江阴市建设局网站济南公司网站推广优化最大的
1. Scrapy install
准备知识
- pip 包管理
- Python 安装
- Xpath
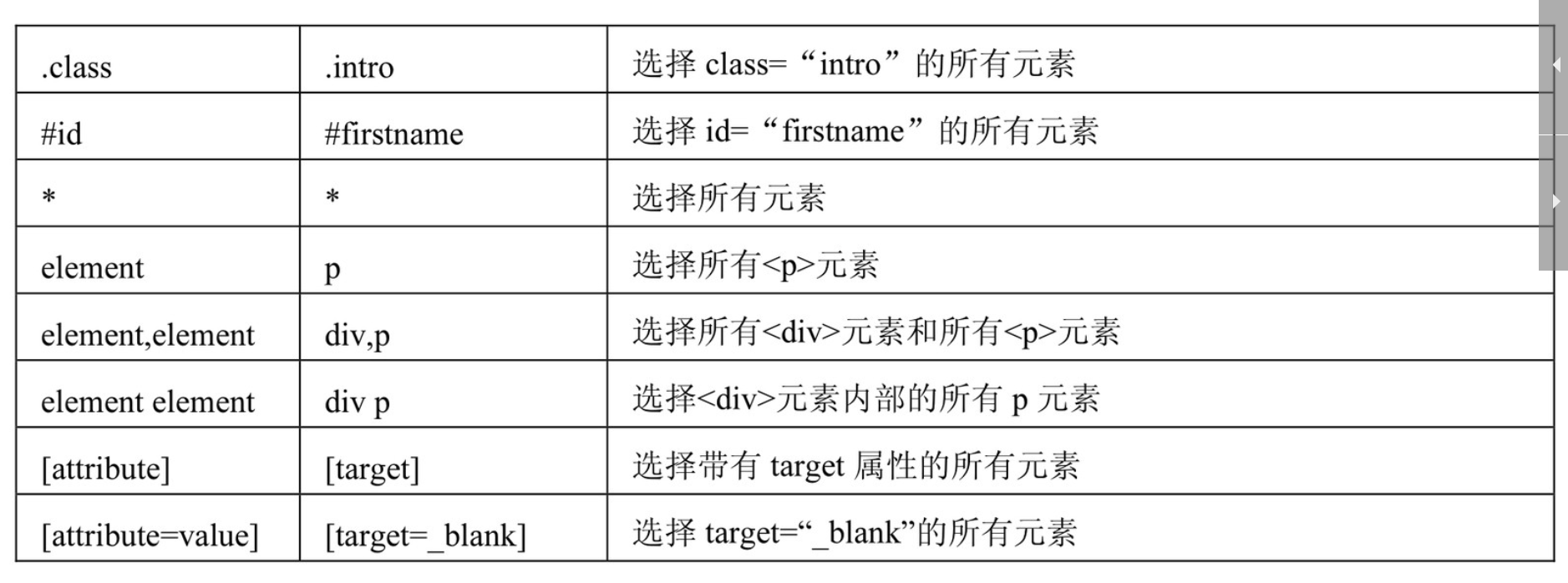
- Css
Windows安装 Scrapy
$>- pip install scrapy
Linux安装 Scrapy
$>- apt-get install python-scrapy
2. Scrapy 项目创建
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
$>- scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,使用命令查看目录结构
3. Scrapy 自定义爬虫类
通过Scrapy的Spider基础模版顺便建立一个基础的爬虫。(也可以不用Scrapy命令建立基础爬虫,)
$>- scrapy genspider gzrbSpider dayoo.com
scrapy genspider是一个命令,也是scrapy最常用的几个命令之一。至此,一个最基本的爬虫项目已经建立完毕了.
