wap的网站模板下载做博客的seo技巧
论文链接:https://arxiv.org/abs/1807.06521
论文题目:CBAM: Convolutional Block Attention Module
会议:ECCV2018
论文方法
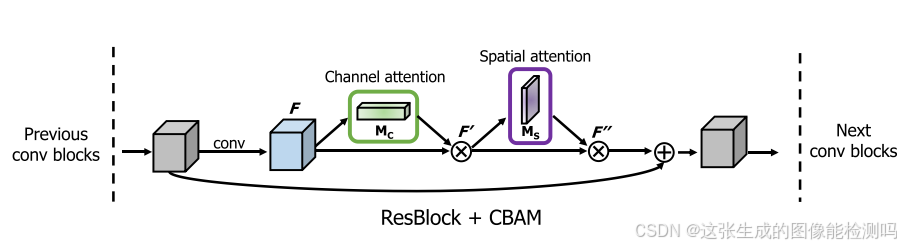
利用特征的通道间关系生成了一个通道注意图。 由于特征映射的每个通道被认为是一个特征检测器,通道注意力集中在给定输入图像的“什么”是有意义的。 为了有效地计算通道注意力,我们压缩了输入特征映射的空间维度。 对于空间信息的聚合,目前普遍采用平均池化方法。 除了之前的工作,我们认为最大池化收集了另一个关于不同对象特征的重要线索,以推断更精细的通道明智的注意力。 因此,作者同时使用平均池化和最大池化特征。
利用特征的空间间关系生成空间注意图。 与通道注意不同的是,空间注意关注的“在哪里”是信息部分,与通道注意是互补的。 为了计算空间注意力,首先沿着通道轴应用平均池化和最大池化操作,并将它们连接起来以生成有效的特征描述符。 沿着通道轴应用池操作可以有效地突出显示信息区域。 在连接的特征描述符上,应用卷积层生成空间注意映射Ms(F)∈RH×W,该映射编码强调或抑制的位置。

论文源代码
import torch
import torch.nn.functional as F
import torch.nn as nnclass ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),nn.ReLU(inplace=True),nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)) self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))out = avg_out + max_outout = self.sigmoid(out)return out * xclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.sigmoid(self.conv1(out))return out * xclass CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=3):super(CBAM, self).__init__()self.channelattention = ChannelAttention(in_channels, ratio=ratio)self.spatialattention = SpatialAttention(kernel_size=kernel_size)def forward(self, x):x = self.channelattention(x)x = self.spatialattention(x)return x
改进思路
1.通道注意力独立分支与批归一化
使用独立的FC层处理平均池化和最大池化,增强表达能力。
在FC层之间加入批归一化,加速训练收敛。
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)# 独立的全连接层分支self.fc_avg = nn.Sequential(nn.Conv2d(in_channels, in_channels//ratio, 1, bias=False),nn.BatchNorm2d(in_channels//ratio), # 添加BNnn.ReLU(inplace=True),nn.Conv2d(in_channels//ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels) # 输出层也可以考虑BN)self.fc_max = nn.Sequential(nn.Conv2d(in_channels, in_channels//ratio, 1, bias=False),nn.BatchNorm2d(in_channels//ratio),nn.ReLU(inplace=True),nn.Conv2d(in_channels//ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc_avg(self.avg_pool(x))max_out = self.fc_max(self.max_pool(x))out = self.sigmoid(avg_out + max_out)return x * out
2.空间注意力深度增强
使用多层卷积增加非线性。
引入残差连接提升梯度流动。
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()padding = kernel_size // 2self.conv = nn.Sequential(nn.Conv2d(2, 32, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Conv2d(32, 1, kernel_size, padding=padding, bias=False), # 深层卷积nn.BatchNorm2d(1))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)cat = torch.cat([avg_out, max_out], dim=1)out = self.conv(cat) + cat.mean(dim=1, keepdim=True) # 残差连接return x * self.sigmoid(out)3.动态比例调整、参数初始化优化、并行注意力融合
import torch
import torch.nn as nn
import torch.nn.functional as F# --------------------------
# 改进3:动态比例调整
# --------------------------
def get_ratio(in_channels, min_ratio=16):"""动态计算压缩比例,防止通道数过小时出现除零错误"""return max(in_channels // min_ratio, 4) # 保证最小分割比例为4# --------------------------
# 改进4:参数初始化优化
# --------------------------
def init_weights(m):"""He初始化 + 零偏置初始化"""if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# --------------------------
# 改进1/3:通道注意力(包含动态比例调整)
# --------------------------
class ChannelAttention(nn.Module):def __init__(self, in_channels):super().__init__()ratio = get_ratio(in_channels) # 动态计算ratioself.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_channels, ratio, 1, bias=False),nn.BatchNorm2d(ratio),nn.ReLU(),nn.Conv2d(ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels))self.sigmoid = nn.Sigmoid()self.apply(init_weights) # 应用参数初始化def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))weight = self.sigmoid(avg_out + max_out)return x * weight# --------------------------
# 改进1:空间注意力
# --------------------------
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()padding = kernel_size // 2self.conv = nn.Sequential(nn.Conv2d(2, 32, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 1, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(1))self.sigmoid = nn.Sigmoid()self.apply(init_weights) # 应用参数初始化def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)cat = torch.cat([avg_out, max_out], dim=1)weight = self.sigmoid(self.conv(cat))return x * weight# --------------------------
# 改进5:并行注意力融合
# --------------------------
class CBAM(nn.Module):def __init__(self, in_channels, kernel_size=7):super().__init__()self.ca = ChannelAttention(in_channels)self.sa = SpatialAttention(kernel_size)self.apply(init_weights) # 整个模块应用初始化def forward(self, x):# 并行计算通道注意力和空间注意力ca_out = self.ca(x) # 通道注意力分支sa_out = self.sa(x) # 空间注意力分支# 残差连接融合 (原始特征 + 通道特征 + 空间特征)return x + ca_out + sa_out