0, 2016175272768), '/F7': IndirectObject(41, 0, 2016175272768), '/F12f89c5f3-0000-4658-b1ab-21ec73871408': {'/BaseFont': '/Helvetica', '/Encoding': '/WinAnsiEncoding', '/Name': '/F1', '/Subtype': '/Type1', '/Type': '/Font'}, '/F2+0': IndirectObject(45, 0, 2016175272768)}, '/ProcSet': ['/ImageC', '/Text', '/ImageB', '/PDF', '/ImageI']}, '/MediaBox': [0, 0, 595.32, 841.92], '/Contents': IndirectObject(49, 0, 2016175272768), '/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'}, '/Tabs': '/S', '/Annots': [], '/Parent': IndirectObject(1, 0, 2016175272768)}
可以看到主要变化在于水印PDF的page对象增加了'/Parent'节点。
针对这种情况,我们的批量去除水印代码为:
import PyPDF2pdf_path = "mysql【带水印】.pdf"
writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
for page in reader.pages:if '/Parent' in page:del page['/Parent']writer.add_page(page)
output_path = "mysql【去水印】.pdf"
with open(output_path, "wb") as output_file:writer.write(output_file)
结果发现并没有去除水印。
可以看到这个PDF,加水印前后,/Contents仅一个IndirectObject对象,正常对于普通的加过文字水印的PDF,/Contents往往都存在多个IndirectObject对象。执行如下代码进行进一步确认:
import PyPDF2reader = PyPDF2.PdfReader(r"mysql【带水印】.pdf")
page = reader.pages[0]
page_content = page.get_contents()
print(page_content.get_data())
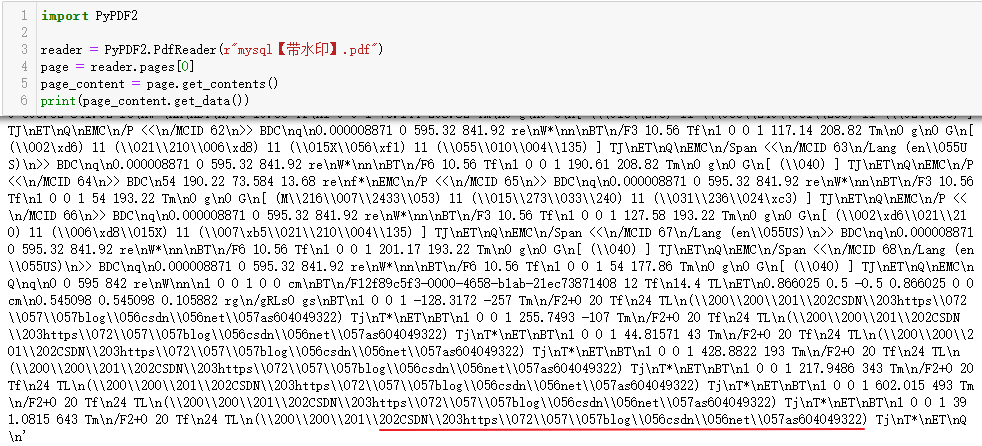
可以确认水印存在于这个对象中,预计主体内容和水印都被合并在了这一个内容对象里,这样我们就无法简单的通过删除/Contents内的某个对象达到删除水印的效果。
虽然我们自己生成的水印PDF无法轻易被删除,但最近我确实看到不少可以轻松删除文字水印的PDF。
例如这个PDF文件:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
reader = PyPDF2.PdfReader(pdf_path)
page = reader.pages[0]
page_content = page.get_contents()
print(page_content)
[IndirectObject(5, 0, 1288719316112), IndirectObject(6, 0, 1288719316112), IndirectObject(7, 0, 1288719316112), IndirectObject(8, 0, 1288719316112), IndirectObject(9, 0, 1288719316112)]
可以看到这一个PDF的第一页的内容对象存在5个对象,这样我们就可以挨个测试只要某个对象,得到的PDF是否满足要求,最终达到去除水印的目的。
首先我们将第一页的每个对象拆分成单独的一页:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
page = reader.pages[0]
page_contents = page.get_contents()
for page_content in page_contents:new_page_content = PyPDF2.generic.ArrayObject()new_page_content.append(page_content)page[PyPDF2.generic.NameObject("/Contents")] = new_page_contentwriter.add_page(page)
with open("第一页图层拆分.pdf", "wb") as f:writer.write(f)
然后我们人工检查第一页图层拆分.pdf这个文件,看哪几个图层才是我们需要的数据,目前我测试的这个文件只有第3页是我所需要的数据,那么我们可以批量只取第3个对象的内容:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
output_path = "工行结算卡流水【去水印】.pdf"writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
for page in reader.pages:new_page_content = PyPDF2.generic.ArrayObject()page_content = page.get_contents()new_page_content.append(page_content[2])page[PyPDF2.generic.NameObject("/Contents")] = new_page_contentwriter.add_page(page)
with open(output_path, "wb") as f:writer.write(f)
经检查工行结算卡流水.pdf中的水印在工行结算卡流水【去水印】.pdf文件中已经完全消除。
总结
我们可以给PDF加图片水印或文字水印,要去除图片水印,一般只需要删除最后一个图片对象即可。
要去除文字水印,需要保证主体内容和文字水印在/Contents中位于不同的对象内,这样我们只需要删除文字水印对应的IndirectObject对象即可删除水印。
而对于主体内容和文字水印已经混合在一个对象时,本文的提供的方法则无能为力,需要进一步深入分析PDF细节。