文件描述:
| 序列 | 文件名 | 描述 |
|---|---|---|
| 1 | scrapy.cfg | 是整个Scrapy项目的配置文件 |
| 2 | settings.py | 是上层目录中scrapy.cfg定义的设置文件(决定由谁去处理爬取的内容) |
| 3 | init.pyc | 是__init__.py的字节码文件 |
| 4 | init.py | 作用就是将它的上级目录变成了一个模块 ,否则,文件夹没有__init__.py不能作为模块导入 |
| 5 | items.py | 是定义爬虫最终需要哪些项 (决定爬取哪些项目) |
| 5 | pipelines.py | Scrapy爬虫爬取了网页中的内容后,这些内容怎么处理就取决于pipelines.py如何设置 (决定爬取后的内容怎样处理) |
| 6 | gzrbSpider.py | 自定义爬虫类(决定怎么爬) |
命令描述:
| 序列 | 操作 | 描述 |
|---|---|---|
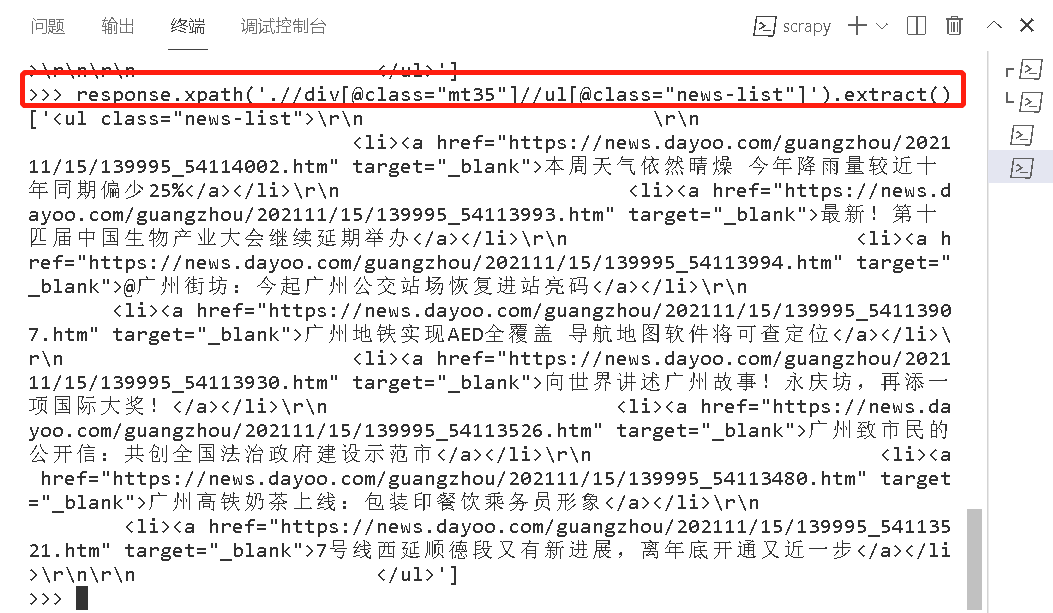
| 1 | 模拟爬广州日报网页 | scrapy shell https://www.dayoo.com |
| 2 | 模拟查看节点数据 | response.xpath('.//div[@class="mt35"]//ul[@class="news-list"]').extract()
|
| 3 | 运行爬虫 | scrapy crawl gzrbSpider |
4. Scrapy 处理逻辑
文件 \spiders\gzrbSpider.py
import scrapy
from mySpider.items import MySpiderItemclass gzrbSpider(scrapy.Spider):name = "gzrbSpider"allowed_domains = ["dayoo.com/"]start_urls = ('https://www.dayoo.com',)def parse(self, response):subSelector = response.xpath('.//div[@class="mt35"]//ul[@class="news-list"]')items = []for sub in subSelector:item = MySpiderItem()item['newName'] = sub.xpath('./li/a/text()').extract()items.append(item)return items
文件 Item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass MySpiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()newName = scrapy.Field()
文件 Setting.py
# Scrapy settings for mySpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'mySpider'SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'mySpider(+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'mySpider.middlewares.mySpiderSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'mySpider.middlewares.mySpiderDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'mySpider.pipelines.mySpiderPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
文件 pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import time# class mySpiderPipeline:
# def process_item(self, item, spider):
# return itemclass MySpiderPipeline(object):def process_item(self, item, spider):now = time.strftime('%Y-%m-%d', time.localtime())fileName = 'gzrb' + now + '.txt'for it in item['newName ']:with open(fileName,encoding='utf-8',mode = 'a') as fp:# fp.write(item['newName '][0].encode('utf8') + '\n\n')fp.write(it + '\n\n')return item本文代码结果展示:

5. Scrapy 扩展
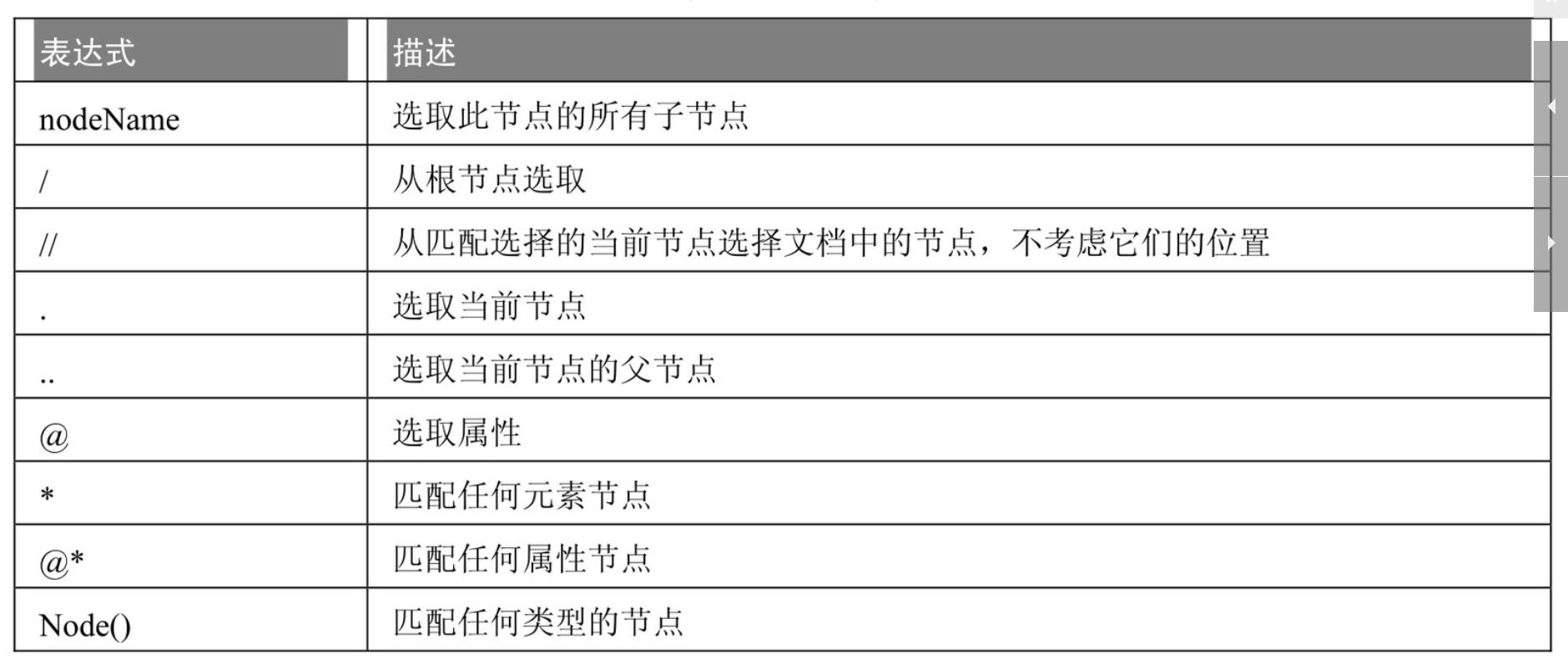
Xpath:
Css: